 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHPA: Adaptive Hierarchical Prior Alignment for Diffusion Transformers
May 05, 2026Representation alignment has recently emerged as an effective paradigm for accelerating Diffusion Transformer training. Despite their success, existing alignment methods typically impose a fixed supervision target or a fixed alignment granularity throughout the entire denoising trajectory, whether the guidance is provided by external vision encoders, internal self-representations, or VAE-derived features. We argue that such timestep-agnostic alignment is suboptimal because the useful granularity of representation supervision changes systematically with the signal-to-noise ratio. In high-noise regimes, diffusion models benefit more from coarse semantic and layout-level anchoring, whereas in low-noise regimes, the training signal should emphasize spatially detailed and structurally faithful refinement. This non-stationary alignment behavior creates a representational mismatch for static single-level supervisors. To address this issue, we propose Adaptive Hierarchical Prior Alignment (AHPA), a lightweight alignment framework that exploits the hierarchical representations naturally embedded in the frozen VAE encoder. Instead of using only a single compressed latent as the alignment target, AHPA extracts multi-level VAE features that provide complementary priors ranging from local geometry and spatial topology to coarse semantic layout. A timestep-conditioned Dynamic Router adaptively selects and weights these hierarchical priors along the denoising trajectory, thereby synchronizing the alignment granularity with the model's evolving training needs. Extensive experiments show that AHPA improves convergence and generation quality over baselines and incurs no additional inference cost while avoiding external encoder supervision during training.
VP-VLA: Visual Prompting as an Interface for Vision-Language-Action Models
Mar 23, 2026Vision-Language-Action (VLA) models typically map visual observations and linguistic instructions directly to robotic control signals. This "black-box" mapping forces a single forward pass to simultaneously handle instruction interpretation, spatial grounding, and low-level control, often leading to poor spatial precision and limited robustness in out-of-distribution scenarios. To address these limitations, we propose VP-VLA, a dual-system framework that decouples high-level reasoning and low-level execution via a structured visual prompting interface. Specifically, a "System 2 Planner" decomposes complex instructions into sub-tasks and identifies relevant target objects and goal locations. These spatial anchors are then overlaid directly onto visual observations as structured visual prompts, such as crosshairs and bounding boxes. Guided by these prompts and enhanced by a novel auxiliary visual grounding objective during training, a "System 1 Controller" reliably generates precise low-level execution motions. Experiments on the Robocasa-GR1-Tabletop benchmark and SimplerEnv simulation demonstrate that VP-VLA improves success rates by 5% and 8.3%, surpassing competitive baselines including QwenOFT and GR00T-N1.6.
OpenSubject: Leveraging Video-Derived Identity and Diversity Priors for Subject-driven Image Generation and Manipulation
Dec 10, 2025Despite the promising progress in subject-driven image generation, current models often deviate from the reference identities and struggle in complex scenes with multiple subjects. To address this challenge, we introduce OpenSubject, a video-derived large-scale corpus with 2.5M samples and 4.35M images for subject-driven generation and manipulation. The dataset is built with a four-stage pipeline that exploits cross-frame identity priors. (i) Video Curation. We apply resolution and aesthetic filtering to obtain high-quality clips. (ii) Cross-Frame Subject Mining and Pairing. We utilize vision-language model (VLM)-based category consensus, local grounding, and diversity-aware pairing to select image pairs. (iii) Identity-Preserving Reference Image Synthesis. We introduce segmentation map-guided outpainting to synthesize the input images for subject-driven generation and box-guided inpainting to generate input images for subject-driven manipulation, together with geometry-aware augmentations and irregular boundary erosion. (iv) Verification and Captioning. We utilize a VLM to validate synthesized samples, re-synthesize failed samples based on stage (iii), and then construct short and long captions. In addition, we introduce a benchmark covering subject-driven generation and manipulation, and then evaluate identity fidelity, prompt adherence, manipulation consistency, and background consistency with a VLM judge. Extensive experiments show that training with OpenSubject improves generation and manipulation performance, particularly in complex scenes.
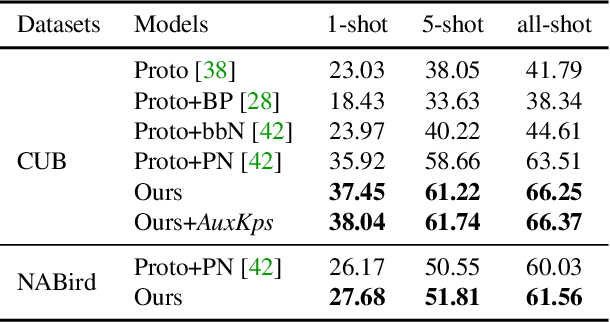
OpenKD: Opening Prompt Diversity for Zero- and Few-shot Keypoint Detection
Sep 30, 2024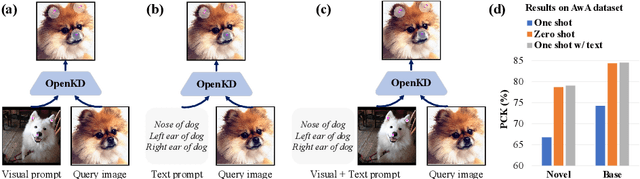
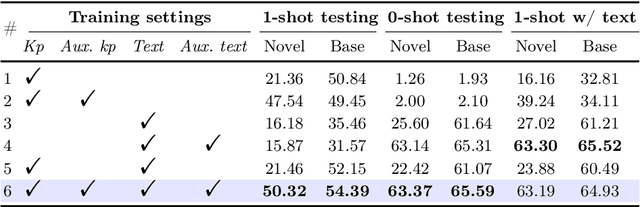

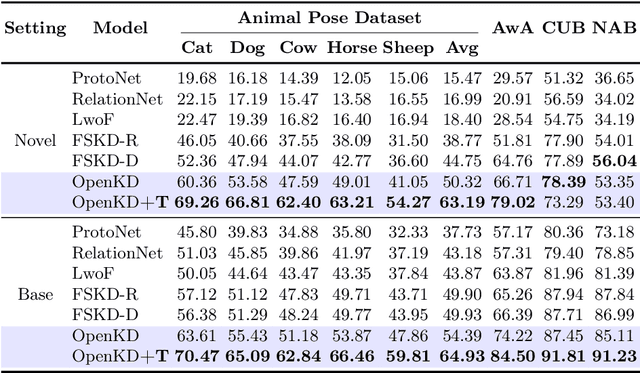
Exploiting the foundation models (e.g., CLIP) to build a versatile keypoint detector has gained increasing attention. Most existing models accept either the text prompt (e.g., ``the nose of a cat''), or the visual prompt (e.g., support image with keypoint annotations), to detect the corresponding keypoints in query image, thereby, exhibiting either zero-shot or few-shot detection ability. However, the research on taking multimodal prompt is still underexplored, and the prompt diversity in semantics and language is far from opened. For example, how to handle unseen text prompts for novel keypoint detection and the diverse text prompts like ``Can you detect the nose and ears of a cat?'' In this work, we open the prompt diversity from three aspects: modality, semantics (seen v.s. unseen), and language, to enable a more generalized zero- and few-shot keypoint detection (Z-FSKD). We propose a novel OpenKD model which leverages multimodal prototype set to support both visual and textual prompting. Further, to infer the keypoint location of unseen texts, we add the auxiliary keypoints and texts interpolated from visual and textual domains into training, which improves the spatial reasoning of our model and significantly enhances zero-shot novel keypoint detection. We also found large language model (LLM) is a good parser, which achieves over 96% accuracy to parse keypoints from texts. With LLM, OpenKD can handle diverse text prompts. Experimental results show that our method achieves state-of-the-art performance on Z-FSKD and initiates new ways to deal with unseen text and diverse texts. The source code and data are available at https://github.com/AlanLuSun/OpenKD.
Towards High-Quality 3D Motion Transfer with Realistic Apparel Animation
Jul 15, 2024
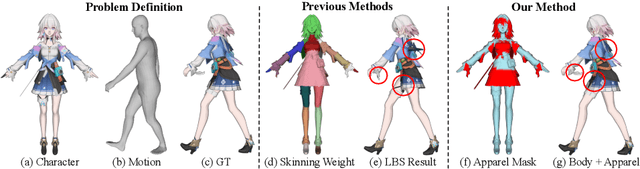

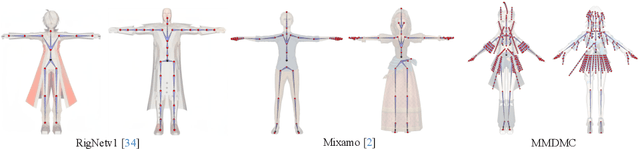
Animating stylized characters to match a reference motion sequence is a highly demanded task in film and gaming industries. Existing methods mostly focus on rigid deformations of characters' body, neglecting local deformations on the apparel driven by physical dynamics. They deform apparel the same way as the body, leading to results with limited details and unrealistic artifacts, e.g. body-apparel penetration. In contrast, we present a novel method aiming for high-quality motion transfer with realistic apparel animation. As existing datasets lack annotations necessary for generating realistic apparel animations, we build a new dataset named MMDMC, which combines stylized characters from the MikuMikuDance community with real-world Motion Capture data. We then propose a data-driven pipeline that learns to disentangle body and apparel deformations via two neural deformation modules. For body parts, we propose a geodesic attention block to effectively incorporate semantic priors into skeletal body deformation to tackle complex body shapes for stylized characters. Since apparel motion can significantly deviate from respective body joints, we propose to model apparel deformation in a non-linear vertex displacement field conditioned on its historic states. Extensive experiments show that our method produces results with superior quality for various types of apparel. Our dataset is released in https://github.com/rongakowang/MMDMC.
Few-shot Shape Recognition by Learning Deep Shape-aware Features
Dec 03, 2023Traditional shape descriptors have been gradually replaced by convolutional neural networks due to their superior performance in feature extraction and classification. The state-of-the-art methods recognize object shapes via image reconstruction or pixel classification. However , these methods are biased toward texture information and overlook the essential shape descriptions, thus, they fail to generalize to unseen shapes. We are the first to propose a fewshot shape descriptor (FSSD) to recognize object shapes given only one or a few samples. We employ an embedding module for FSSD to extract transformation-invariant shape features. Secondly, we develop a dual attention mechanism to decompose and reconstruct the shape features via learnable shape primitives. In this way, any shape can be formed through a finite set basis, and the learned representation model is highly interpretable and extendable to unseen shapes. Thirdly, we propose a decoding module to include the supervision of shape masks and edges and align the original and reconstructed shape features, enforcing the learned features to be more shape-aware. Lastly, all the proposed modules are assembled into a few-shot shape recognition scheme. Experiments on five datasets show that our FSSD significantly improves the shape classification compared to the state-of-the-art under the few-shot setting.
From Saliency to DINO: Saliency-guided Vision Transformer for Few-shot Keypoint Detection
Apr 06, 2023Unlike current deep keypoint detectors that are trained to recognize limited number of body parts, few-shot keypoint detection (FSKD) attempts to localize any keypoints, including novel or base keypoints, depending on the reference samples. FSKD requires the semantically meaningful relations for keypoint similarity learning to overcome the ubiquitous noise and ambiguous local patterns. One rescue comes with vision transformer (ViT) as it captures long-range relations well. However, ViT may model irrelevant features outside of the region of interest due to the global attention matrix, thus degrading similarity learning between support and query features. In this paper, we present a novel saliency-guided vision transformer, dubbed SalViT, for few-shot keypoint detection. Our SalViT enjoys a uniquely designed masked self-attention and a morphology learner, where the former introduces saliency map as a soft mask to constrain the self-attention on foregrounds, while the latter leverages the so-called power normalization to adjust morphology of saliency map, realizing ``dynamically changing receptive field''. Moreover, as salinecy detectors add computations, we show that attentive masks of DINO transformer can replace saliency. On top of SalViT, we also investigate i) transductive FSKD that enhances keypoint representations with unlabelled data and ii) FSKD under occlusions. We show that our model performs well on five public datasets and achieves ~10% PCK higher than the normally trained model under severe occlusions.
Few-shot Keypoint Detection with Uncertainty Learning for Unseen Species
Dec 12, 2021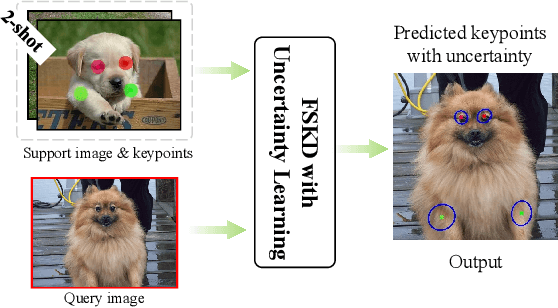

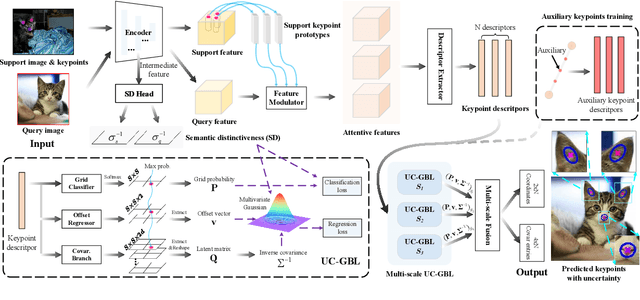
Current non-rigid object keypoint detectors perform well on a chosen kind of species and body parts, and require a large amount of labelled keypoints for training. Moreover, their heatmaps, tailored to specific body parts, cannot recognize novel keypoints (keypoints not labelled for training) on unseen species. We raise an interesting yet challenging question: how to detect both base (annotated for training) and novel keypoints for unseen species given a few annotated samples? Thus, we propose a versatile Few-shot Keypoint Detection (FSKD) pipeline, which can detect a varying number of keypoints of different kinds. Our FSKD provides the uncertainty estimation of predicted keypoints. Specifically, FSKD involves main and auxiliary keypoint representation learning, similarity learning, and keypoint localization with uncertainty modeling to tackle the localization noise. Moreover, we model the uncertainty across groups of keypoints by multivariate Gaussian distribution to exploit implicit correlations between neighboring keypoints. We show the effectiveness of our FSKD on (i) novel keypoint detection for unseen species, and (ii) few-shot Fine-Grained Visual Recognition (FGVR) and (iii) Semantic Alignment (SA) downstream tasks. For FGVR, detected keypoints improve the classification accuracy. For SA, we showcase a novel thin-plate-spline warping that uses estimated keypoint uncertainty under imperfect keypoint corespondences.
Industrial Scene Text Detection with Refined Feature-attentive Network
Oct 25, 2021
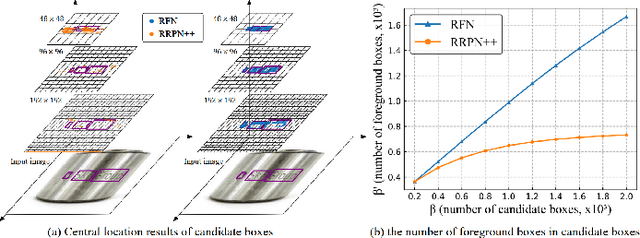


Detecting the marking characters of industrial metal parts remains challenging due to low visual contrast, uneven illumination, corroded character structures, and cluttered background of metal part images. Affected by these factors, bounding boxes generated by most existing methods locate low-contrast text areas inaccurately. In this paper, we propose a refined feature-attentive network (RFN) to solve the inaccurate localization problem. Specifically, we design a parallel feature integration mechanism to construct an adaptive feature representation from multi-resolution features, which enhances the perception of multi-scale texts at each scale-specific level to generate a high-quality attention map. Then, an attentive refinement network is developed by the attention map to rectify the location deviation of candidate boxes. In addition, a re-scoring mechanism is designed to select text boxes with the best rectified location. Moreover, we construct two industrial scene text datasets, including a total of 102156 images and 1948809 text instances with various character structures and metal parts. Extensive experiments on our dataset and four public datasets demonstrate that our proposed method achieves the state-of-the-art performance.
High-quality Ellipse Detection Based on Arc-support Line Segments
Oct 08, 2018
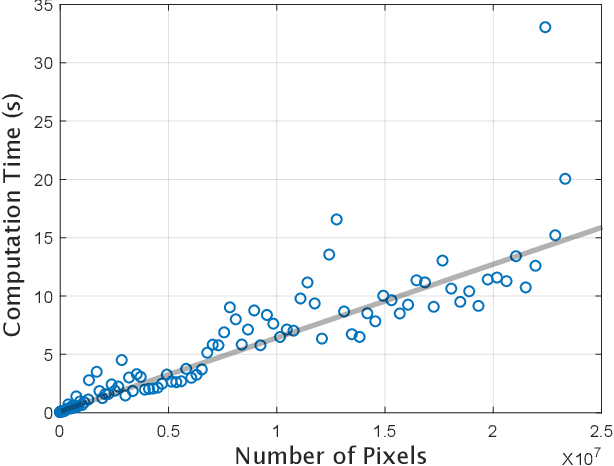
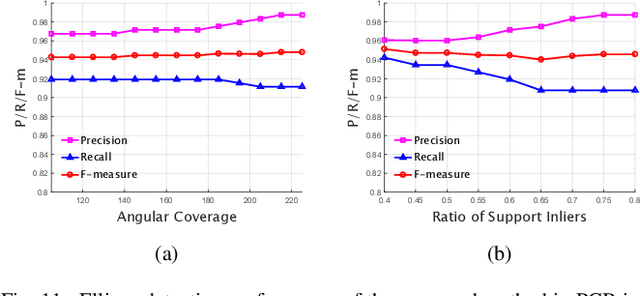
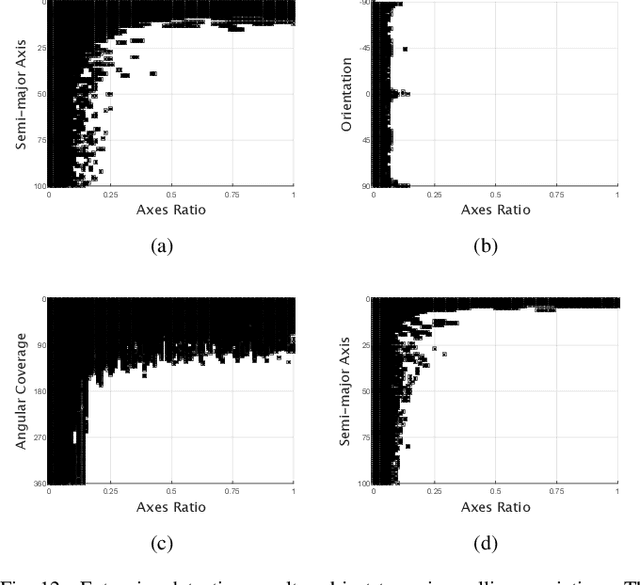
Over the years many ellipse detection algorithms spring up and are studied broadly, while the critical issue of detecting ellipses accurately and efficiently in real-world images remains a challenge. In this paper, an accurate and efficient ellipse detector by arc-support line segments is proposed. The arc-support line segment simplifies the complicated expression of curves in an image while retains the general properties including convexity and polarity, which grounds the successful detection of ellipses. The arc-support groups are formed by iteratively and robustly linking the arc-support line segments that latently belong to a common ellipse at point statistics level. Afterward, two complementary approaches, namely, selecting the group with higher saliency to fit an ellipse, and searching all the valid paired arc-support groups, are utilized to generate the initial ellipse set, both locally and globally. In ellipse fitting step, a superposition principle for the fast ellipse fitting is developed to accelerate the process. Then, the ellipse candidates can be formulated by the hierarchical clustering of 5D parameter space of initial ellipse set. Finally, the salient ellipse candidates are selected as detections subject to the stringent and effective verification. Extensive experiments on three public datasets are implemented and our method achieves the best F-measure scores compared to the state-of-the-art methods.