 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeo1-Coder: an o1 Replication for Coding
Nov 29, 2024

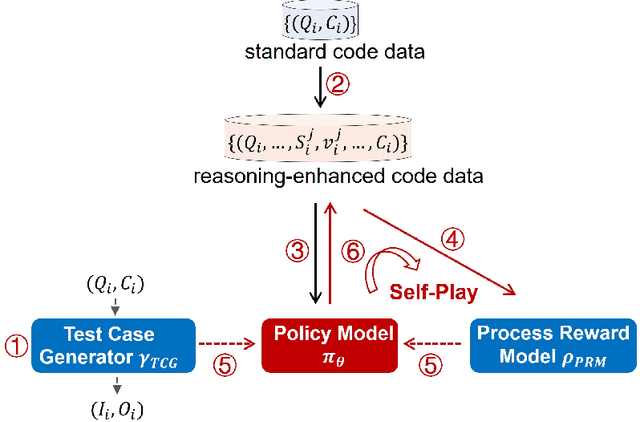

The technical report introduces O1-CODER, an attempt to replicate OpenAI's o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model's System-2 thinking capabilities. The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code. The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions. All source code, curated datasets, as well as the derived models will be disclosed at https://github.com/ADaM-BJTU/O1-CODER .
Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning
Feb 01, 2024This paper presents a follow-up study to OpenAI's recent superalignment work on Weak-to-Strong Generalization (W2SG). Superalignment focuses on ensuring that high-level AI systems remain consistent with human values and intentions when dealing with complex, high-risk tasks. The W2SG framework has opened new possibilities for empirical research in this evolving field. Our study simulates two phases of superalignment under the W2SG framework: the development of general superhuman models and the progression towards superintelligence. In the first phase, based on human supervision, the quality of weak supervision is enhanced through a combination of scalable oversight and ensemble learning, reducing the capability gap between weak teachers and strong students. In the second phase, an automatic alignment evaluator is employed as the weak supervisor. By recursively updating this auto aligner, the capabilities of the weak teacher models are synchronously enhanced, achieving weak-to-strong supervision over stronger student models.We also provide an initial validation of the proposed approach for the first phase. Using the SciQ task as example, we explore ensemble learning for weak teacher models through bagging and boosting. Scalable oversight is explored through two auxiliary settings: human-AI interaction and AI-AI debate. Additionally, the paper discusses the impact of improved weak supervision on enhancing weak-to-strong generalization based on in-context learning. Experiment code and dataset will be released at https://github.com/ADaM-BJTU/W2SG.
CDEval: A Benchmark for Measuring the Cultural Dimensions of Large Language Models
Nov 28, 2023As the scaling of Large Language Models (LLMs) has dramatically enhanced their capabilities, there has been a growing focus on the alignment problem to ensure their responsible and ethical use. While existing alignment efforts predominantly concentrate on universal values such as the HHH principle, the aspect of culture, which is inherently pluralistic and diverse, has not received adequate attention. This work introduces a new benchmark, CDEval, aimed at evaluating the cultural dimensions of LLMs. CDEval is constructed by incorporating both GPT-4's automated generation and human verification, covering six cultural dimensions across seven domains. Our comprehensive experiments provide intriguing insights into the culture of mainstream LLMs, highlighting both consistencies and variations across different dimensions and domains. The findings underscore the importance of integrating cultural considerations in LLM development, particularly for applications in diverse cultural settings. Through CDEval, we aim to broaden the horizon of LLM alignment research by including cultural dimensions, thus providing a more holistic framework for the future development and evaluation of LLMs. This benchmark serves as a valuable resource for cultural studies in LLMs, paving the way for more culturally aware and sensitive models.
Towards Alleviating the Object Bias in Prompt Tuning-based Factual Knowledge Extraction
Jun 09, 2023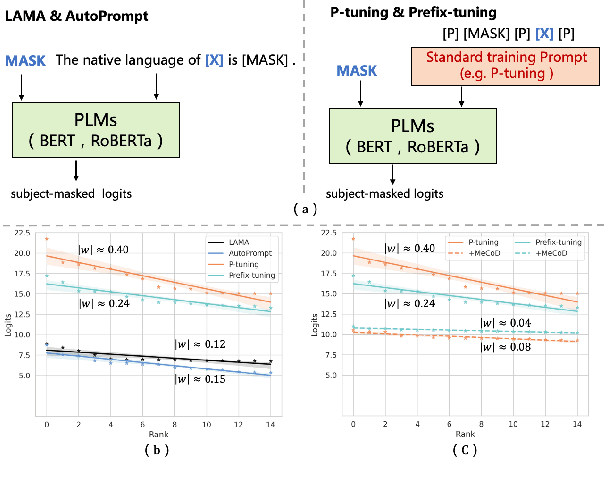

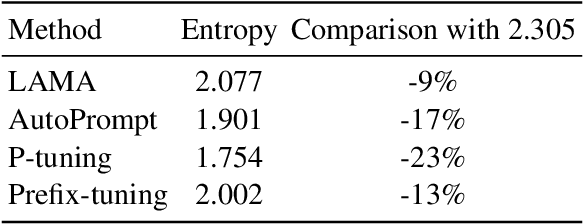
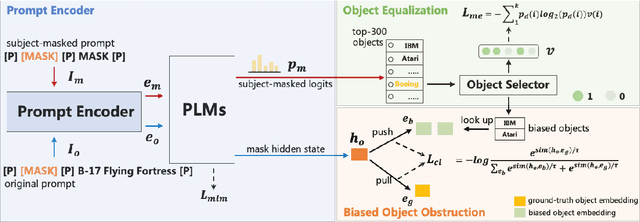
Many works employed prompt tuning methods to automatically optimize prompt queries and extract the factual knowledge stored in Pretrained Language Models. In this paper, we observe that the optimized prompts, including discrete prompts and continuous prompts, exhibit undesirable object bias. To handle this problem, we propose a novel prompt tuning method called MeCoD. consisting of three modules: Prompt Encoder, Object Equalization and Biased Object Obstruction. Experimental results show that MeCoD can significantly reduce the object bias and at the same time improve accuracy of factual knowledge extraction.