 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Framework of Application Methods for Large Language Models in Language Sciences
Dec 10, 2025Large Language Models (LLMs) are transforming language sciences. However, their widespread deployment currently suffers from methodological fragmentation and a lack of systematic soundness. This study proposes two comprehensive methodological frameworks designed to guide the strategic and responsible application of LLMs in language sciences. The first method-selection framework defines and systematizes three distinct, complementary approaches, each linked to a specific research goal: (1) prompt-based interaction with general-use models for exploratory analysis and hypothesis generation; (2) fine-tuning of open-source models for confirmatory, theory-driven investigation and high-quality data generation; and (3) extraction of contextualized embeddings for further quantitative analysis and probing of model internal mechanisms. We detail the technical implementation and inherent trade-offs of each method, supported by empirical case studies. Based on the method-selection framework, the second systematic framework proposed provides constructed configurations that guide the practical implementation of multi-stage research pipelines based on these approaches. We then conducted a series of empirical experiments to validate our proposed framework, employing retrospective analysis, prospective application, and an expert evaluation survey. By enforcing the strategic alignment of research questions with the appropriate LLM methodology, the frameworks enable a critical paradigm shift in language science research. We believe that this system is fundamental for ensuring reproducibility, facilitating the critical evaluation of LLM mechanisms, and providing the structure necessary to move traditional linguistics from ad-hoc utility to verifiable, robust science.
Towards Federated Clustering: A Client-wise Private Graph Aggregation Framework
Nov 14, 2025



Federated clustering addresses the critical challenge of extracting patterns from decentralized, unlabeled data. However, it is hampered by the flaw that current approaches are forced to accept a compromise between performance and privacy: \textit{transmitting embedding representations risks sensitive data leakage, while sharing only abstract cluster prototypes leads to diminished model accuracy}. To resolve this dilemma, we propose Structural Privacy-Preserving Federated Graph Clustering (SPP-FGC), a novel algorithm that innovatively leverages local structural graphs as the primary medium for privacy-preserving knowledge sharing, thus moving beyond the limitations of conventional techniques. Our framework operates on a clear client-server logic; on the client-side, each participant constructs a private structural graph that captures intrinsic data relationships, which the server then securely aggregates and aligns to form a comprehensive global graph from which a unified clustering structure is derived. The framework offers two distinct modes to suit different needs. SPP-FGC is designed as an efficient one-shot method that completes its task in a single communication round, ideal for rapid analysis. For more complex, unstructured data like images, SPP-FGC+ employs an iterative process where clients and the server collaboratively refine feature representations to achieve superior downstream performance. Extensive experiments demonstrate that our framework achieves state-of-the-art performance, improving clustering accuracy by up to 10\% (NMI) over federated baselines while maintaining provable privacy guarantees.
A Framework for Quantifying How Pre-Training and Context Benefit In-Context Learning
Oct 26, 2025Pre-trained large language models have demonstrated a strong ability to learn from context, known as in-context learning (ICL). Despite a surge of recent applications that leverage such capabilities, it is by no means clear, at least theoretically, how the ICL capabilities arise, and in particular, what is the precise role played by key factors such as pre-training procedure as well as context construction. In this work, we propose a new framework to analyze the ICL performance, for a class of realistic settings, which includes network architectures, data encoding, data generation, and prompt construction process. As a first step, we construct a simple example with a one-layer transformer, and show an interesting result, namely when the pre-train data distribution is different from the query task distribution, a properly constructed context can shift the output distribution towards the query task distribution, in a quantifiable manner, leading to accurate prediction on the query topic. We then extend the findings in the previous step to a more general case, and derive the precise relationship between ICL performance, context length and the KL divergence between pre-train and query task distribution. Finally, we provide experiments to validate our theoretical results.
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts
Jun 18, 2025The advent of Large Vision Models (LVMs) offers new opportunities for few-shot medical image segmentation. However, existing training-free methods based on LVMs fail to effectively utilize negative prompts, leading to poor performance on low-contrast medical images. To address this issue, we propose SynPo, a training-free few-shot method based on LVMs (e.g., SAM), with the core insight: improving the quality of negative prompts. To select point prompts in a more reliable confidence map, we design a novel Confidence Map Synergy Module by combining the strengths of DINOv2 and SAM. Based on the confidence map, we select the top-k pixels as the positive points set and choose the negative points set using a Gaussian distribution, followed by independent K-means clustering for both sets. Then, these selected points are leveraged as high-quality prompts for SAM to get the segmentation results. Extensive experiments demonstrate that SynPo achieves performance comparable to state-of-the-art training-based few-shot methods.
Dynamic Manipulation of Deformable Objects in 3D: Simulation, Benchmark and Learning Strategy
May 23, 2025Goal-conditioned dynamic manipulation is inherently challenging due to complex system dynamics and stringent task constraints, particularly in deformable object scenarios characterized by high degrees of freedom and underactuation. Prior methods often simplify the problem to low-speed or 2D settings, limiting their applicability to real-world 3D tasks. In this work, we explore 3D goal-conditioned rope manipulation as a representative challenge. To mitigate data scarcity, we introduce a novel simulation framework and benchmark grounded in reduced-order dynamics, which enables compact state representation and facilitates efficient policy learning. Building on this, we propose Dynamics Informed Diffusion Policy (DIDP), a framework that integrates imitation pretraining with physics-informed test-time adaptation. First, we design a diffusion policy that learns inverse dynamics within the reduced-order space, enabling imitation learning to move beyond na\"ive data fitting and capture the underlying physical structure. Second, we propose a physics-informed test-time adaptation scheme that imposes kinematic boundary conditions and structured dynamics priors on the diffusion process, ensuring consistency and reliability in manipulation execution. Extensive experiments validate the proposed approach, demonstrating strong performance in terms of accuracy and robustness in the learned policy.
Patient-Specific Dynamic Digital-Physical Twin for Coronary Intervention Training: An Integrated Mixed Reality Approach
May 16, 2025Background and Objective: Precise preoperative planning and effective physician training for coronary interventions are increasingly important. Despite advances in medical imaging technologies, transforming static or limited dynamic imaging data into comprehensive dynamic cardiac models remains challenging. Existing training systems lack accurate simulation of cardiac physiological dynamics. This study develops a comprehensive dynamic cardiac model research framework based on 4D-CTA, integrating digital twin technology, computer vision, and physical model manufacturing to provide precise, personalized tools for interventional cardiology. Methods: Using 4D-CTA data from a 60-year-old female with three-vessel coronary stenosis, we segmented cardiac chambers and coronary arteries, constructed dynamic models, and implemented skeletal skinning weight computation to simulate vessel deformation across 20 cardiac phases. Transparent vascular physical models were manufactured using medical-grade silicone. We developed cardiac output analysis and virtual angiography systems, implemented guidewire 3D reconstruction using binocular stereo vision, and evaluated the system through angiography validation and CABG training applications. Results: Morphological consistency between virtual and real angiography reached 80.9%. Dice similarity coefficients for guidewire motion ranged from 0.741-0.812, with mean trajectory errors below 1.1 mm. The transparent model demonstrated advantages in CABG training, allowing direct visualization while simulating beating heart challenges. Conclusion: Our patient-specific digital-physical twin approach effectively reproduces both anatomical structures and dynamic characteristics of coronary vasculature, offering a dynamic environment with visual and tactile feedback valuable for education and clinical planning.
Innovative Integration of 4D Cardiovascular Reconstruction and Hologram: A New Visualization Tool for Coronary Artery Bypass Grafting Planning
Apr 28, 2025Background: Coronary artery bypass grafting (CABG) planning requires advanced spatial visualization and consideration of coronary artery depth, calcification, and pericardial adhesions. Objective: To develop and evaluate a dynamic cardiovascular holographic visualization tool for preoperative CABG planning. Methods: Using 4D cardiac computed tomography angiography data from 14 CABG candidates, we developed a semi-automated workflow for time-resolved segmentation of cardiac structures, epicardial adipose tissue (EAT), and coronary arteries with calcium scoring. The workflow incorporated methods for cardiac segmentation, coronary calcification quantification, visualization of coronary depth within EAT, and pericardial adhesion assessment through motion analysis. Dynamic cardiovascular holograms were displayed using the Looking Glass platform. Thirteen cardiac surgeons evaluated the tool using a Likert scale. Additionally, pericardial adhesion scores from holograms of 21 patients (including seven undergoing secondary cardiac surgeries) were compared with intraoperative findings. Results: Surgeons rated the visualization tool highly for preoperative planning utility (mean Likert score: 4.57/5.0). Hologram-based pericardial adhesion scoring strongly correlated with intraoperative findings (r=0.786, P<0.001). Conclusion: This study establishes a visualization framework for CABG planning that produces clinically relevant dynamic holograms from patient-specific data, with clinical feedback confirming its effectiveness for preoperative planning.
MFH: A Multi-faceted Heuristic Algorithm Selection Approach for Software Verification
Mar 28, 2025Currently, many verification algorithms are available to improve the reliability of software systems. Selecting the appropriate verification algorithm typically demands domain expertise and non-trivial manpower. An automated algorithm selector is thus desired. However, existing selectors, either depend on machine-learned strategies or manually designed heuristics, encounter issues such as reliance on high-quality samples with algorithm labels and limited scalability. In this paper, an automated algorithm selection approach, namely MFH, is proposed for software verification. Our approach leverages the heuristics that verifiers producing correct results typically implement certain appropriate algorithms, and the supported algorithms by these verifiers indirectly reflect which ones are potentially applicable. Specifically, MFH embeds the code property graph (CPG) of a semantic-preserving transformed program to enhance the robustness of the prediction model. Furthermore, our approach decomposes the selection task into the sub-tasks of predicting potentially applicable algorithms and matching the most appropriate verifiers. Additionally, MFH also introduces a feedback loop on incorrect predictions to improve model prediction accuracy. We evaluate MFH on 20 verifiers and over 15,000 verification tasks. Experimental results demonstrate the effectiveness of MFH, achieving a prediction accuracy of 91.47% even without ground truth algorithm labels provided during the training phase. Moreover, the prediction accuracy decreases only by 0.84% when introducing 10 new verifiers, indicating the strong scalability of the proposed approach.
RSRWKV: A Linear-Complexity 2D Attention Mechanism for Efficient Remote Sensing Vision Task
Mar 26, 2025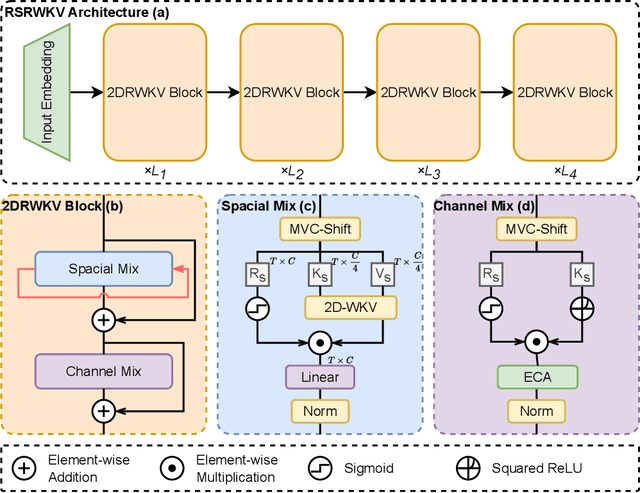



High-resolution remote sensing analysis faces challenges in global context modeling due to scene complexity and scale diversity. While CNNs excel at local feature extraction via parameter sharing, their fixed receptive fields fundamentally restrict long-range dependency modeling. Vision Transformers (ViTs) effectively capture global semantic relationships through self-attention mechanisms but suffer from quadratic computational complexity relative to image resolution, creating critical efficiency bottlenecks for high-resolution imagery. The RWKV model's linear-complexity sequence modeling achieves breakthroughs in NLP but exhibits anisotropic limitations in vision tasks due to its 1D scanning mechanism. To address these challenges, we propose RSRWKV, featuring a novel 2D-WKV scanning mechanism that bridges sequential processing and 2D spatial reasoning while maintaining linear complexity. This enables isotropic context aggregation across multiple directions. The MVC-Shift module enhances multi-scale receptive field coverage, while the ECA module strengthens cross-channel feature interaction and semantic saliency modeling. Experimental results demonstrate RSRWKV's superior performance over CNN and Transformer baselines in classification, detection, and segmentation tasks on NWPU RESISC45, VHR-10.v2, and GLH-Water datasets, offering a scalable solution for high-resolution remote sensing analysis.
FRESA:Feedforward Reconstruction of Personalized Skinned Avatars from Few Images
Mar 24, 2025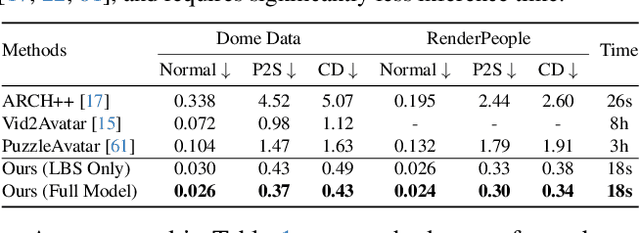
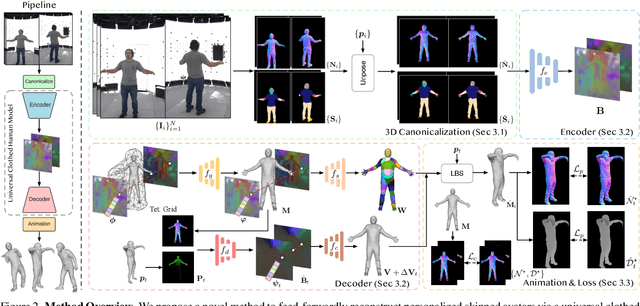
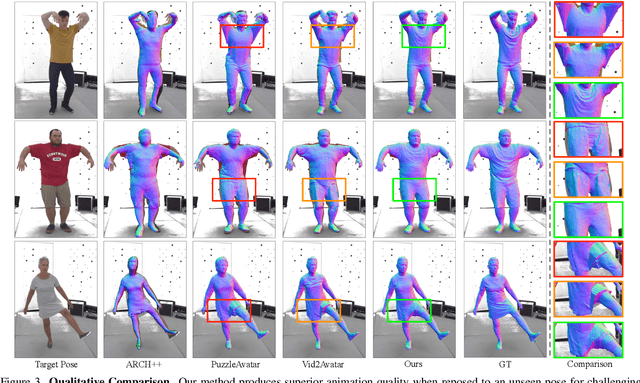
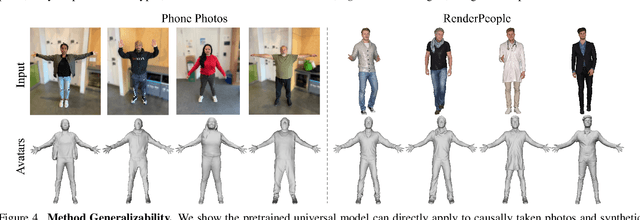
We present a novel method for reconstructing personalized 3D human avatars with realistic animation from only a few images. Due to the large variations in body shapes, poses, and cloth types, existing methods mostly require hours of per-subject optimization during inference, which limits their practical applications. In contrast, we learn a universal prior from over a thousand clothed humans to achieve instant feedforward generation and zero-shot generalization. Specifically, instead of rigging the avatar with shared skinning weights, we jointly infer personalized avatar shape, skinning weights, and pose-dependent deformations, which effectively improves overall geometric fidelity and reduces deformation artifacts. Moreover, to normalize pose variations and resolve coupled ambiguity between canonical shapes and skinning weights, we design a 3D canonicalization process to produce pixel-aligned initial conditions, which helps to reconstruct fine-grained geometric details. We then propose a multi-frame feature aggregation to robustly reduce artifacts introduced in canonicalization and fuse a plausible avatar preserving person-specific identities. Finally, we train the model in an end-to-end framework on a large-scale capture dataset, which contains diverse human subjects paired with high-quality 3D scans. Extensive experiments show that our method generates more authentic reconstruction and animation than state-of-the-arts, and can be directly generalized to inputs from casually taken phone photos. Project page and code is available at https://github.com/rongakowang/FRESA.