 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiFM: Bidirectional Flow Matching for Few-Step Image Editing and Generation
Mar 26, 2026Recent diffusion and flow matching models have demonstrated strong capabilities in image generation and editing by progressively removing noise through iterative sampling. While this enables flexible inversion for semantic-preserving edits, few-step sampling regimes suffer from poor forward process approximation, leading to degraded editing quality. Existing few-step inversion methods often rely on pretrained generators and auxiliary modules, limiting scalability and generalization across different architectures. To address these limitations, we propose BiFM (Bidirectional Flow Matching), a unified framework that jointly learns generation and inversion within a single model. BiFM directly estimates average velocity fields in both ``image $\to$ noise" and ``noise $\to$ image" directions, constrained by a shared instantaneous velocity field derived from either predefined schedules or pretrained multi-step diffusion models. Additionally, BiFM introduces a novel training strategy using continuous time-interval supervision, stabilized by a bidirectional consistency objective and a lightweight time-interval embedding. This bidirectional formulation also enables one-step inversion and can integrate seamlessly into popular diffusion and flow matching backbones. Across diverse image editing and generation tasks, BiFM consistently outperforms existing few-step approaches, achieving superior performance and editability.
ARMFlow: AutoRegressive MeanFlow for Online 3D Human Reaction Generation
Dec 18, 2025



3D human reaction generation faces three main challenges:(1) high motion fidelity, (2) real-time inference, and (3) autoregressive adaptability for online scenarios. Existing methods fail to meet all three simultaneously. We propose ARMFlow, a MeanFlow-based autoregressive framework that models temporal dependencies between actor and reactor motions. It consists of a causal context encoder and an MLP-based velocity predictor. We introduce Bootstrap Contextual Encoding (BSCE) in training, encoding generated history instead of the ground-truth ones, to alleviate error accumulation in autoregressive generation. We further introduce the offline variant ReMFlow, achieving state-of-the-art performance with the fastest inference among offline methods. Our ARMFlow addresses key limitations of online settings by: (1) enhancing semantic alignment via a global contextual encoder; (2) achieving high accuracy and low latency in a single-step inference; and (3) reducing accumulated errors through BSCE. Our single-step online generation surpasses existing online methods on InterHuman and InterX by over 40% in FID, while matching offline state-of-the-art performance despite using only partial sequence conditions.
Quality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
PSMamba: Progressive Self-supervised Vision Mamba for Plant Disease Recognition
Dec 16, 2025Self-supervised Learning (SSL) has become a powerful paradigm for representation learning without manual annotations. However, most existing frameworks focus on global alignment and struggle to capture the hierarchical, multi-scale lesion patterns characteristic of plant disease imagery. To address this gap, we propose PSMamba, a progressive self-supervised framework that integrates the efficient sequence modelling of Vision Mamba (VM) with a dual-student hierarchical distillation strategy. Unlike conventional single teacher-student designs, PSMamba employs a shared global teacher and two specialised students: one processes mid-scale views to capture lesion distributions and vein structures, while the other focuses on local views to capture fine-grained cues such as texture irregularities and early-stage lesions. This multi-granular supervision facilitates the joint learning of contextual and detailed representations, with consistency losses ensuring coherent cross-scale alignment. Experiments on three benchmark datasets show that PSMamba consistently outperforms state-of-the-art SSL methods, delivering superior accuracy and robustness in both domain-shifted and fine-grained scenarios.
StateSpace-SSL: Linear-Time Self-supervised Learning for Plant Disease Detection
Dec 11, 2025Self-supervised learning (SSL) is attractive for plant disease detection as it can exploit large collections of unlabeled leaf images, yet most existing SSL methods are built on CNNs or vision transformers that are poorly matched to agricultural imagery. CNN-based SSL struggles to capture disease patterns that evolve continuously along leaf structures, while transformer-based SSL introduces quadratic attention cost from high-resolution patches. To address these limitations, we propose StateSpace-SSL, a linear-time SSL framework that employs a Vision Mamba state-space encoder to model long-range lesion continuity through directional scanning across the leaf surface. A prototype-driven teacher-student objective aligns representations across multiple views, encouraging stable and lesion-aware features from labelled data. Experiments on three publicly available plant disease datasets show that StateSpace-SSL consistently outperforms the CNN- and transformer-based SSL baselines in various evaluation metrics. Qualitative analyses further confirm that it learns compact, lesion-focused feature maps, highlighting the advantage of linear state-space modelling for self-supervised plant disease representation learning.
UniHM: Universal Human Motion Generation with Object Interactions in Indoor Scenes
May 19, 2025Human motion synthesis in complex scenes presents a fundamental challenge, extending beyond conventional Text-to-Motion tasks by requiring the integration of diverse modalities such as static environments, movable objects, natural language prompts, and spatial waypoints. Existing language-conditioned motion models often struggle with scene-aware motion generation due to limitations in motion tokenization, which leads to information loss and fails to capture the continuous, context-dependent nature of 3D human movement. To address these issues, we propose UniHM, a unified motion language model that leverages diffusion-based generation for synthesizing scene-aware human motion. UniHM is the first framework to support both Text-to-Motion and Text-to-Human-Object Interaction (HOI) in complex 3D scenes. Our approach introduces three key contributions: (1) a mixed-motion representation that fuses continuous 6DoF motion with discrete local motion tokens to improve motion realism; (2) a novel Look-Up-Free Quantization VAE (LFQ-VAE) that surpasses traditional VQ-VAEs in both reconstruction accuracy and generative performance; and (3) an enriched version of the Lingo dataset augmented with HumanML3D annotations, providing stronger supervision for scene-specific motion learning. Experimental results demonstrate that UniHM achieves comparative performance on the OMOMO benchmark for text-to-HOI synthesis and yields competitive results on HumanML3D for general text-conditioned motion generation.
MoKD: Multi-Task Optimization for Knowledge Distillation
May 13, 2025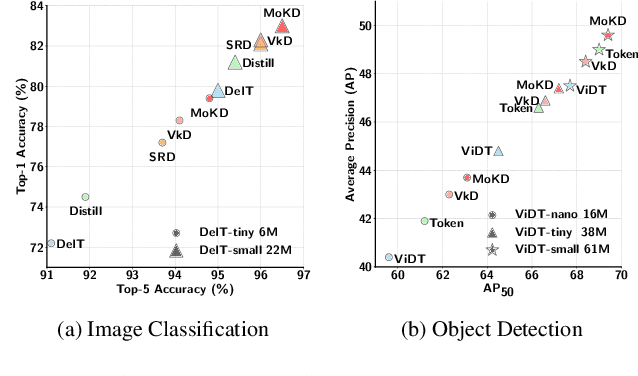
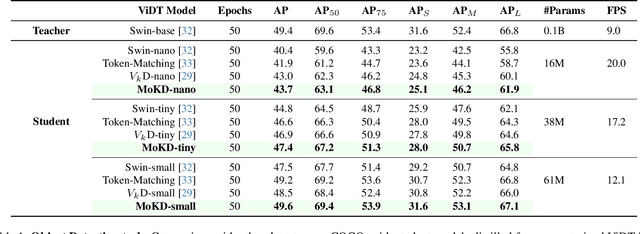
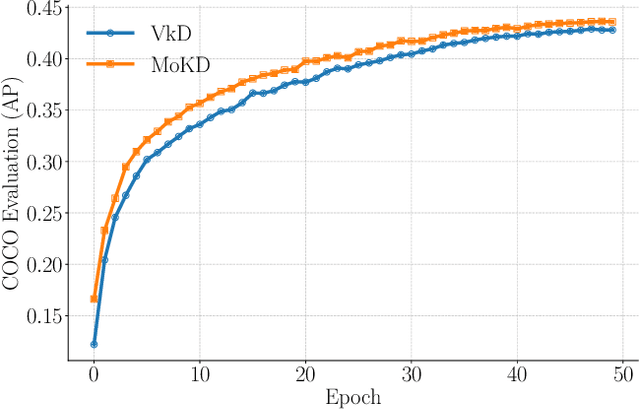
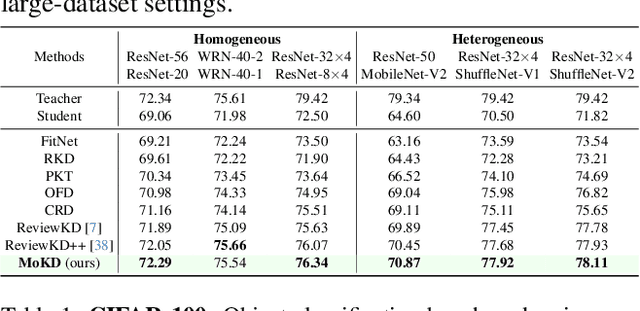
Compact models can be effectively trained through Knowledge Distillation (KD), a technique that transfers knowledge from larger, high-performing teacher models. Two key challenges in Knowledge Distillation (KD) are: 1) balancing learning from the teacher's guidance and the task objective, and 2) handling the disparity in knowledge representation between teacher and student models. To address these, we propose Multi-Task Optimization for Knowledge Distillation (MoKD). MoKD tackles two main gradient issues: a) Gradient Conflicts, where task-specific and distillation gradients are misaligned, and b) Gradient Dominance, where one objective's gradient dominates, causing imbalance. MoKD reformulates KD as a multi-objective optimization problem, enabling better balance between objectives. Additionally, it introduces a subspace learning framework to project feature representations into a high-dimensional space, improving knowledge transfer. Our MoKD is demonstrated to outperform existing methods through extensive experiments on image classification using the ImageNet-1K dataset and object detection using the COCO dataset, achieving state-of-the-art performance with greater efficiency. To the best of our knowledge, MoKD models also achieve state-of-the-art performance compared to models trained from scratch.
Auto-Regressive Diffusion for Generating 3D Human-Object Interactions
Mar 21, 2025Text-driven Human-Object Interaction (Text-to-HOI) generation is an emerging field with applications in animation, video games, virtual reality, and robotics. A key challenge in HOI generation is maintaining interaction consistency in long sequences. Existing Text-to-Motion-based approaches, such as discrete motion tokenization, cannot be directly applied to HOI generation due to limited data in this domain and the complexity of the modality. To address the problem of interaction consistency in long sequences, we propose an autoregressive diffusion model (ARDHOI) that predicts the next continuous token. Specifically, we introduce a Contrastive Variational Autoencoder (cVAE) to learn a physically plausible space of continuous HOI tokens, thereby ensuring that generated human-object motions are realistic and natural. For generating sequences autoregressively, we develop a Mamba-based context encoder to capture and maintain consistent sequential actions. Additionally, we implement an MLP-based denoiser to generate the subsequent token conditioned on the encoded context. Our model has been evaluated on the OMOMO and BEHAVE datasets, where it outperforms existing state-of-the-art methods in terms of both performance and inference speed. This makes ARDHOI a robust and efficient solution for text-driven HOI tasks
NeFF-BioNet: Crop Biomass Prediction from Point Cloud to Drone Imagery
Oct 30, 2024Crop biomass offers crucial insights into plant health and yield, making it essential for crop science, farming systems, and agricultural research. However, current measurement methods, which are labor-intensive, destructive, and imprecise, hinder large-scale quantification of this trait. To address this limitation, we present a biomass prediction network (BioNet), designed for adaptation across different data modalities, including point clouds and drone imagery. Our BioNet, utilizing a sparse 3D convolutional neural network (CNN) and a transformer-based prediction module, processes point clouds and other 3D data representations to predict biomass. To further extend BioNet for drone imagery, we integrate a neural feature field (NeFF) module, enabling 3D structure reconstruction and the transformation of 2D semantic features from vision foundation models into the corresponding 3D surfaces. For the point cloud modality, BioNet demonstrates superior performance on two public datasets, with an approximate 6.1% relative improvement (RI) over the state-of-the-art. In the RGB image modality, the combination of BioNet and NeFF achieves a 7.9% RI. Additionally, the NeFF-based approach utilizes inexpensive, portable drone-mounted cameras, providing a scalable solution for large field applications.
Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
May 24, 2024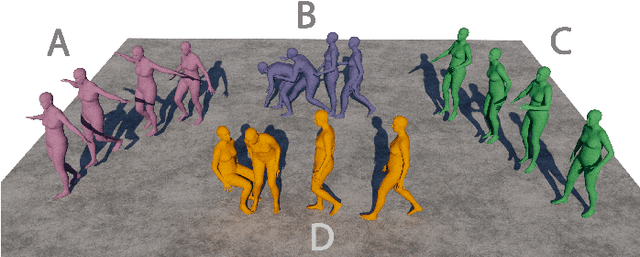

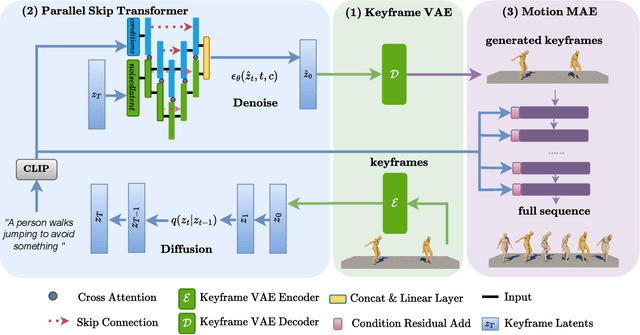
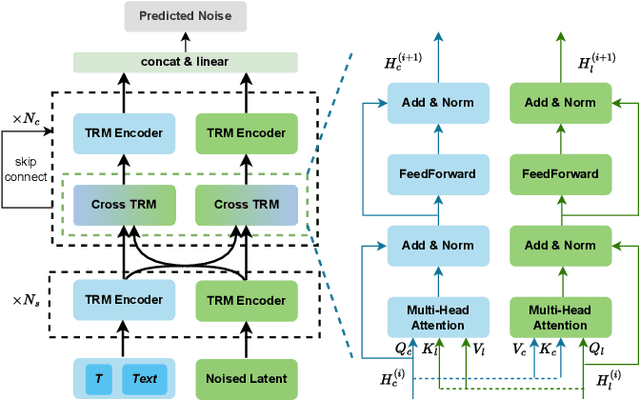
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.