 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Minimization in Logit Space Efficiently Enhances Direct Preference Optimization
Mar 18, 2026Direct Preference Optimization (DPO) has emerged as a popular algorithm for aligning pretrained large language models with human preferences, owing to its simplicity and training stability. However, DPO suffers from the recently identified squeezing effect (also known as likelihood displacement), where the probability of preferred responses decreases unintentionally during training. To understand and mitigate this phenomenon, we develop a theoretical framework that models the coordinate-wise dynamics in logit space. Our analysis reveals that negative-gradient updates cause residuals to expand rapidly along high-curvature directions, which underlies the squeezing effect, whereas Sharpness-Aware Minimization (SAM) can suppress this behavior through its curvature-regularization effect. Building on this insight, we investigate logits-SAM, a computationally efficient variant that perturbs only the output layer with negligible overhead. Extensive experiments on Pythia-2.8B, Mistral-7B, and Gemma-2B-IT across multiple datasets and benchmarks demonstrate that logits-SAM consistently improves the effectiveness of DPO and integrates seamlessly with other DPO variants. Code is available at https://github.com/RitianLuo/logits-sam-dpo.
Antibody: Strengthening Defense Against Harmful Fine-Tuning for Large Language Models via Attenuating Harmful Gradient Influence
Feb 28, 2026Fine-tuning-as-a-service introduces a threat to Large Language Models' safety when service providers fine-tune their models on poisoned user-submitted datasets, a process known as harmful fine-tuning attacks. In this work, we show that by regularizing the gradient contribution of harmful samples encountered during fine-tuning, we can effectively mitigate the impact of harmful fine-tuning attacks. To this end, we introduce Antibody, a defense strategy that first ensures robust safety alignment for the model before fine-tuning, and then applies a safety-preservation learning algorithm during fine-tuning. Specifically, in the alignment stage before fine-tuning, we propose optimizing the model to be in a flat loss region with respect to harmful samples, which makes the safety alignment more resilient to subsequent harmful fine-tuning. Then, in the fine-tuning stage, we design a fine-tuning algorithm that applies a weighting scheme to all samples in each training batch to inhibit the model from learning from harmful samples while encouraging learning from benign samples. Experimental results demonstrate that Antibody successfully mitigates harmful fine-tuning attacks while boosting fine-tuning performance on the user-submitted dataset.
Segment Any Tumour: An Uncertainty-Aware Vision Foundation Model for Whole-Body Analysis
Nov 11, 2025Prompt-driven vision foundation models, such as the Segment Anything Model, have recently demonstrated remarkable adaptability in computer vision. However, their direct application to medical imaging remains challenging due to heterogeneous tissue structures, imaging artefacts, and low-contrast boundaries, particularly in tumours and cancer primaries leading to suboptimal segmentation in ambiguous or overlapping lesion regions. Here, we present Segment Any Tumour 3D (SAT3D), a lightweight volumetric foundation model designed to enable robust and generalisable tumour segmentation across diverse medical imaging modalities. SAT3D integrates a shifted-window vision transformer for hierarchical volumetric representation with an uncertainty-aware training pipeline that explicitly incorporates uncertainty estimates as prompts to guide reliable boundary prediction in low-contrast regions. Adversarial learning further enhances model performance for the ambiguous pathological regions. We benchmark SAT3D against three recent vision foundation models and nnUNet across 11 publicly available datasets, encompassing 3,884 tumour and cancer cases for training and 694 cases for in-distribution evaluation. Trained on 17,075 3D volume-mask pairs across multiple modalities and cancer primaries, SAT3D demonstrates strong generalisation and robustness. To facilitate practical use and clinical translation, we developed a 3D Slicer plugin that enables interactive, prompt-driven segmentation and visualisation using the trained SAT3D model. Extensive experiments highlight its effectiveness in improving segmentation accuracy under challenging and out-of-distribution scenarios, underscoring its potential as a scalable foundation model for medical image analysis.
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025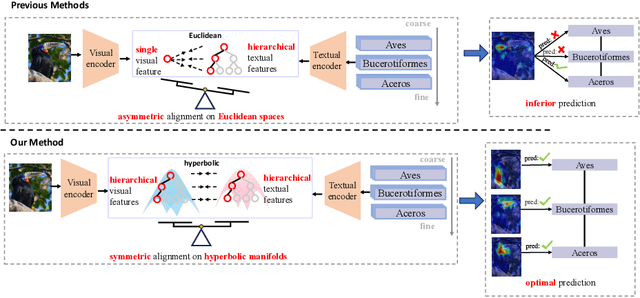
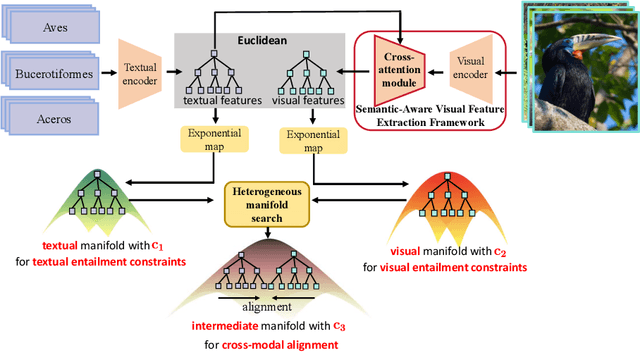

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
Curvature Learning for Generalization of Hyperbolic Neural Networks
Aug 24, 2025Hyperbolic neural networks (HNNs) have demonstrated notable efficacy in representing real-world data with hierarchical structures via exploiting the geometric properties of hyperbolic spaces characterized by negative curvatures. Curvature plays a crucial role in optimizing HNNs. Inappropriate curvatures may cause HNNs to converge to suboptimal parameters, degrading overall performance. So far, the theoretical foundation of the effect of curvatures on HNNs has not been developed. In this paper, we derive a PAC-Bayesian generalization bound of HNNs, highlighting the role of curvatures in the generalization of HNNs via their effect on the smoothness of the loss landscape. Driven by the derived bound, we propose a sharpness-aware curvature learning method to smooth the loss landscape, thereby improving the generalization of HNNs. In our method, we design a scope sharpness measure for curvatures, which is minimized through a bi-level optimization process. Then, we introduce an implicit differentiation algorithm that efficiently solves the bi-level optimization by approximating gradients of curvatures. We present the approximation error and convergence analyses of the proposed method, showing that the approximation error is upper-bounded, and the proposed method can converge by bounding gradients of HNNs. Experiments on four settings: classification, learning from long-tailed data, learning from noisy data, and few-shot learning show that our method can improve the performance of HNNs.
Unleashing Diffusion Transformers for Visual Correspondence by Modulating Massive Activations
May 24, 2025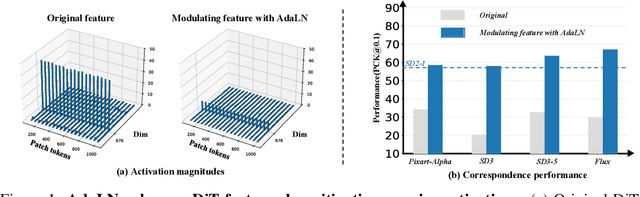
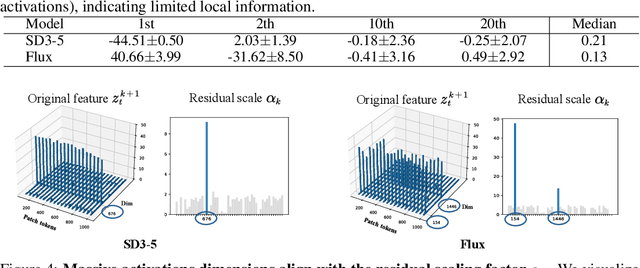
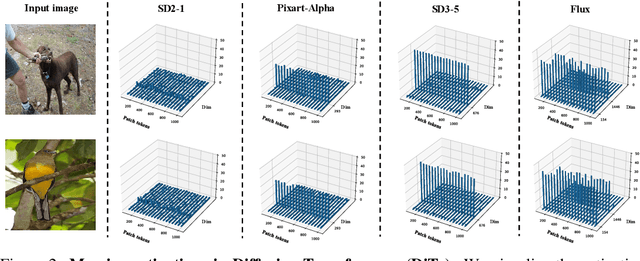
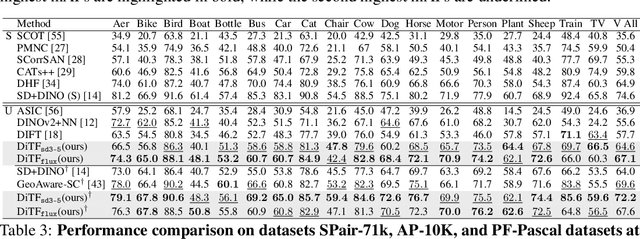
Pre-trained stable diffusion models (SD) have shown great advances in visual correspondence. In this paper, we investigate the capabilities of Diffusion Transformers (DiTs) for accurate dense correspondence. Distinct from SD, DiTs exhibit a critical phenomenon in which very few feature activations exhibit significantly larger values than others, known as \textit{massive activations}, leading to uninformative representations and significant performance degradation for DiTs. The massive activations consistently concentrate at very few fixed dimensions across all image patch tokens, holding little local information. We trace these dimension-concentrated massive activations and find that such concentration can be effectively localized by the zero-initialized Adaptive Layer Norm (AdaLN-zero). Building on these findings, we propose Diffusion Transformer Feature (DiTF), a training-free framework designed to extract semantic-discriminative features from DiTs. Specifically, DiTF employs AdaLN to adaptively localize and normalize massive activations with channel-wise modulation. In addition, we develop a channel discard strategy to further eliminate the negative impacts from massive activations. Experimental results demonstrate that our DiTF outperforms both DINO and SD-based models and establishes a new state-of-the-art performance for DiTs in different visual correspondence tasks (\eg, with +9.4\% on Spair-71k and +4.4\% on AP-10K-C.S.).
Exemplar-Free Continual Learning for State Space Models
May 24, 2025State-Space Models (SSMs) excel at capturing long-range dependencies with structured recurrence, making them well-suited for sequence modeling. However, their evolving internal states pose challenges in adapting them under Continual Learning (CL). This is particularly difficult in exemplar-free settings, where the absence of prior data leaves updates to the dynamic SSM states unconstrained, resulting in catastrophic forgetting. To address this, we propose Inf-SSM, a novel and simple geometry-aware regularization method that utilizes the geometry of the infinite-dimensional Grassmannian to constrain state evolution during CL. Unlike classical continual learning methods that constrain weight updates, Inf-SSM regularizes the infinite-horizon evolution of SSMs encoded in their extended observability subspace. We show that enforcing this regularization requires solving a matrix equation known as the Sylvester equation, which typically incurs $\mathcal{O}(n^3)$ complexity. We develop a $\mathcal{O}(n^2)$ solution by exploiting the structure and properties of SSMs. This leads to an efficient regularization mechanism that can be seamlessly integrated into existing CL methods. Comprehensive experiments on challenging benchmarks, including ImageNet-R and Caltech-256, demonstrate a significant reduction in forgetting while improving accuracy across sequential tasks.
MoKD: Multi-Task Optimization for Knowledge Distillation
May 13, 2025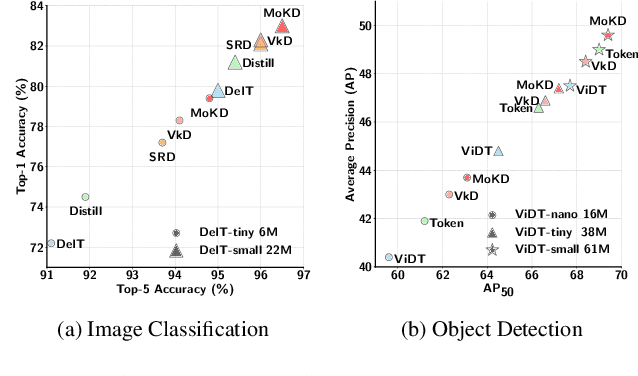
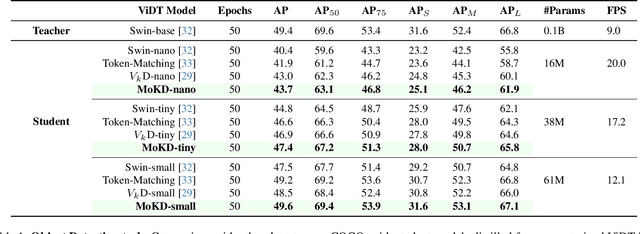
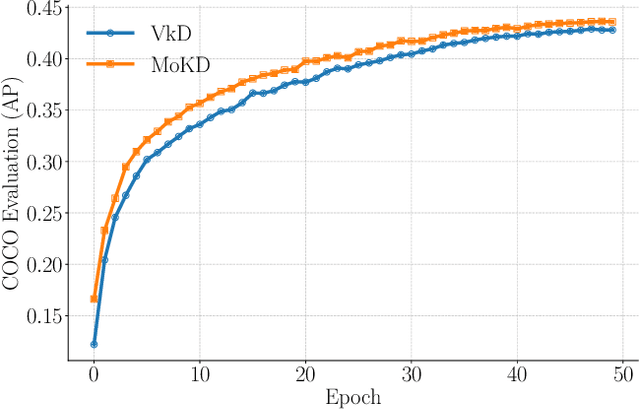
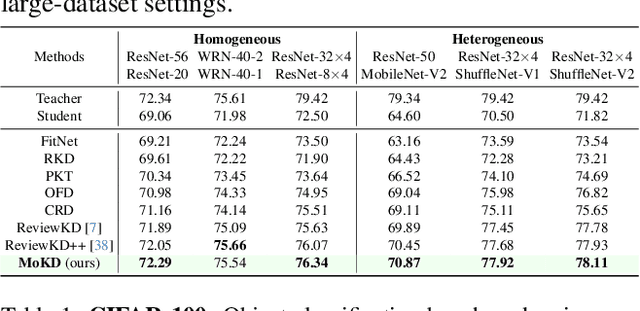
Compact models can be effectively trained through Knowledge Distillation (KD), a technique that transfers knowledge from larger, high-performing teacher models. Two key challenges in Knowledge Distillation (KD) are: 1) balancing learning from the teacher's guidance and the task objective, and 2) handling the disparity in knowledge representation between teacher and student models. To address these, we propose Multi-Task Optimization for Knowledge Distillation (MoKD). MoKD tackles two main gradient issues: a) Gradient Conflicts, where task-specific and distillation gradients are misaligned, and b) Gradient Dominance, where one objective's gradient dominates, causing imbalance. MoKD reformulates KD as a multi-objective optimization problem, enabling better balance between objectives. Additionally, it introduces a subspace learning framework to project feature representations into a high-dimensional space, improving knowledge transfer. Our MoKD is demonstrated to outperform existing methods through extensive experiments on image classification using the ImageNet-1K dataset and object detection using the COCO dataset, achieving state-of-the-art performance with greater efficiency. To the best of our knowledge, MoKD models also achieve state-of-the-art performance compared to models trained from scratch.
Optimizing Specific and Shared Parameters for Efficient Parameter Tuning
Apr 04, 2025Foundation models, with a vast number of parameters and pretraining on massive datasets, achieve state-of-the-art performance across various applications. However, efficiently adapting them to downstream tasks with minimal computational overhead remains a challenge. Parameter-Efficient Transfer Learning (PETL) addresses this by fine-tuning only a small subset of parameters while preserving pre-trained knowledge. In this paper, we propose SaS, a novel PETL method that effectively mitigates distributional shifts during fine-tuning. SaS integrates (1) a shared module that captures common statistical characteristics across layers using low-rank projections and (2) a layer-specific module that employs hypernetworks to generate tailored parameters for each layer. This dual design ensures an optimal balance between performance and parameter efficiency while introducing less than 0.05% additional parameters, making it significantly more compact than existing methods. Extensive experiments on diverse downstream tasks, few-shot settings and domain generalization demonstrate that SaS significantly enhances performance while maintaining superior parameter efficiency compared to existing methods, highlighting the importance of capturing both shared and layer-specific information in transfer learning. Code and data are available at https://anonymous.4open.science/r/SaS-PETL-3565.
PCGS: Progressive Compression of 3D Gaussian Splatting
Mar 11, 2025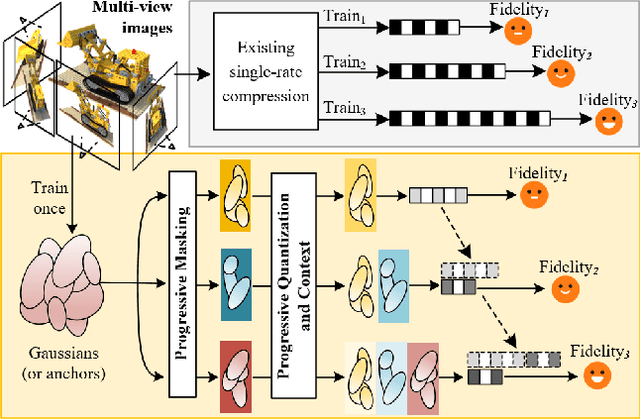
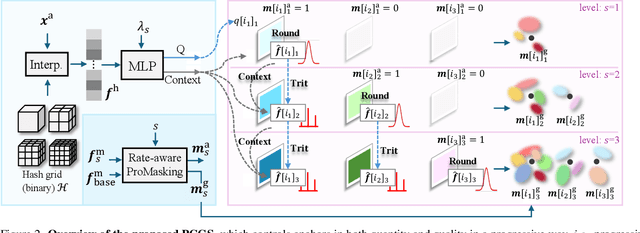
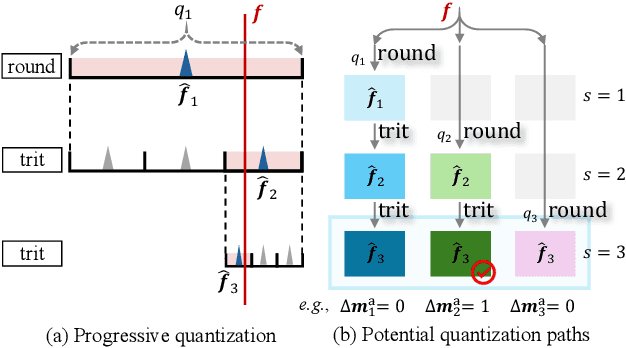
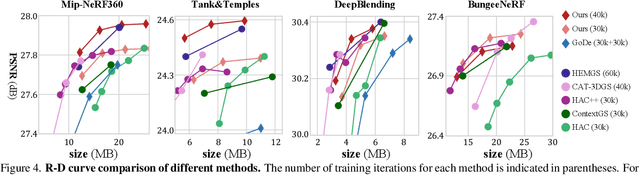
3D Gaussian Splatting (3DGS) achieves impressive rendering fidelity and speed for novel view synthesis. However, its substantial data size poses a significant challenge for practical applications. While many compression techniques have been proposed, they fail to efficiently utilize existing bitstreams in on-demand applications due to their lack of progressivity, leading to a waste of resource. To address this issue, we propose PCGS (Progressive Compression of 3D Gaussian Splatting), which adaptively controls both the quantity and quality of Gaussians (or anchors) to enable effective progressivity for on-demand applications. Specifically, for quantity, we introduce a progressive masking strategy that incrementally incorporates new anchors while refining existing ones to enhance fidelity. For quality, we propose a progressive quantization approach that gradually reduces quantization step sizes to achieve finer modeling of Gaussian attributes. Furthermore, to compact the incremental bitstreams, we leverage existing quantization results to refine probability prediction, improving entropy coding efficiency across progressive levels. Overall, PCGS achieves progressivity while maintaining compression performance comparable to SoTA non-progressive methods. Code available at: github.com/YihangChen-ee/PCGS.