 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIBGS: Image-Based Gaussian Splatting
Nov 18, 20253D Gaussian Splatting (3DGS) has recently emerged as a fast, high-quality method for novel view synthesis (NVS). However, its use of low-degree spherical harmonics limits its ability to capture spatially varying color and view-dependent effects such as specular highlights. Existing works augment Gaussians with either a global texture map, which struggles with complex scenes, or per-Gaussian texture maps, which introduces high storage overhead. We propose Image-Based Gaussian Splatting, an efficient alternative that leverages high-resolution source images for fine details and view-specific color modeling. Specifically, we model each pixel color as a combination of a base color from standard 3DGS rendering and a learned residual inferred from neighboring training images. This promotes accurate surface alignment and enables rendering images of high-frequency details and accurate view-dependent effects. Experiments on standard NVS benchmarks show that our method significantly outperforms prior Gaussian Splatting approaches in rendering quality, without increasing the storage footprint.
Joint Optimization of Neural Radiance Fields and Continuous Camera Motion from a Monocular Video
Apr 28, 2025Neural Radiance Fields (NeRF) has demonstrated its superior capability to represent 3D geometry but require accurately precomputed camera poses during training. To mitigate this requirement, existing methods jointly optimize camera poses and NeRF often relying on good pose initialisation or depth priors. However, these approaches struggle in challenging scenarios, such as large rotations, as they map each camera to a world coordinate system. We propose a novel method that eliminates prior dependencies by modeling continuous camera motions as time-dependent angular velocity and velocity. Relative motions between cameras are learned first via velocity integration, while camera poses can be obtained by aggregating such relative motions up to a world coordinate system defined at a single time step within the video. Specifically, accurate continuous camera movements are learned through a time-dependent NeRF, which captures local scene geometry and motion by training from neighboring frames for each time step. The learned motions enable fine-tuning the NeRF to represent the full scene geometry. Experiments on Co3D and Scannet show our approach achieves superior camera pose and depth estimation and comparable novel-view synthesis performance compared to state-of-the-art methods. Our code is available at https://github.com/HoangChuongNguyen/cope-nerf.
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Apr 23, 2024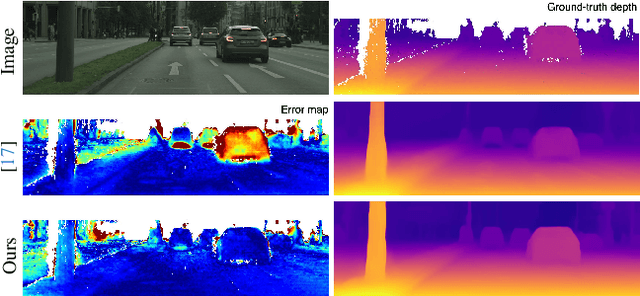



This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.