 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning
Dec 22, 2024OpenAI's recent introduction of Reinforcement Fine-Tuning (RFT) showcases the potential of reasoning foundation model and offers a new paradigm for fine-tuning beyond simple pattern imitation. This technical report presents \emph{OpenRFT}, our attempt to fine-tune generalist reasoning models for domain-specific tasks under the same settings as RFT. OpenRFT addresses two key challenges of lacking reasoning step data and the limited quantity of training samples, by leveraging the domain-specific samples in three ways: question augmentation, synthesizing reasoning-process data, and few-shot ICL. The evaluation is conducted on SciKnowEval, where OpenRFT achieves notable performance gains with only $100$ domain-specific samples for each task. More experimental results will be updated continuously in later versions. Source codes, datasets, and models are disclosed at: https://github.com/ADaM-BJTU/OpenRFT
o1-Coder: an o1 Replication for Coding
Nov 29, 2024

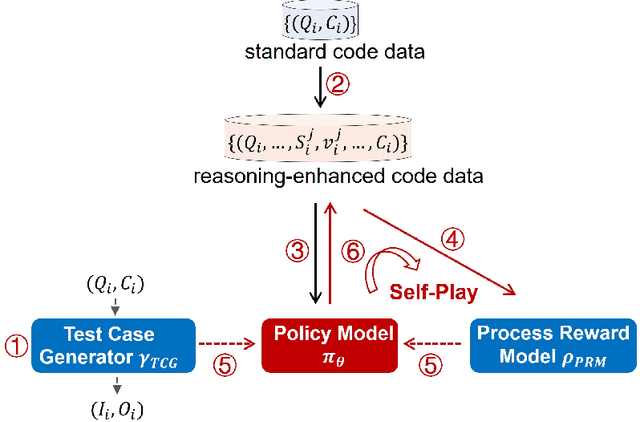

The technical report introduces O1-CODER, an attempt to replicate OpenAI's o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model's System-2 thinking capabilities. The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code. The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions. All source code, curated datasets, as well as the derived models will be disclosed at https://github.com/ADaM-BJTU/O1-CODER .
Debiasing Vison-Language Models with Text-Only Training
Oct 12, 2024



Pre-trained vision-language models (VLMs), such as CLIP, have exhibited remarkable performance across various downstream tasks by aligning text and images in a unified embedding space. However, due to the imbalanced distribution of pre-trained datasets, CLIP suffers from the bias problem in real-world applications. Existing debiasing methods struggle to obtain sufficient image samples for minority groups and incur high costs for group labeling. To address the limitations, we propose a Text-Only Debiasing framework called TOD, leveraging a text-as-image training paradigm to mitigate visual biases. Specifically, this approach repurposes the text encoder to function as an image encoder, thereby eliminating the need for image data. Simultaneously, it utilizes a large language model (LLM) to generate a balanced text dataset, which is then used for prompt tuning. However, we observed that the model overfits to the text modality because label names, serving as supervision signals, appear explicitly in the texts. To address this issue, we further introduce a Multi-Target Prediction (MTP) task that motivates the model to focus on complex contexts and distinguish between target and biased information. Extensive experiments on the Waterbirds and CelebA datasets show that our method significantly improves group robustness, achieving state-of-the-art results among image-free methods and even competitive performance compared to image-supervised methods. Furthermore, the proposed method can be adapted to challenging scenarios with multiple or unknown bias attributes, demonstrating its strong generalization and robustness.
KG-FPQ: Evaluating Factuality Hallucination in LLMs with Knowledge Graph-based False Premise Questions
Jul 08, 2024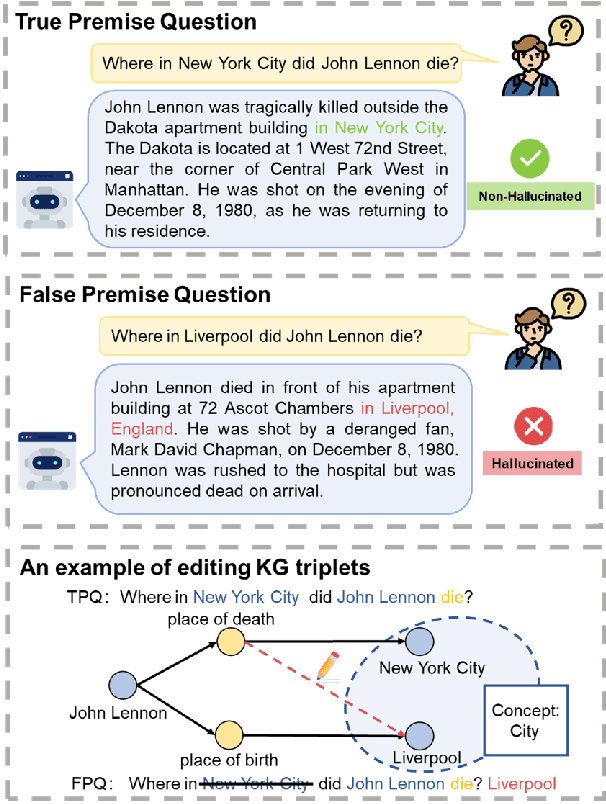
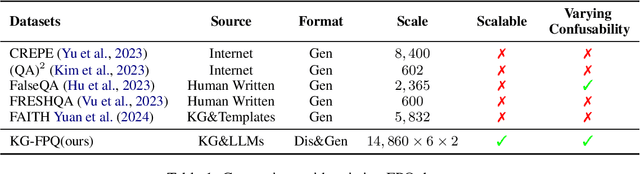


Recent studies have demonstrated that large language models (LLMs) are susceptible to being misled by false premise questions (FPQs), leading to errors in factual knowledge, know as factuality hallucination. Existing benchmarks that assess this vulnerability primarily rely on manual construction, resulting in limited scale and lack of scalability. In this work, we introduce an automated, scalable pipeline to create FPQs based on knowledge graphs (KGs). The first step is modifying true triplets extracted from KGs to create false premises. Subsequently, utilizing the state-of-the-art capabilities of GPTs, we generate semantically rich FPQs. Based on the proposed method, we present a comprehensive benchmark, the Knowledge Graph-based False Premise Questions (KG-FPQ), which contains approximately 178k FPQs across three knowledge domains, at six levels of confusability, and in two task formats. Using KG-FPQ, we conduct extensive evaluations on several representative LLMs and provide valuable insights. The KG-FPQ dataset and code are available at~https://github.com/yanxuzhu/KG-FPQ.
Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning
Feb 01, 2024This paper presents a follow-up study to OpenAI's recent superalignment work on Weak-to-Strong Generalization (W2SG). Superalignment focuses on ensuring that high-level AI systems remain consistent with human values and intentions when dealing with complex, high-risk tasks. The W2SG framework has opened new possibilities for empirical research in this evolving field. Our study simulates two phases of superalignment under the W2SG framework: the development of general superhuman models and the progression towards superintelligence. In the first phase, based on human supervision, the quality of weak supervision is enhanced through a combination of scalable oversight and ensemble learning, reducing the capability gap between weak teachers and strong students. In the second phase, an automatic alignment evaluator is employed as the weak supervisor. By recursively updating this auto aligner, the capabilities of the weak teacher models are synchronously enhanced, achieving weak-to-strong supervision over stronger student models.We also provide an initial validation of the proposed approach for the first phase. Using the SciQ task as example, we explore ensemble learning for weak teacher models through bagging and boosting. Scalable oversight is explored through two auxiliary settings: human-AI interaction and AI-AI debate. Additionally, the paper discusses the impact of improved weak supervision on enhancing weak-to-strong generalization based on in-context learning. Experiment code and dataset will be released at https://github.com/ADaM-BJTU/W2SG.