 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenKD: Opening Prompt Diversity for Zero- and Few-shot Keypoint Detection
Paper and Code
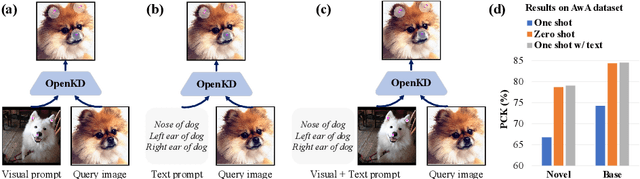
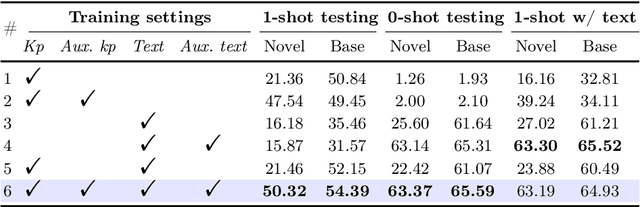

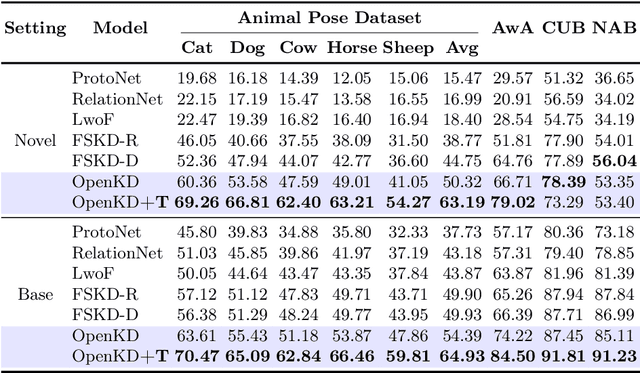
Exploiting the foundation models (e.g., CLIP) to build a versatile keypoint detector has gained increasing attention. Most existing models accept either the text prompt (e.g., ``the nose of a cat''), or the visual prompt (e.g., support image with keypoint annotations), to detect the corresponding keypoints in query image, thereby, exhibiting either zero-shot or few-shot detection ability. However, the research on taking multimodal prompt is still underexplored, and the prompt diversity in semantics and language is far from opened. For example, how to handle unseen text prompts for novel keypoint detection and the diverse text prompts like ``Can you detect the nose and ears of a cat?'' In this work, we open the prompt diversity from three aspects: modality, semantics (seen v.s. unseen), and language, to enable a more generalized zero- and few-shot keypoint detection (Z-FSKD). We propose a novel OpenKD model which leverages multimodal prototype set to support both visual and textual prompting. Further, to infer the keypoint location of unseen texts, we add the auxiliary keypoints and texts interpolated from visual and textual domains into training, which improves the spatial reasoning of our model and significantly enhances zero-shot novel keypoint detection. We also found large language model (LLM) is a good parser, which achieves over 96% accuracy to parse keypoints from texts. With LLM, OpenKD can handle diverse text prompts. Experimental results show that our method achieves state-of-the-art performance on Z-FSKD and initiates new ways to deal with unseen text and diverse texts. The source code and data are available at https://github.com/AlanLuSun/OpenKD.