 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Shape, Then Meaning: Efficient Geometry and Semantics Learning for Indoor Reconstruction
May 05, 2026Neural Surface Reconstruction has become a standard methodology for indoor 3D reconstruction, with Signed Distance Functions (SDFs) proving particularly effective for representing scene geometry. A variety of applications require a detailed understanding of the scene context, driving the need for object-level semantic signals. While recent methods successfully integrate semantic labels, they often inherit the slow training time and limited scalability of multi-SDF learning. In this paper, we introduce FSTM, a unified approach for learning geometry and semantics through a two-step process: a geometry warm-up using RGB inputs and geometric cues, followed by semantic field estimation. By first optimising geometry without semantic supervision, we observe substantial improvements compared to the standard joint optimisation. Rather than relying on specialised modules or complex multi-SDF designs, FSTM shows that a streamlined formulation is sufficient to achieve strong geometric and semantic reconstructions. Experiments on both synthetic and real-world indoor datasets show that our method outperforms multi-SDF approaches. It trains 2.3x faster on Replica, improves robustness to real-world imperfections on ScanNet++, and achieves higher recall by recovering the surfaces of more objects in the scene. The code will be made available at https://remichierchia.github.io/FSTM.
In Depth We Trust: Reliable Monocular Depth Supervision for Gaussian Splatting
Apr 07, 2026Using accurate depth priors in 3D Gaussian Splatting helps mitigate artifacts caused by sparse training data and textureless surfaces. However, acquiring accurate depth maps requires specialized acquisition systems. Foundation monocular depth estimation models offer a cost-effective alternative, but they suffer from scale ambiguity, multi-view inconsistency, and local geometric inaccuracies, which can degrade rendering performance when applied naively. This paper addresses the challenge of reliably leveraging monocular depth priors for Gaussian Splatting (GS) rendering enhancement. To this end, we introduce a training framework integrating scale-ambiguous and noisy depth priors into geometric supervision. We highlight the importance of learning from weakly aligned depth variations. We introduce a method to isolate ill-posed geometry for selective monocular depth regularization, restricting the propagation of depth inaccuracies into well-reconstructed 3D structures. Extensive experiments across diverse datasets show consistent improvements in geometric accuracy, leading to more faithful depth estimation and higher rendering quality across different GS variants and monocular depth backbones tested.
BiFM: Bidirectional Flow Matching for Few-Step Image Editing and Generation
Mar 26, 2026Recent diffusion and flow matching models have demonstrated strong capabilities in image generation and editing by progressively removing noise through iterative sampling. While this enables flexible inversion for semantic-preserving edits, few-step sampling regimes suffer from poor forward process approximation, leading to degraded editing quality. Existing few-step inversion methods often rely on pretrained generators and auxiliary modules, limiting scalability and generalization across different architectures. To address these limitations, we propose BiFM (Bidirectional Flow Matching), a unified framework that jointly learns generation and inversion within a single model. BiFM directly estimates average velocity fields in both ``image $\to$ noise" and ``noise $\to$ image" directions, constrained by a shared instantaneous velocity field derived from either predefined schedules or pretrained multi-step diffusion models. Additionally, BiFM introduces a novel training strategy using continuous time-interval supervision, stabilized by a bidirectional consistency objective and a lightweight time-interval embedding. This bidirectional formulation also enables one-step inversion and can integrate seamlessly into popular diffusion and flow matching backbones. Across diverse image editing and generation tasks, BiFM consistently outperforms existing few-step approaches, achieving superior performance and editability.
Non-Invasive 3D Wound Measurement with RGB-D Imaging
Jan 26, 2026Chronic wound monitoring and management require accurate and efficient wound measurement methods. This paper presents a fast, non-invasive 3D wound measurement algorithm based on RGB-D imaging. The method combines RGB-D odometry with B-spline surface reconstruction to generate detailed 3D wound meshes, enabling automatic computation of clinically relevant wound measurements such as perimeter, surface area, and dimensions. We evaluated our system on realistic silicone wound phantoms and measured sub-millimetre 3D reconstruction accuracy compared with high-resolution ground-truth scans. The extracted measurements demonstrated low variability across repeated captures and strong agreement with manual assessments. The proposed pipeline also outperformed a state-of-the-art object-centric RGB-D reconstruction method while maintaining runtimes suitable for real-time clinical deployment. Our approach offers a promising tool for automated wound assessment in both clinical and remote healthcare settings.
Multi-View Consistent Wound Segmentation With Neural Fields
Jan 23, 2026Wound care is often challenged by the economic and logistical burdens that consistently afflict patients and hospitals worldwide. In recent decades, healthcare professionals have sought support from computer vision and machine learning algorithms. In particular, wound segmentation has gained interest due to its ability to provide professionals with fast, automatic tissue assessment from standard RGB images. Some approaches have extended segmentation to 3D, enabling more complete and precise healing progress tracking. However, inferring multi-view consistent 3D structures from 2D images remains a challenge. In this paper, we evaluate WoundNeRF, a NeRF SDF-based method for estimating robust wound segmentations from automatically generated annotations. We demonstrate the potential of this paradigm in recovering accurate segmentations by comparing it against state-of-the-art Vision Transformer networks and conventional rasterisation-based algorithms. The code will be released to facilitate further development in this promising paradigm.
Facial Spatiotemporal Graphs: Leveraging the 3D Facial Surface for Remote Physiological Measurement
Jan 20, 2026Facial remote photoplethysmography (rPPG) methods estimate physiological signals by modeling subtle color changes on the 3D facial surface over time. However, existing methods fail to explicitly align their receptive fields with the 3D facial surface-the spatial support of the rPPG signal. To address this, we propose the Facial Spatiotemporal Graph (STGraph), a novel representation that encodes facial color and structure using 3D facial mesh sequences-enabling surface-aligned spatiotemporal processing. We introduce MeshPhys, a lightweight spatiotemporal graph convolutional network that operates on the STGraph to estimate physiological signals. Across four benchmark datasets, MeshPhys achieves state-of-the-art or competitive performance in both intra- and cross-dataset settings. Ablation studies show that constraining the model's receptive field to the facial surface acts as a strong structural prior, and that surface-aligned, 3D-aware node features are critical for robustly encoding facial surface color. Together, the STGraph and MeshPhys constitute a novel, principled modeling paradigm for facial rPPG, enabling robust, interpretable, and generalizable estimation. Code is available at https://samcantrill.github.io/facial-stgraph-rppg/ .
PSMamba: Progressive Self-supervised Vision Mamba for Plant Disease Recognition
Dec 16, 2025Self-supervised Learning (SSL) has become a powerful paradigm for representation learning without manual annotations. However, most existing frameworks focus on global alignment and struggle to capture the hierarchical, multi-scale lesion patterns characteristic of plant disease imagery. To address this gap, we propose PSMamba, a progressive self-supervised framework that integrates the efficient sequence modelling of Vision Mamba (VM) with a dual-student hierarchical distillation strategy. Unlike conventional single teacher-student designs, PSMamba employs a shared global teacher and two specialised students: one processes mid-scale views to capture lesion distributions and vein structures, while the other focuses on local views to capture fine-grained cues such as texture irregularities and early-stage lesions. This multi-granular supervision facilitates the joint learning of contextual and detailed representations, with consistency losses ensuring coherent cross-scale alignment. Experiments on three benchmark datasets show that PSMamba consistently outperforms state-of-the-art SSL methods, delivering superior accuracy and robustness in both domain-shifted and fine-grained scenarios.
Quality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
StateSpace-SSL: Linear-Time Self-supervised Learning for Plant Disease Detection
Dec 11, 2025Self-supervised learning (SSL) is attractive for plant disease detection as it can exploit large collections of unlabeled leaf images, yet most existing SSL methods are built on CNNs or vision transformers that are poorly matched to agricultural imagery. CNN-based SSL struggles to capture disease patterns that evolve continuously along leaf structures, while transformer-based SSL introduces quadratic attention cost from high-resolution patches. To address these limitations, we propose StateSpace-SSL, a linear-time SSL framework that employs a Vision Mamba state-space encoder to model long-range lesion continuity through directional scanning across the leaf surface. A prototype-driven teacher-student objective aligns representations across multiple views, encouraging stable and lesion-aware features from labelled data. Experiments on three publicly available plant disease datasets show that StateSpace-SSL consistently outperforms the CNN- and transformer-based SSL baselines in various evaluation metrics. Qualitative analyses further confirm that it learns compact, lesion-focused feature maps, highlighting the advantage of linear state-space modelling for self-supervised plant disease representation learning.
Wound3DAssist: A Practical Framework for 3D Wound Assessment
Aug 25, 2025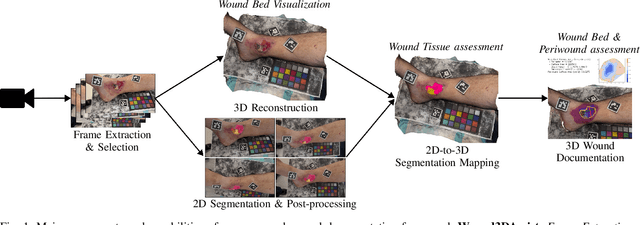
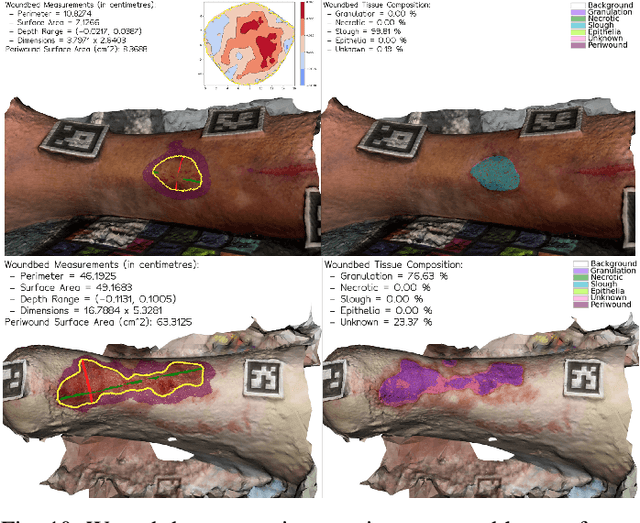
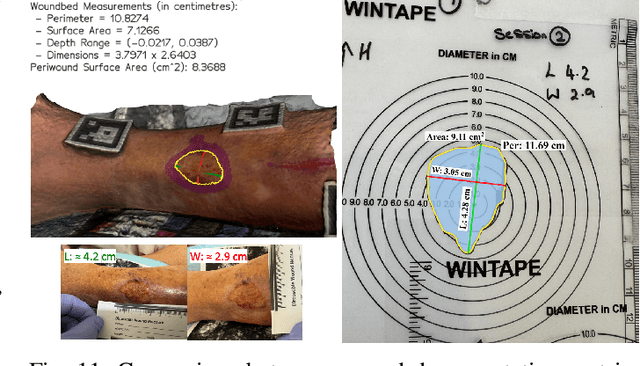
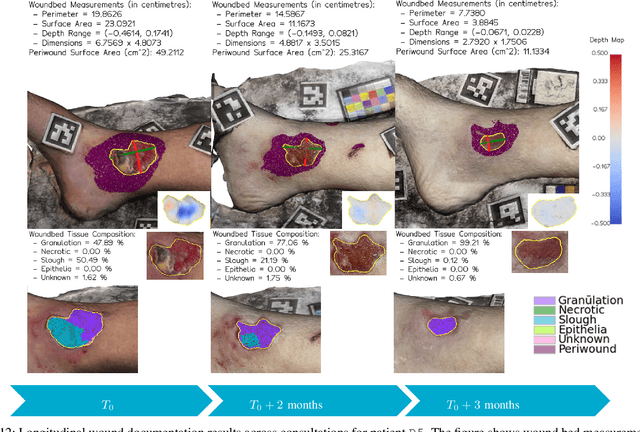
Managing chronic wounds remains a major healthcare challenge, with clinical assessment often relying on subjective and time-consuming manual documentation methods. Although 2D digital videometry frameworks aided the measurement process, these approaches struggle with perspective distortion, a limited field of view, and an inability to capture wound depth, especially in anatomically complex or curved regions. To overcome these limitations, we present Wound3DAssist, a practical framework for 3D wound assessment using monocular consumer-grade videos. Our framework generates accurate 3D models from short handheld smartphone video recordings, enabling non-contact, automatic measurements that are view-independent and robust to camera motion. We integrate 3D reconstruction, wound segmentation, tissue classification, and periwound analysis into a modular workflow. We evaluate Wound3DAssist across digital models with known geometry, silicone phantoms, and real patients. Results show that the framework supports high-quality wound bed visualization, millimeter-level accuracy, and reliable tissue composition analysis. Full assessments are completed in under 20 minutes, demonstrating feasibility for real-world clinical use.