 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoDriveVLA: Evolving Autonomous Driving Vision-Language-Action Model via Collaborative Perception-Planning Distillation
Mar 10, 2026Vision-Language-Action models have shown great promise for autonomous driving, yet they suffer from degraded perception after unfreezing the visual encoder and struggle with accumulated instability in long-term planning. To address these challenges, we propose EvoDriveVLA-a novel collaborative perception-planning distillation framework that integrates self-anchored perceptual constraints and oracle-guided trajectory optimization. Specifically, self-anchored visual distillation leverages self-anchor teacher to deliver visual anchoring constraints, regularizing student representations via trajectory-guided key-region awareness. In parallel, oracle-guided trajectory distillation employs a future-aware oracle teacher with coarse-to-fine trajectory refinement and Monte Carlo dropout sampling to produce high-quality trajectory candidates, thereby selecting the optimal trajectory to guide the student's prediction. EvoDriveVLA achieves SOTA performance in open-loop evaluation and significantly enhances performance in closed-loop evaluation. Our code is available at: https://github.com/hey-cjj/EvoDriveVLA.
IBGS: Image-Based Gaussian Splatting
Nov 18, 20253D Gaussian Splatting (3DGS) has recently emerged as a fast, high-quality method for novel view synthesis (NVS). However, its use of low-degree spherical harmonics limits its ability to capture spatially varying color and view-dependent effects such as specular highlights. Existing works augment Gaussians with either a global texture map, which struggles with complex scenes, or per-Gaussian texture maps, which introduces high storage overhead. We propose Image-Based Gaussian Splatting, an efficient alternative that leverages high-resolution source images for fine details and view-specific color modeling. Specifically, we model each pixel color as a combination of a base color from standard 3DGS rendering and a learned residual inferred from neighboring training images. This promotes accurate surface alignment and enables rendering images of high-frequency details and accurate view-dependent effects. Experiments on standard NVS benchmarks show that our method significantly outperforms prior Gaussian Splatting approaches in rendering quality, without increasing the storage footprint.
Joint Optimization of Neural Radiance Fields and Continuous Camera Motion from a Monocular Video
Apr 28, 2025Neural Radiance Fields (NeRF) has demonstrated its superior capability to represent 3D geometry but require accurately precomputed camera poses during training. To mitigate this requirement, existing methods jointly optimize camera poses and NeRF often relying on good pose initialisation or depth priors. However, these approaches struggle in challenging scenarios, such as large rotations, as they map each camera to a world coordinate system. We propose a novel method that eliminates prior dependencies by modeling continuous camera motions as time-dependent angular velocity and velocity. Relative motions between cameras are learned first via velocity integration, while camera poses can be obtained by aggregating such relative motions up to a world coordinate system defined at a single time step within the video. Specifically, accurate continuous camera movements are learned through a time-dependent NeRF, which captures local scene geometry and motion by training from neighboring frames for each time step. The learned motions enable fine-tuning the NeRF to represent the full scene geometry. Experiments on Co3D and Scannet show our approach achieves superior camera pose and depth estimation and comparable novel-view synthesis performance compared to state-of-the-art methods. Our code is available at https://github.com/HoangChuongNguyen/cope-nerf.
Motion Anything: Any to Motion Generation
Mar 10, 2025Conditional motion generation has been extensively studied in computer vision, yet two critical challenges remain. First, while masked autoregressive methods have recently outperformed diffusion-based approaches, existing masking models lack a mechanism to prioritize dynamic frames and body parts based on given conditions. Second, existing methods for different conditioning modalities often fail to integrate multiple modalities effectively, limiting control and coherence in generated motion. To address these challenges, we propose Motion Anything, a multimodal motion generation framework that introduces an Attention-based Mask Modeling approach, enabling fine-grained spatial and temporal control over key frames and actions. Our model adaptively encodes multimodal conditions, including text and music, improving controllability. Additionally, we introduce Text-Motion-Dance (TMD), a new motion dataset consisting of 2,153 pairs of text, music, and dance, making it twice the size of AIST++, thereby filling a critical gap in the community. Extensive experiments demonstrate that Motion Anything surpasses state-of-the-art methods across multiple benchmarks, achieving a 15% improvement in FID on HumanML3D and showing consistent performance gains on AIST++ and TMD. See our project website https://steve-zeyu-zhang.github.io/MotionAnything
BAG: Body-Aligned 3D Wearable Asset Generation
Jan 27, 2025



While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.
Towards High-Quality 3D Motion Transfer with Realistic Apparel Animation
Jul 15, 2024
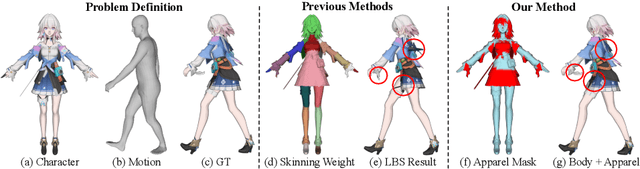

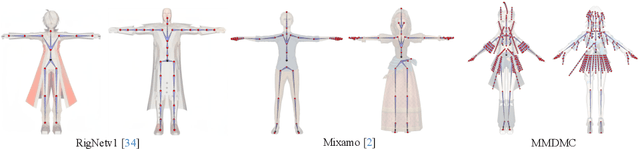
Animating stylized characters to match a reference motion sequence is a highly demanded task in film and gaming industries. Existing methods mostly focus on rigid deformations of characters' body, neglecting local deformations on the apparel driven by physical dynamics. They deform apparel the same way as the body, leading to results with limited details and unrealistic artifacts, e.g. body-apparel penetration. In contrast, we present a novel method aiming for high-quality motion transfer with realistic apparel animation. As existing datasets lack annotations necessary for generating realistic apparel animations, we build a new dataset named MMDMC, which combines stylized characters from the MikuMikuDance community with real-world Motion Capture data. We then propose a data-driven pipeline that learns to disentangle body and apparel deformations via two neural deformation modules. For body parts, we propose a geodesic attention block to effectively incorporate semantic priors into skeletal body deformation to tackle complex body shapes for stylized characters. Since apparel motion can significantly deviate from respective body joints, we propose to model apparel deformation in a non-linear vertex displacement field conditioned on its historic states. Extensive experiments show that our method produces results with superior quality for various types of apparel. Our dataset is released in https://github.com/rongakowang/MMDMC.
MIDGET: Music Conditioned 3D Dance Generation
Apr 18, 2024In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
* 12 pages, 6 figures Published in AI 2023: Advances in Artificial Intelligence
DeepSimHO: Stable Pose Estimation for Hand-Object Interaction via Physics Simulation
Oct 11, 2023This paper addresses the task of 3D pose estimation for a hand interacting with an object from a single image observation. When modeling hand-object interaction, previous works mainly exploit proximity cues, while overlooking the dynamical nature that the hand must stably grasp the object to counteract gravity and thus preventing the object from slipping or falling. These works fail to leverage dynamical constraints in the estimation and consequently often produce unstable results. Meanwhile, refining unstable configurations with physics-based reasoning remains challenging, both by the complexity of contact dynamics and by the lack of effective and efficient physics inference in the data-driven learning framework. To address both issues, we present DeepSimHO: a novel deep-learning pipeline that combines forward physics simulation and backward gradient approximation with a neural network. Specifically, for an initial hand-object pose estimated by a base network, we forward it to a physics simulator to evaluate its stability. However, due to non-smooth contact geometry and penetration, existing differentiable simulators can not provide reliable state gradient. To remedy this, we further introduce a deep network to learn the stability evaluation process from the simulator, while smoothly approximating its gradient and thus enabling effective back-propagation. Extensive experiments show that our method noticeably improves the stability of the estimation and achieves superior efficiency over test-time optimization. The code is available at https://github.com/rongakowang/DeepSimHO.
Scene-aware Human Motion Forecasting via Mutual Distance Prediction
Oct 01, 2023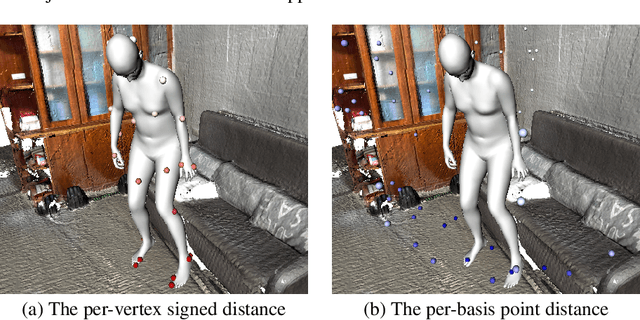
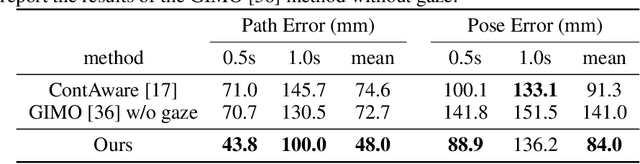
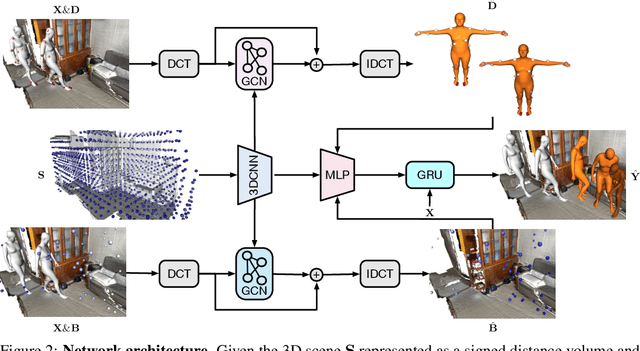

In this paper, we tackle the problem of scene-aware 3D human motion forecasting. A key challenge of this task is to predict future human motions that are consistent with the scene, by modelling the human-scene interactions. While recent works have demonstrated that explicit constraints on human-scene interactions can prevent the occurrence of ghost motion, they only provide constraints on partial human motion e.g., the global motion of the human or a few joints contacting the scene, leaving the rest motion unconstrained. To address this limitation, we propose to model the human-scene interaction with the mutual distance between the human body and the scene. Such mutual distances constrain both the local and global human motion, resulting in a whole-body motion constrained prediction. In particular, mutual distance constraints consist of two components, the signed distance of each vertex on the human mesh to the scene surface, and the distance of basis scene points to the human mesh. We develop a pipeline with two prediction steps that first predicts the future mutual distances from the past human motion sequence and the scene, and then forecasts the future human motion conditioning on the predicted mutual distances. During training, we explicitly encourage consistency between the predicted poses and the mutual distances. Our approach outperforms the state-of-the-art methods on both synthetic and real datasets.
TransMUSIC: A Transformer-Aided Subspace Method for DOA Estimation with Low-Resolution ADCs
Sep 15, 2023Direction of arrival (DOA) estimation employing low-resolution analog-to-digital convertors (ADCs) has emerged as a challenging and intriguing problem, particularly with the rise in popularity of large-scale arrays. The substantial quantization distortion complicates the extraction of signal and noise subspaces from the quantized data. To address this issue, this paper introduces a novel approach that leverages the Transformer model to aid the subspace estimation. In this model, multiple snapshots are processed in parallel, enabling the capture of global correlations that span them. The learned subspace empowers us to construct the MUSIC spectrum and perform gridless DOA estimation using a neural network-based peak finder. Additionally, the acquired subspace encodes the vital information of model order, allowing us to determine the exact number of sources. These integrated components form a unified algorithmic framework referred to as TransMUSIC. Numerical results demonstrate the superiority of the TransMUSIC algorithm, even when dealing with one-bit quantized data. The results highlight the potential of Transformer-based techniques in DOA estimation.