 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoSplat: Robust Feed-Forward Pixel-wise Gaussian Splatting for Varying Input Views and High-Resolution Rendering
May 13, 2026Generalizable 3D Gaussian Splatting has recently emerged as an efficient approach for novel-view synthesis, enabling feed-forward synthesis from only a few input views. However, existing pixel-wise feed-forward methods suffer from over-bright renderings when the number of input views varies during inference, as well as insufficient supervision for accurate Gaussian scale estimation, which leads to hole artifacts, particularly in high-resolution renderings. To address these issues, we identify that the over-brightness is caused by the varying number of overlapping Gaussians and propose a simple alpha normalization strategy to maintain brightness consistency across different number of input views. In addition, we introduce an auxiliary 3D sampling-based regularizer to improve Gaussian scale estimation, thereby mitigating hole artifacts in high-resolution rendering. Experiments on benchmark datasets demonstrate that our method significantly improves baseline models under varying input-view and high-resolution rendering settings.
RobotPan: A 360$^\circ$ Surround-View Robotic Vision System for Embodied Perception
Apr 15, 2026Surround-view perception is increasingly important for robotic navigation and loco-manipulation, especially in human-in-the-loop settings such as teleoperation, data collection, and emergency takeover. However, current robotic visual interfaces are often limited to narrow forward-facing views, or, when multiple on-board cameras are available, require cumbersome manual switching that interrupts the operator's workflow. Both configurations suffer from motion-induced jitter that causes simulator sickness in head-mounted displays. We introduce a surround-view robotic vision system that combines six cameras with LiDAR to provide full 360$^\circ$ visual coverage, while meeting the geometric and real-time constraints of embodied deployment. We further present \textsc{RobotPan}, a feed-forward framework that predicts \emph{metric-scaled} and \emph{compact} 3D Gaussians from calibrated sparse-view inputs for real-time rendering, reconstruction, and streaming. \textsc{RobotPan} lifts multi-view features into a unified spherical coordinate representation and decodes Gaussians using hierarchical spherical voxel priors, allocating fine resolution near the robot and coarser resolution at larger radii to reduce computational redundancy without sacrificing fidelity. To support long sequences, our online fusion updates dynamic content while preventing unbounded growth in static regions by selectively updating appearance. Finally, we release a multi-sensor dataset tailored to 360$^\circ$ novel view synthesis and metric 3D reconstruction for robotics, covering navigation, manipulation, and locomotion on real platforms. Experiments show that \textsc{RobotPan} achieves competitive quality against prior feed-forward reconstruction and view-synthesis methods while producing substantially fewer Gaussians, enabling practical real-time embodied deployment. Project website: https://robotpan.github.io/
\textit{4DSurf}: High-Fidelity Dynamic Scene Surface Reconstruction
Mar 30, 2026This paper addresses the problem of dynamic scene surface reconstruction using Gaussian Splatting (GS), aiming to recover temporally consistent geometry. While existing GS-based dynamic surface reconstruction methods can yield superior reconstruction, they are typically limited to either a single object or objects with only small deformations, struggling to maintain temporally consistent surface reconstruction of large deformations over time. We propose ``\textit{4DSurf}'', a novel and unified framework for generic dynamic surface reconstruction that does not require specifying the number or types of objects in the scene, can handle large surface deformations and temporal inconsistency in reconstruction. The key innovation of our framework is the introduction of Gaussian deformations induced Signed Distance Function Flow Regularization that constrains the motion of Gaussians to align with the evolving surface. To handle large deformations, we introduce an Overlapping Segment Partitioning strategy that divides the sequence into overlapping segments with small deformations and incrementally passes geometric information across segments through the shared overlapping timestep. Experiments on two challenging dynamic scene datasets, Hi4D and CMU Panoptic, demonstrate that our method outperforms state-of-the-art surface reconstruction methods by 49\% and 19\% in Chamfer distance, respectively, and achieves superior temporal consistency under sparse-view settings.
IBGS: Image-Based Gaussian Splatting
Nov 18, 20253D Gaussian Splatting (3DGS) has recently emerged as a fast, high-quality method for novel view synthesis (NVS). However, its use of low-degree spherical harmonics limits its ability to capture spatially varying color and view-dependent effects such as specular highlights. Existing works augment Gaussians with either a global texture map, which struggles with complex scenes, or per-Gaussian texture maps, which introduces high storage overhead. We propose Image-Based Gaussian Splatting, an efficient alternative that leverages high-resolution source images for fine details and view-specific color modeling. Specifically, we model each pixel color as a combination of a base color from standard 3DGS rendering and a learned residual inferred from neighboring training images. This promotes accurate surface alignment and enables rendering images of high-frequency details and accurate view-dependent effects. Experiments on standard NVS benchmarks show that our method significantly outperforms prior Gaussian Splatting approaches in rendering quality, without increasing the storage footprint.
Joint Optimization of Neural Radiance Fields and Continuous Camera Motion from a Monocular Video
Apr 28, 2025Neural Radiance Fields (NeRF) has demonstrated its superior capability to represent 3D geometry but require accurately precomputed camera poses during training. To mitigate this requirement, existing methods jointly optimize camera poses and NeRF often relying on good pose initialisation or depth priors. However, these approaches struggle in challenging scenarios, such as large rotations, as they map each camera to a world coordinate system. We propose a novel method that eliminates prior dependencies by modeling continuous camera motions as time-dependent angular velocity and velocity. Relative motions between cameras are learned first via velocity integration, while camera poses can be obtained by aggregating such relative motions up to a world coordinate system defined at a single time step within the video. Specifically, accurate continuous camera movements are learned through a time-dependent NeRF, which captures local scene geometry and motion by training from neighboring frames for each time step. The learned motions enable fine-tuning the NeRF to represent the full scene geometry. Experiments on Co3D and Scannet show our approach achieves superior camera pose and depth estimation and comparable novel-view synthesis performance compared to state-of-the-art methods. Our code is available at https://github.com/HoangChuongNguyen/cope-nerf.
Magnetic Distortion Resistant Orientation Estimation
Oct 16, 2024



Inertial Measurement Unit (IMU) sensors, including accelerometers, gyroscopes, and magnetometers, are used to estimate the orientation of mobile devices. However, indoor magnetic fields are often distorted, causing the magnetometer's readings to deviate from true north and resulting in inaccurate orientation estimates. Existing solutions either ignore magnetic distortion or avoid using the magnetometer when distortion is detected. In this paper, we develop MDR, a Magnetic Distortion Resistant orientation estimation system that fundamentally models and corrects magnetic distortion. MDR builds a database to record magnetic directions at different locations and uses it to correct orientation estimates affected by magnetic distortion. To avoid the overhead of database preparation, MDR adopts practical designs to automatically update the database in parallel with orientation estimation. Experiments on 27+ hours of arm motion data show that MDR outperforms the state-of-the-art method by 35.34%.
SOAF: Scene Occlusion-aware Neural Acoustic Field
Jul 02, 2024



This paper tackles the problem of novel view audio-visual synthesis along an arbitrary trajectory in an indoor scene, given the audio-video recordings from other known trajectories of the scene. Existing methods often overlook the effect of room geometry, particularly wall occlusion to sound propagation, making them less accurate in multi-room environments. In this work, we propose a new approach called Scene Occlusion-aware Acoustic Field (SOAF) for accurate sound generation. Our approach derives a prior for sound energy field using distance-aware parametric sound-propagation modelling and then transforms it based on scene transmittance learned from the input video. We extract features from the local acoustic field centred around the receiver using a Fibonacci Sphere to generate binaural audio for novel views with a direction-aware attention mechanism. Extensive experiments on the real dataset~\emph{RWAVS} and the synthetic dataset~\emph{SoundSpaces} demonstrate that our method outperforms previous state-of-the-art techniques in audio generation. Project page: https://github.com/huiyu-gao/SOAF/.
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Apr 23, 2024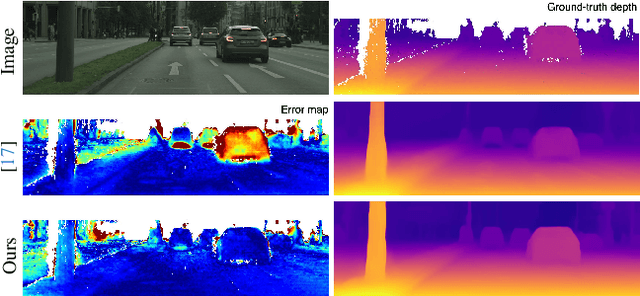



This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
HashPoint: Accelerated Point Searching and Sampling for Neural Rendering
Apr 22, 2024
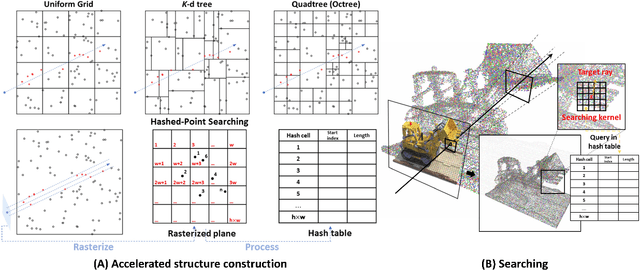

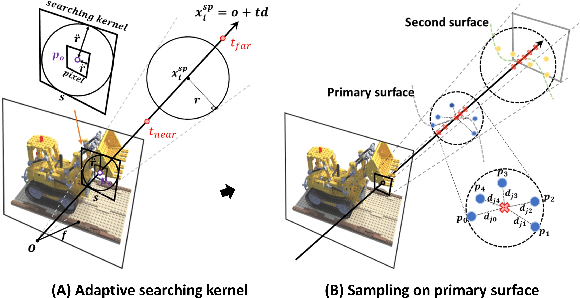
In this paper, we address the problem of efficient point searching and sampling for volume neural rendering. Within this realm, two typical approaches are employed: rasterization and ray tracing. The rasterization-based methods enable real-time rendering at the cost of increased memory and lower fidelity. In contrast, the ray-tracing-based methods yield superior quality but demand longer rendering time. We solve this problem by our HashPoint method combining these two strategies, leveraging rasterization for efficient point searching and sampling, and ray marching for rendering. Our method optimizes point searching by rasterizing points within the camera's view, organizing them in a hash table, and facilitating rapid searches. Notably, we accelerate the rendering process by adaptive sampling on the primary surface encountered by the ray. Our approach yields substantial speed-up for a range of state-of-the-art ray-tracing-based methods, maintaining equivalent or superior accuracy across synthetic and real test datasets. The code will be available at https://jiahao-ma.github.io/hashpoint/.
* CVPR2024 Highlight
MIDGET: Music Conditioned 3D Dance Generation
Apr 18, 2024In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
* 12 pages, 6 figures Published in AI 2023: Advances in Artificial Intelligence