 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteerSeg: Attention Steering for Reasoning Video Segmentation
May 14, 2026Video reasoning segmentation requires localizing objects across video frames from natural language expressions, often involving spatial reasoning and implicit references. Recent approaches leverage frozen large vision-language models (LVLMs) by extracting attention maps and using them as spatial priors for segmentation, enabling training-free grounding. However, these attention maps are optimized for text generation rather than spatial localization, often resulting in diffuse and ambiguous grounding signals. In this work, we introduce SteerSeg, a lightweight framework that identifies attention misalignment as the key bottleneck in attention-based grounding and proposes to steer attention at its source through input-level conditioning. SteerSeg combines learnable soft prompts with reasoning-guided Chain-of-Thought (CoT) prompting. The soft prompts reshape the attention distribution to produce more spatially concentrated maps, while CoT-derived attributes resolve ambiguity among similar objects by guiding attention toward the correct instance. The resulting attention maps are converted into point prompts across keyframes to guide a segmentation model, while candidate tracklets are ranked and selected using correlation-based scoring. Our approach freezes the LVLM and segmentation model parameters and learns only a small set of soft prompts, preserving the model's pretrained reasoning capabilities while significantly improving grounding. Despite being trained only on Ref-YouTube-VOS, SteerSeg generalizes well across diverse benchmarks, significantly improving the spatial grounding capability of LVLMs. Project page: https://steerseg.github.io
Fighting Hallucinations with Counterfactuals: Diffusion-Guided Perturbations for LVLM Hallucination Suppression
Mar 11, 2026While large vision-language models (LVLMs) achieve strong performance on multimodal tasks, they frequently generate hallucinations -- unfaithful outputs misaligned with the visual input. To address this issue, we introduce CIPHER (Counterfactual Image Perturbations for Hallucination Extraction and Removal), a training-free method that suppresses vision-induced hallucinations via lightweight feature-level correction. Unlike prior training-free approaches that primarily focus on text-induced hallucinations, CIPHER explicitly targets hallucinations arising from the visual modality. CIPHER operates in two phases. In the offline phase, we construct OHC-25K (Object-Hallucinated Counterfactuals, 25,000 samples), a counterfactual dataset consisting of diffusion-edited images that intentionally contradict the original ground-truth captions. We pair these edited images with the unchanged ground-truth captions and process them through an LVLM to extract hallucination-related representations. Contrasting these representations with those from authentic (image, caption) pairs reveals structured, systematic shifts spanning a low-rank subspace characterizing vision-induced hallucination. In the inference phase, CIPHER suppresses hallucinations by projecting intermediate hidden states away from this subspace. Experiments across multiple benchmarks show that CIPHER significantly reduces hallucination rates while preserving task performance, demonstrating the effectiveness of counterfactual visual perturbations for improving LVLM faithfulness. Code and additional materials are available at https://hamidreza-dastmalchi.github.io/cipher-cvpr2026/.
Adapt-As-You-Walk Through the Clouds: Training-Free Online Test-Time Adaptation of 3D Vision-Language Foundation Models
Nov 19, 2025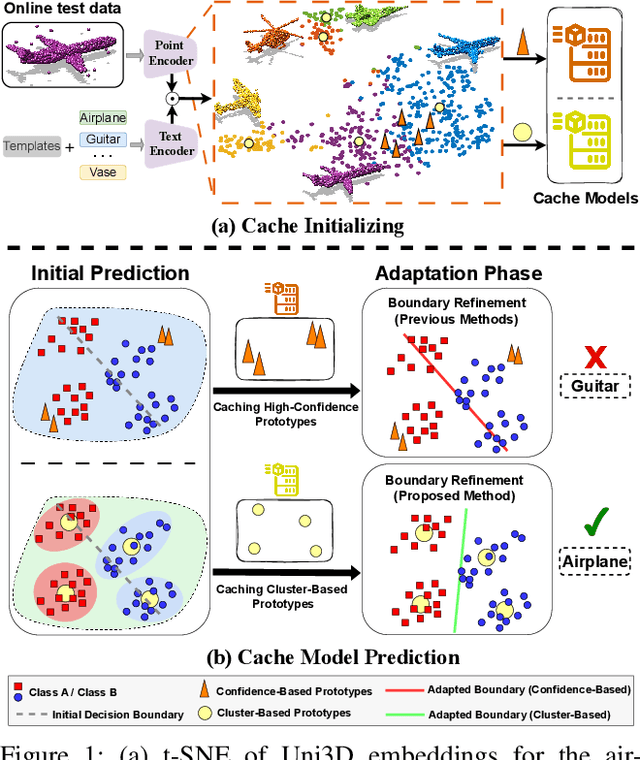
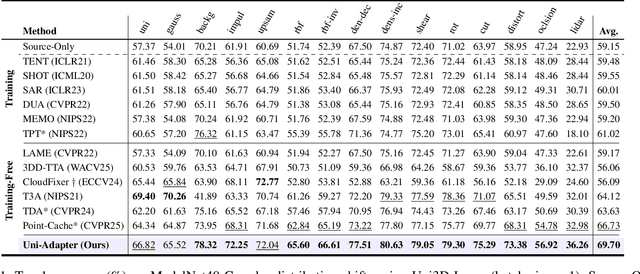
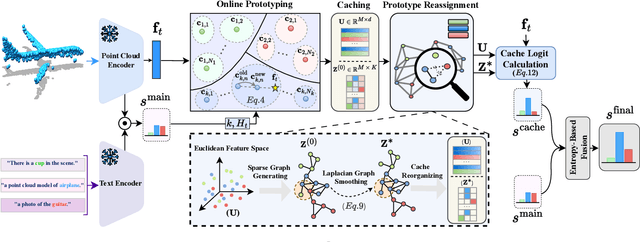
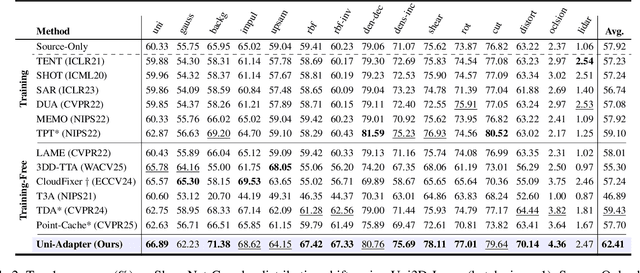
3D Vision-Language Foundation Models (VLFMs) have shown strong generalization and zero-shot recognition capabilities in open-world point cloud processing tasks. However, these models often underperform in practical scenarios where data are noisy, incomplete, or drawn from a different distribution than the training data. To address this, we propose Uni-Adapter, a novel training-free online test-time adaptation (TTA) strategy for 3D VLFMs based on dynamic prototype learning. We define a 3D cache to store class-specific cluster centers as prototypes, which are continuously updated to capture intra-class variability in heterogeneous data distributions. These dynamic prototypes serve as anchors for cache-based logit computation via similarity scoring. Simultaneously, a graph-based label smoothing module captures inter-prototype similarities to enforce label consistency among similar prototypes. Finally, we unify predictions from the original 3D VLFM and the refined 3D cache using entropy-weighted aggregation for reliable adaptation. Without retraining, Uni-Adapter effectively mitigates distribution shifts, achieving state-of-the-art performance on diverse 3D benchmarks over different 3D VLFMs, improving ModelNet-40C by 10.55%, ScanObjectNN-C by 8.26%, and ShapeNet-C by 4.49% over the source 3D VLFMs.
MoKD: Multi-Task Optimization for Knowledge Distillation
May 13, 2025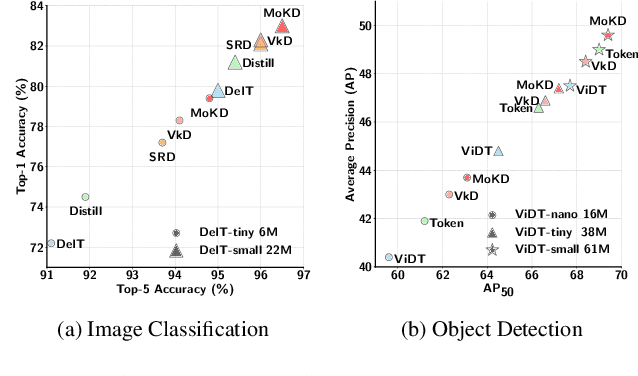
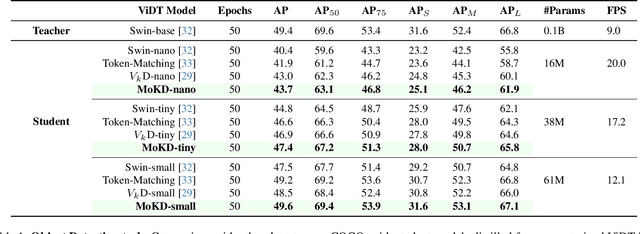
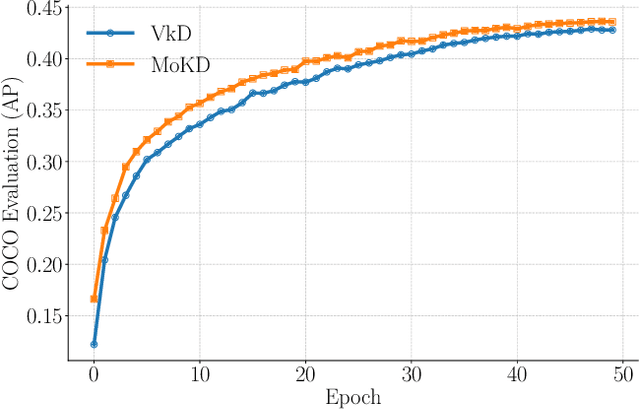
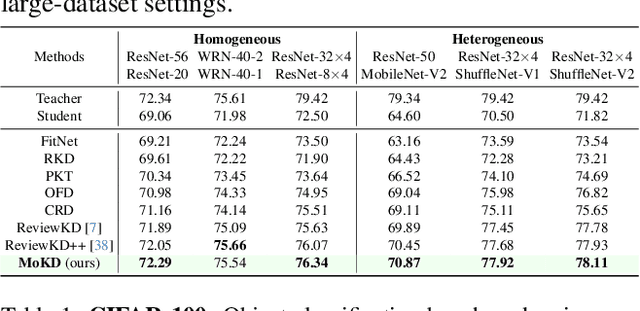
Compact models can be effectively trained through Knowledge Distillation (KD), a technique that transfers knowledge from larger, high-performing teacher models. Two key challenges in Knowledge Distillation (KD) are: 1) balancing learning from the teacher's guidance and the task objective, and 2) handling the disparity in knowledge representation between teacher and student models. To address these, we propose Multi-Task Optimization for Knowledge Distillation (MoKD). MoKD tackles two main gradient issues: a) Gradient Conflicts, where task-specific and distillation gradients are misaligned, and b) Gradient Dominance, where one objective's gradient dominates, causing imbalance. MoKD reformulates KD as a multi-objective optimization problem, enabling better balance between objectives. Additionally, it introduces a subspace learning framework to project feature representations into a high-dimensional space, improving knowledge transfer. Our MoKD is demonstrated to outperform existing methods through extensive experiments on image classification using the ImageNet-1K dataset and object detection using the COCO dataset, achieving state-of-the-art performance with greater efficiency. To the best of our knowledge, MoKD models also achieve state-of-the-art performance compared to models trained from scratch.
Task Progressive Curriculum Learning for Robust Visual Question Answering
Nov 26, 2024
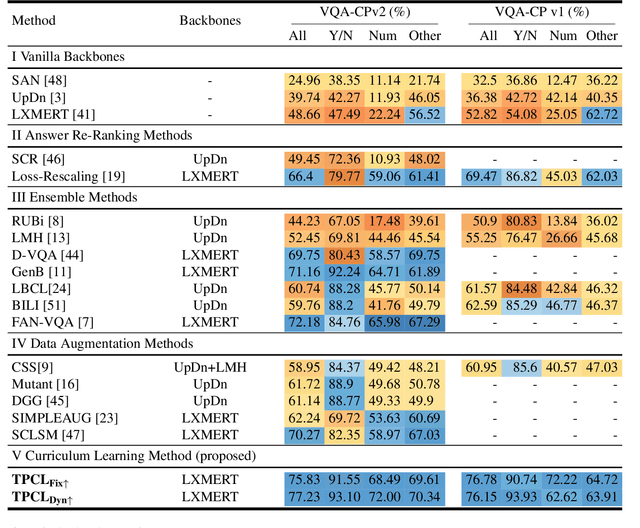
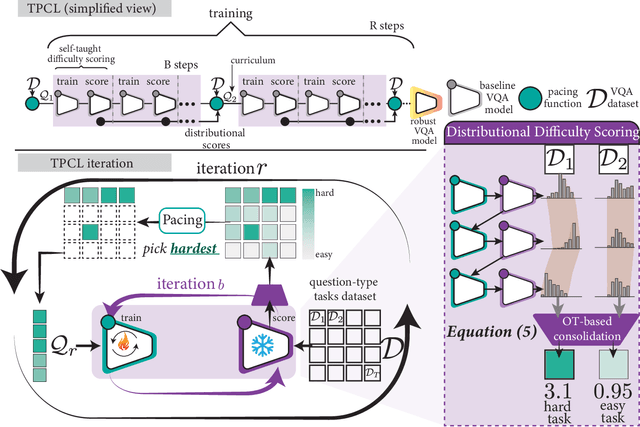
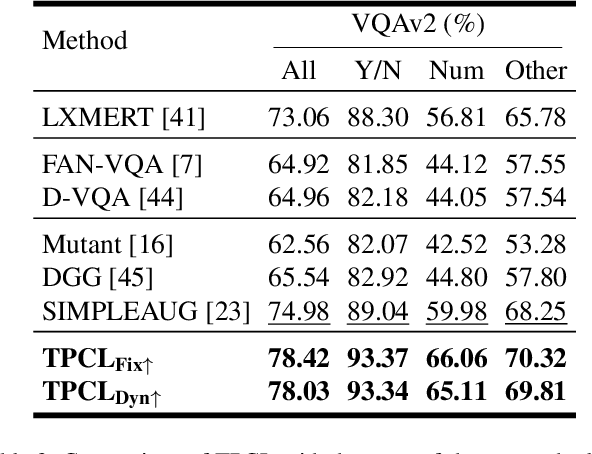
Visual Question Answering (VQA) systems are known for their poor performance in out-of-distribution datasets. An issue that was addressed in previous works through ensemble learning, answer re-ranking, or artificially growing the training set. In this work, we show for the first time that robust Visual Question Answering is attainable by simply enhancing the training strategy. Our proposed approach, Task Progressive Curriculum Learning (TPCL), breaks the main VQA problem into smaller, easier tasks based on the question type. Then, it progressively trains the model on a (carefully crafted) sequence of tasks. We further support the method by a novel distributional-based difficulty measurer. Our approach is conceptually simple, model-agnostic, and easy to implement. We demonstrate TPCL effectiveness through a comprehensive evaluation on standard datasets. Without either data augmentation or explicit debiasing mechanism, it achieves state-of-the-art on VQA-CP v2, VQA-CP v1 and VQA v2 datasets. Extensive experiments demonstrate that TPCL outperforms the most competitive robust VQA approaches by more than 5% and 7% on VQA-CP v2 and VQA-CP v1; respectively. TPCL also can boost VQA baseline backbone performance by up to 28.5%.
Test-Time Adaptation of 3D Point Clouds via Denoising Diffusion Models
Nov 21, 2024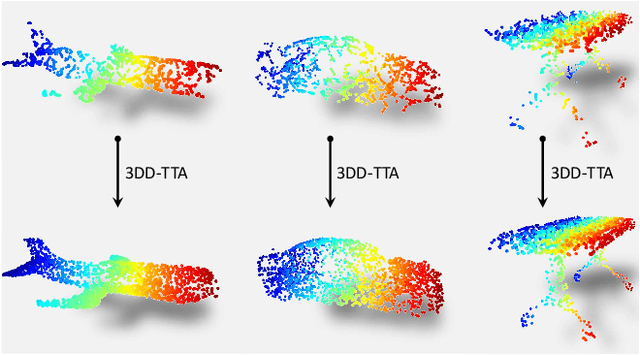
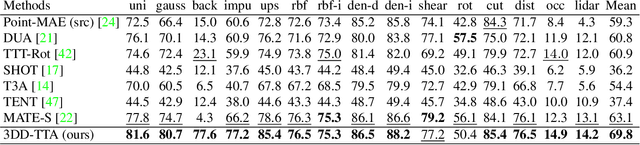
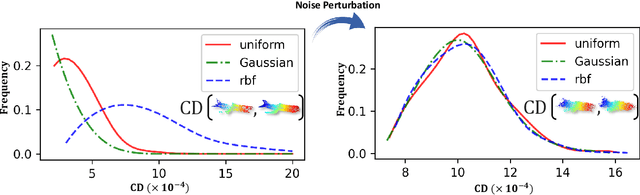
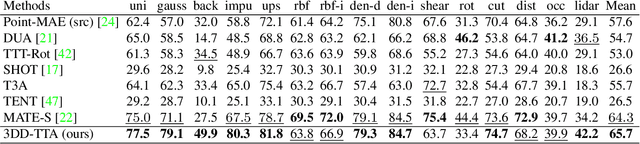
Test-time adaptation (TTA) of 3D point clouds is crucial for mitigating discrepancies between training and testing samples in real-world scenarios, particularly when handling corrupted point clouds. LiDAR data, for instance, can be affected by sensor failures or environmental factors, causing domain gaps. Adapting models to these distribution shifts online is crucial, as training for every possible variation is impractical. Existing methods often focus on fine-tuning pre-trained models based on self-supervised learning or pseudo-labeling, which can lead to forgetting valuable source domain knowledge over time and reduce generalization on future tests. In this paper, we introduce a novel 3D test-time adaptation method, termed 3DD-TTA, which stands for 3D Denoising Diffusion Test-Time Adaptation. This method uses a diffusion strategy that adapts input point cloud samples to the source domain while keeping the source model parameters intact. The approach uses a Variational Autoencoder (VAE) to encode the corrupted point cloud into a shape latent and latent points. These latent points are corrupted with Gaussian noise and subjected to a denoising diffusion process. During this process, both the shape latent and latent points are updated to preserve fidelity, guiding the denoising toward generating consistent samples that align more closely with the source domain. We conduct extensive experiments on the ShapeNet dataset and investigate its generalizability on ModelNet40 and ScanObjectNN, achieving state-of-the-art results. The code has been released at \url{https://github.com/hamidreza-dastmalchi/3DD-TTA}.
Foundation Model-Powered 3D Few-Shot Class Incremental Learning via Training-free Adaptor
Oct 11, 2024Recent advances in deep learning for processing point clouds hold increased interest in Few-Shot Class Incremental Learning (FSCIL) for 3D computer vision. This paper introduces a new method to tackle the Few-Shot Continual Incremental Learning (FSCIL) problem in 3D point cloud environments. We leverage a foundational 3D model trained extensively on point cloud data. Drawing from recent improvements in foundation models, known for their ability to work well across different tasks, we propose a novel strategy that does not require additional training to adapt to new tasks. Our approach uses a dual cache system: first, it uses previous test samples based on how confident the model was in its predictions to prevent forgetting, and second, it includes a small number of new task samples to prevent overfitting. This dynamic adaptation ensures strong performance across different learning tasks without needing lots of fine-tuning. We tested our approach on datasets like ModelNet, ShapeNet, ScanObjectNN, and CO3D, showing that it outperforms other FSCIL methods and demonstrating its effectiveness and versatility. The code is available at \url{https://github.com/ahmadisahar/ACCV_FCIL3D}.
3D Point Cloud Network Pruning: When Some Weights Do not Matter
Aug 26, 2024A point cloud is a crucial geometric data structure utilized in numerous applications. The adoption of deep neural networks referred to as Point Cloud Neural Networks (PC- NNs), for processing 3D point clouds, has significantly advanced fields that rely on 3D geometric data to enhance the efficiency of tasks. Expanding the size of both neural network models and 3D point clouds introduces significant challenges in minimizing computational and memory requirements. This is essential for meeting the demanding requirements of real-world applications, which prioritize minimal energy consumption and low latency. Therefore, investigating redundancy in PCNNs is crucial yet challenging due to their sensitivity to parameters. Additionally, traditional pruning methods face difficulties as these networks rely heavily on weights and points. Nonetheless, our research reveals a promising phenomenon that could refine standard PCNN pruning techniques. Our findings suggest that preserving only the top p% of the highest magnitude weights is crucial for accuracy preservation. For example, pruning 99% of the weights from the PointNet model still results in accuracy close to the base level. Specifically, in the ModelNet40 dataset, where the base accuracy with the PointNet model was 87. 5%, preserving only 1% of the weights still achieves an accuracy of 86.8%. Codes are available in: https://github.com/apurba-nsu-rnd-lab/PCNN_Pruning
Backpropagation-free Network for 3D Test-time Adaptation
Mar 27, 2024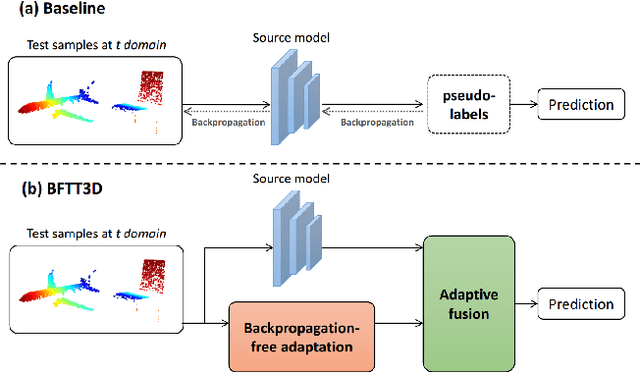
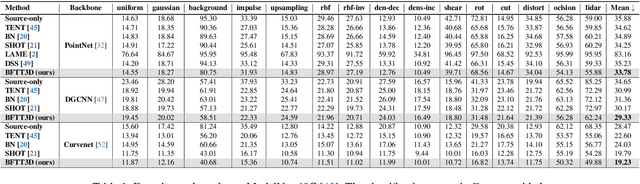
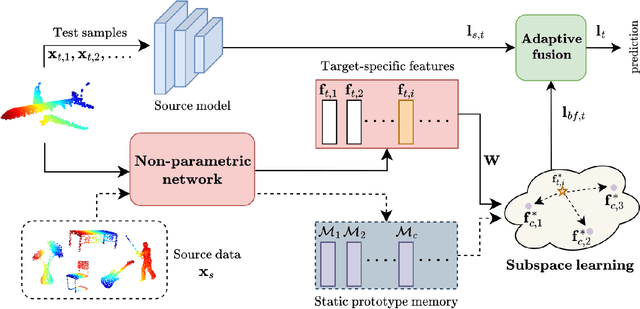
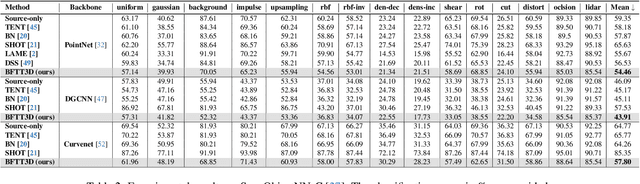
Real-world systems often encounter new data over time, which leads to experiencing target domain shifts. Existing Test-Time Adaptation (TTA) methods tend to apply computationally heavy and memory-intensive backpropagation-based approaches to handle this. Here, we propose a novel method that uses a backpropagation-free approach for TTA for the specific case of 3D data. Our model uses a two-stream architecture to maintain knowledge about the source domain as well as complementary target-domain-specific information. The backpropagation-free property of our model helps address the well-known forgetting problem and mitigates the error accumulation issue. The proposed method also eliminates the need for the usually noisy process of pseudo-labeling and reliance on costly self-supervised training. Moreover, our method leverages subspace learning, effectively reducing the distribution variance between the two domains. Furthermore, the source-domain-specific and the target-domain-specific streams are aligned using a novel entropy-based adaptive fusion strategy. Extensive experiments on popular benchmarks demonstrate the effectiveness of our method. The code will be available at https://github.com/abie-e/BFTT3D.
ChatGPT-guided Semantics for Zero-shot Learning
Oct 18, 2023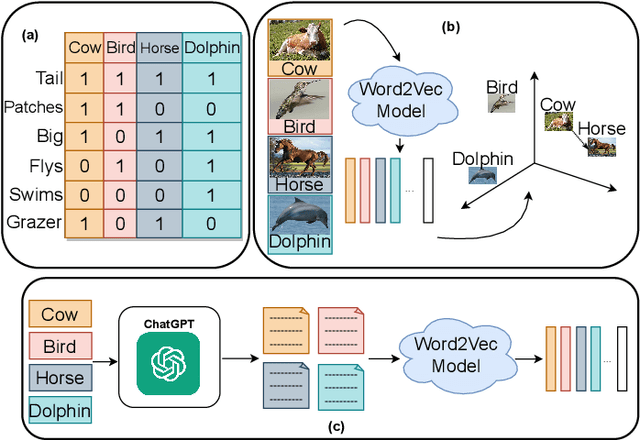
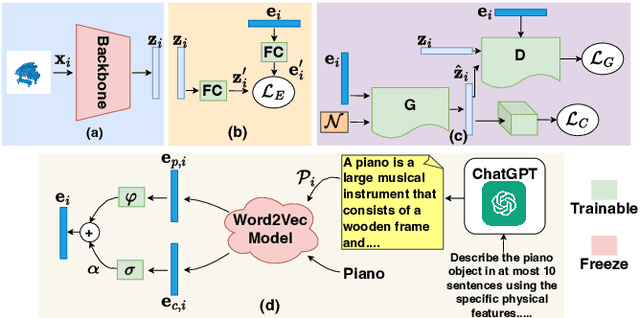
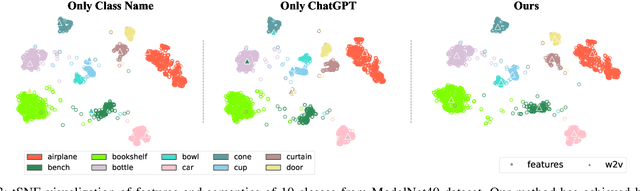
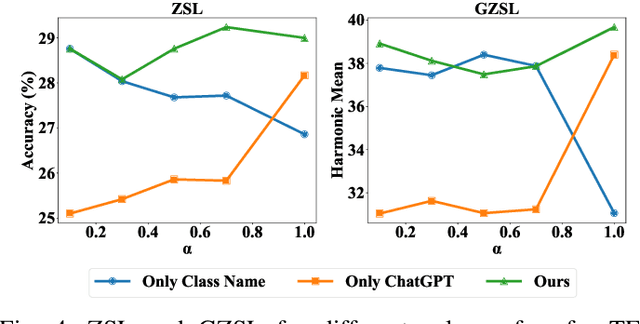
Zero-shot learning (ZSL) aims to classify objects that are not observed or seen during training. It relies on class semantic description to transfer knowledge from the seen classes to the unseen classes. Existing methods of obtaining class semantics include manual attributes or automatic word vectors from language models (like word2vec). We know attribute annotation is costly, whereas automatic word-vectors are relatively noisy. To address this problem, we explore how ChatGPT, a large language model, can enhance class semantics for ZSL tasks. ChatGPT can be a helpful source to obtain text descriptions for each class containing related attributes and semantics. We use the word2vec model to get a word vector using the texts from ChatGPT. Then, we enrich word vectors by combining the word embeddings from class names and descriptions generated by ChatGPT. More specifically, we leverage ChatGPT to provide extra supervision for the class description, eventually benefiting ZSL models. We evaluate our approach on various 2D image (CUB and AwA) and 3D point cloud (ModelNet10, ModelNet40, and ScanObjectNN) datasets and show that it improves ZSL performance. Our work contributes to the ZSL literature by applying ChatGPT for class semantics enhancement and proposing a novel word vector fusion method.