 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Shift Aware Adaptation for Online Zero-shot Learning with Contrastive Language-Image Pre-Training (CLIP)
Jun 13, 2026Vision-language models like Contrastive Language-Image Pre-Training (CLIP) have been extensively studied in data-scarce scenarios. A particularly challenging and realistic task in this area is online zero-shot learning with CLIP, where unknown test samples are predicted sequentially in random order by CLIP while keeping the feature extraction and model parameters fixed during the sequential inference phase. Most existing approaches in this setting address the problem by adapting representations online using incoming test samples, while neglecting the distribution of the data on which CLIP was initially trained. This mismatch can lead to degraded performance when the label distribution in the test data differs from that of the training domain. To address this gap, we propose Label Shift Aware (LSA), which formulates the online zero-shot classification task as a domain adaptation problem. Specifically, LSA adapts the predictions computed by CLIP, which was trained on an unknown source distribution, to a target distribution using only unlabeled test data, and applies label shift correction to mitigate the mismatch between the source and target domains. The extensive experiments across multiple datasets demonstrate that the proposed LSA consistently outperforms state-of-the-art online zero-shot learning methods based on CLIP.
EgoSelf: From Memory to Personalized Egocentric Assistant
Apr 22, 2026Egocentric assistants often rely on first-person view data to capture user behavior and context for personalized services. Since different users exhibit distinct habits, preferences, and routines, such personalization is essential for truly effective assistance. However, effectively integrating long-term user data for personalization remains a key challenge. To address this, we introduce EgoSelf, a system that includes a graph-based interaction memory constructed from past observations and a dedicated learning task for personalization. The memory captures temporal and semantic relationships among interaction events and entities, from which user-specific profiles are derived. The personalized learning task is formulated as a prediction problem where the model predicts possible future interactions from individual user's historical behavior recorded in the graph. Extensive experiments demonstrate the effectiveness of EgoSelf as a personalized egocentric assistant. Code is available at https://abie-e.github.io/EgoSelf/.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
Maintain Plasticity in Long-timescale Continual Test-time Adaptation
Dec 28, 2024



Continual test-time domain adaptation (CTTA) aims to adjust pre-trained source models to perform well over time across non-stationary target environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: can the model adapt to continually-changing environments with preserved plasticity over a long time? The plasticity refers to the model's capability to adjust predictions in response to non-stationary environments continually. In this work, we explore plasticity, this essential but often overlooked aspect of continual adaptation to facilitate more sustained adaptation in the long run. First, we observe that most CTTA methods experience a steady and consistent decline in plasticity during the long-timescale continual adaptation phase. Moreover, we find that the loss of plasticity is strongly associated with the change in label flip. Based on this correlation, we propose a simple yet effective policy, Adaptive Shrink-Restore (ASR), towards preserving the model's plasticity. In particular, ASR does the weight re-initialization by the adaptive intervals. The adaptive interval is determined based on the change in label flipping. Our method is validated on extensive CTTA benchmarks, achieving excellent performance.
Efficient Transfer Learning for Video-language Foundation Models
Nov 18, 2024



Pre-trained vision-language models provide a robust foundation for efficient transfer learning across various downstream tasks. In the field of video action recognition, mainstream approaches often introduce additional parameter modules to capture temporal information. While the increased model capacity brought by these additional parameters helps better fit the video-specific inductive biases, existing methods require learning a large number of parameters and are prone to catastrophic forgetting of the original generalizable knowledge. In this paper, we propose a simple yet effective Multi-modal Spatio-Temporal Adapter (MSTA) to improve the alignment between representations in the text and vision branches, achieving a balance between general knowledge and task-specific knowledge. Furthermore, to mitigate over-fitting and enhance generalizability, we introduce a spatio-temporal description-guided consistency constraint. This constraint involves feeding template inputs (i.e., ``a video of $\{\textbf{cls}\}$'') into the trainable language branch, while LLM-generated spatio-temporal descriptions are input into the pre-trained language branch, enforcing consistency between the outputs of the two branches. This mechanism prevents over-fitting to downstream tasks and improves the distinguishability of the trainable branch within the spatio-temporal semantic space. We evaluate the effectiveness of our approach across four tasks: zero-shot transfer, few-shot learning, base-to-novel generalization, and fully-supervised learning. Compared to many state-of-the-art methods, our MSTA achieves outstanding performance across all evaluations, while using only 2-7\% of the trainable parameters in the original model. Code will be avaliable at https://github.com/chenhaoxing/ETL4Video.
Backpropagation-free Network for 3D Test-time Adaptation
Mar 27, 2024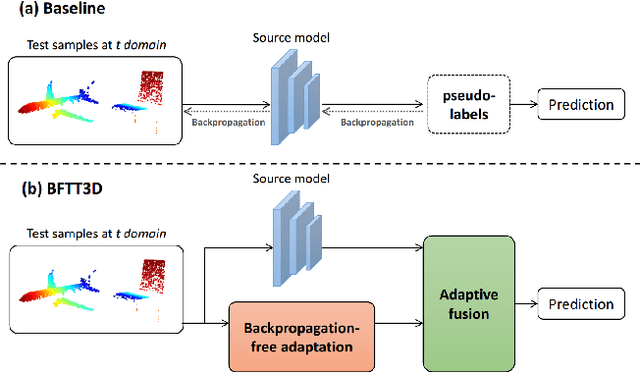
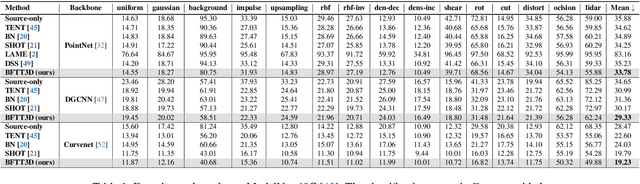
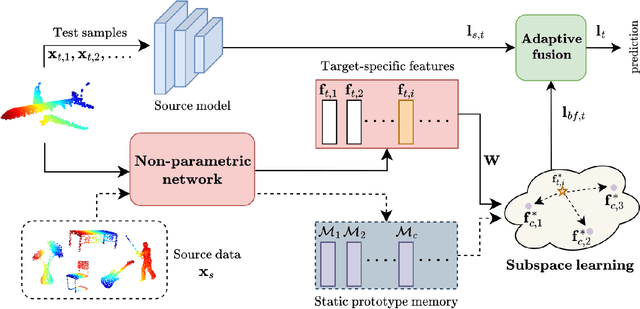
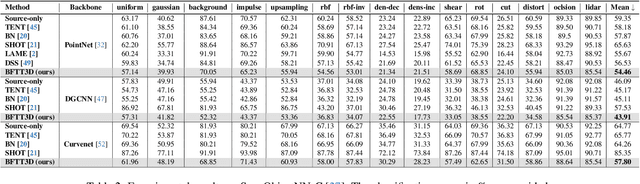
Real-world systems often encounter new data over time, which leads to experiencing target domain shifts. Existing Test-Time Adaptation (TTA) methods tend to apply computationally heavy and memory-intensive backpropagation-based approaches to handle this. Here, we propose a novel method that uses a backpropagation-free approach for TTA for the specific case of 3D data. Our model uses a two-stream architecture to maintain knowledge about the source domain as well as complementary target-domain-specific information. The backpropagation-free property of our model helps address the well-known forgetting problem and mitigates the error accumulation issue. The proposed method also eliminates the need for the usually noisy process of pseudo-labeling and reliance on costly self-supervised training. Moreover, our method leverages subspace learning, effectively reducing the distribution variance between the two domains. Furthermore, the source-domain-specific and the target-domain-specific streams are aligned using a novel entropy-based adaptive fusion strategy. Extensive experiments on popular benchmarks demonstrate the effectiveness of our method. The code will be available at https://github.com/abie-e/BFTT3D.
Continual Test-time Domain Adaptation via Dynamic Sample Selection
Oct 05, 2023



The objective of Continual Test-time Domain Adaptation (CTDA) is to gradually adapt a pre-trained model to a sequence of target domains without accessing the source data. This paper proposes a Dynamic Sample Selection (DSS) method for CTDA. DSS consists of dynamic thresholding, positive learning, and negative learning processes. Traditionally, models learn from unlabeled unknown environment data and equally rely on all samples' pseudo-labels to update their parameters through self-training. However, noisy predictions exist in these pseudo-labels, so all samples are not equally trustworthy. Therefore, in our method, a dynamic thresholding module is first designed to select suspected low-quality from high-quality samples. The selected low-quality samples are more likely to be wrongly predicted. Therefore, we apply joint positive and negative learning on both high- and low-quality samples to reduce the risk of using wrong information. We conduct extensive experiments that demonstrate the effectiveness of our proposed method for CTDA in the image domain, outperforming the state-of-the-art results. Furthermore, our approach is also evaluated in the 3D point cloud domain, showcasing its versatility and potential for broader applicability.