 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecolour What Matters: Region-Aware Colour Editing via Token-Level Diffusion
Mar 19, 2026Colour is one of the most perceptually salient yet least controllable attributes in image generation. Although recent diffusion models can modify object colours from user instructions, their results often deviate from the intended hue, especially for fine-grained and local edits. Early text-driven methods rely on discrete language descriptions that cannot accurately represent continuous chromatic variations. To overcome this limitation, we propose ColourCrafter, a unified diffusion framework that transforms colour editing from global tone transfer into a structured, region-aware generation process. Unlike traditional colour driven methods, ColourCrafter performs token-level fusion of RGB colour tokens and image tokens in latent space, selectively propagating colour information to semantically relevant regions while preserving structural fidelity. A perceptual Lab-space Loss further enhances pixel-level precision by decoupling luminance and chrominance and constraining edits within masked areas. Additionally, we build ColourfulSet, a largescale dataset of high-quality image pairs with continuous and diverse colour variations. Extensive experiments demonstrate that ColourCrafter achieves state-of-the-art colour accuracy, controllability and perceptual fidelity in fine-grained colour editing. Our project is available at https://yangyuqi317.github.io/ColourCrafter.github.io/.
Understanding Degradation with Vision Language Model
Feb 04, 2026Understanding visual degradations is a critical yet challenging problem in computer vision. While recent Vision-Language Models (VLMs) excel at qualitative description, they often fall short in understanding the parametric physics underlying image degradations. In this work, we redefine degradation understanding as a hierarchical structured prediction task, necessitating the concurrent estimation of degradation types, parameter keys, and their continuous physical values. Although these sub-tasks operate in disparate spaces, we prove that they can be unified under one autoregressive next-token prediction paradigm, whose error is bounded by the value-space quantization grid. Building on this insight, we introduce DU-VLM, a multimodal chain-of-thought model trained with supervised fine-tuning and reinforcement learning using structured rewards. Furthermore, we show that DU-VLM can serve as a zero-shot controller for pre-trained diffusion models, enabling high-fidelity image restoration without fine-tuning the generative backbone. We also introduce \textbf{DU-110k}, a large-scale dataset comprising 110,000 clean-degraded pairs with grounded physical annotations. Extensive experiments demonstrate that our approach significantly outperforms generalist baselines in both accuracy and robustness, exhibiting generalization to unseen distributions.
Multi-Distribution Robust Conformal Prediction
Jan 06, 2026In many fairness and distribution robustness problems, one has access to labeled data from multiple source distributions yet the test data may come from an arbitrary member or a mixture of them. We study the problem of constructing a conformal prediction set that is uniformly valid across multiple, heterogeneous distributions, in the sense that no matter which distribution the test point is from, the coverage of the prediction set is guaranteed to exceed a pre-specified level. We first propose a max-p aggregation scheme that delivers finite-sample, multi-distribution coverage given any conformity scores associated with each distribution. Upon studying several efficiency optimization programs subject to uniform coverage, we prove the optimality and tightness of our aggregation scheme, and propose a general algorithm to learn conformity scores that lead to efficient prediction sets after the aggregation under standard conditions. We discuss how our framework relates to group-wise distributionally robust optimization, sub-population shift, fairness, and multi-source learning. In synthetic and real-data experiments, our method delivers valid worst-case coverage across multiple distributions while greatly reducing the set size compared with naively applying max-p aggregation to single-source conformity scores, and can be comparable in size to single-source prediction sets with popular, standard conformity scores.
A Causal-Guided Multimodal Large Language Model for Generalized Power System Time-Series Data Analytics
Nov 11, 2025Power system time series analytics is critical in understanding the system operation conditions and predicting the future trends. Despite the wide adoption of Artificial Intelligence (AI) tools, many AI-based time series analytical models suffer from task-specificity (i.e. one model for one task) and structural rigidity (i.e. the input-output format is fixed), leading to limited model performances and resource wastes. In this paper, we propose a Causal-Guided Multimodal Large Language Model (CM-LLM) that can solve heterogeneous power system time-series analysis tasks. First, we introduce a physics-statistics combined causal discovery mechanism to capture the causal relationship, which is represented by graph, among power system variables. Second, we propose a multimodal data preprocessing framework that can encode and fuse text, graph and time series to enhance the model performance. Last, we formulate a generic "mask-and-reconstruct" paradigm and design a dynamic input-output padding mechanism to enable CM-LLM adaptive to heterogeneous time-series analysis tasks with varying sample lengths. Simulation results based on open-source LLM Qwen and real-world dataset demonstrate that, after simple fine-tuning, the proposed CM-LLM can achieve satisfying accuracy and efficiency on three heterogeneous time-series analytics tasks: missing data imputation, forecasting and super resolution.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
Dynamic Manipulation of Deformable Objects in 3D: Simulation, Benchmark and Learning Strategy
May 23, 2025Goal-conditioned dynamic manipulation is inherently challenging due to complex system dynamics and stringent task constraints, particularly in deformable object scenarios characterized by high degrees of freedom and underactuation. Prior methods often simplify the problem to low-speed or 2D settings, limiting their applicability to real-world 3D tasks. In this work, we explore 3D goal-conditioned rope manipulation as a representative challenge. To mitigate data scarcity, we introduce a novel simulation framework and benchmark grounded in reduced-order dynamics, which enables compact state representation and facilitates efficient policy learning. Building on this, we propose Dynamics Informed Diffusion Policy (DIDP), a framework that integrates imitation pretraining with physics-informed test-time adaptation. First, we design a diffusion policy that learns inverse dynamics within the reduced-order space, enabling imitation learning to move beyond na\"ive data fitting and capture the underlying physical structure. Second, we propose a physics-informed test-time adaptation scheme that imposes kinematic boundary conditions and structured dynamics priors on the diffusion process, ensuring consistency and reliability in manipulation execution. Extensive experiments validate the proposed approach, demonstrating strong performance in terms of accuracy and robustness in the learned policy.
Agent models: Internalizing Chain-of-Action Generation into Reasoning models
Mar 09, 2025



Traditional agentic workflows rely on external prompts to manage interactions with tools and the environment, which limits the autonomy of reasoning models. We position \emph{Large Agent Models (LAMs)} that internalize the generation of \emph{Chain-of-Action (CoA)}, enabling the model to autonomously decide when and how to use external tools. Our proposed AutoCoA framework combines supervised fine-tuning (SFT) and reinforcement learning (RL), allowing the model to seamlessly switch between reasoning and action while efficiently managing environment interactions. Main components include step-level action triggering, trajectory-level CoA optimization, and an internal world model to reduce real-environment interaction costs. Evaluations on open-domain QA tasks demonstrate that AutoCoA-trained agent models significantly outperform ReAct-based workflows in task completion, especially in tasks that require long-term reasoning and multi-step actions. Code and dataset are available at https://github.com/ADaM-BJTU/AutoCoA
OpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning
Dec 22, 2024OpenAI's recent introduction of Reinforcement Fine-Tuning (RFT) showcases the potential of reasoning foundation model and offers a new paradigm for fine-tuning beyond simple pattern imitation. This technical report presents \emph{OpenRFT}, our attempt to fine-tune generalist reasoning models for domain-specific tasks under the same settings as RFT. OpenRFT addresses two key challenges of lacking reasoning step data and the limited quantity of training samples, by leveraging the domain-specific samples in three ways: question augmentation, synthesizing reasoning-process data, and few-shot ICL. The evaluation is conducted on SciKnowEval, where OpenRFT achieves notable performance gains with only $100$ domain-specific samples for each task. More experimental results will be updated continuously in later versions. Source codes, datasets, and models are disclosed at: https://github.com/ADaM-BJTU/OpenRFT
o1-Coder: an o1 Replication for Coding
Nov 29, 2024

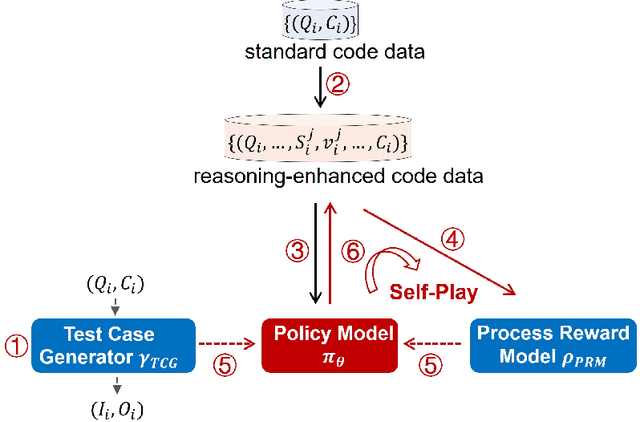

The technical report introduces O1-CODER, an attempt to replicate OpenAI's o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model's System-2 thinking capabilities. The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code. The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions. All source code, curated datasets, as well as the derived models will be disclosed at https://github.com/ADaM-BJTU/O1-CODER .
Night-to-Day Translation via Illumination Degradation Disentanglement
Nov 21, 2024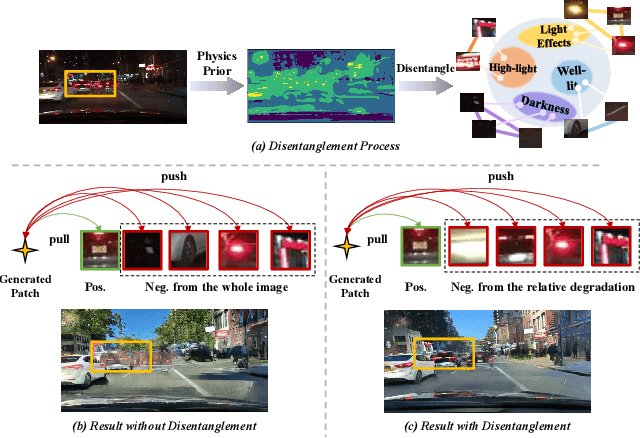
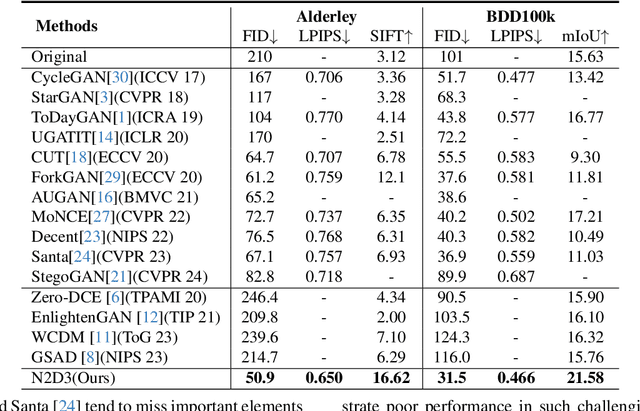

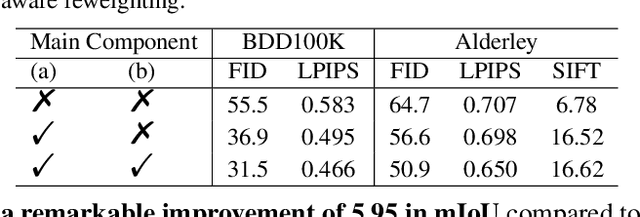
Night-to-Day translation (Night2Day) aims to achieve day-like vision for nighttime scenes. However, processing night images with complex degradations remains a significant challenge under unpaired conditions. Previous methods that uniformly mitigate these degradations have proven inadequate in simultaneously restoring daytime domain information and preserving underlying semantics. In this paper, we propose \textbf{N2D3} (\textbf{N}ight-to-\textbf{D}ay via \textbf{D}egradation \textbf{D}isentanglement) to identify different degradation patterns in nighttime images. Specifically, our method comprises a degradation disentanglement module and a degradation-aware contrastive learning module. Firstly, we extract physical priors from a photometric model based on Kubelka-Munk theory. Then, guided by these physical priors, we design a disentanglement module to discriminate among different illumination degradation regions. Finally, we introduce the degradation-aware contrastive learning strategy to preserve semantic consistency across distinct degradation regions. Our method is evaluated on two public datasets, demonstrating a significant improvement in visual quality and considerable potential for benefiting downstream tasks.