 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Oct 14, 2025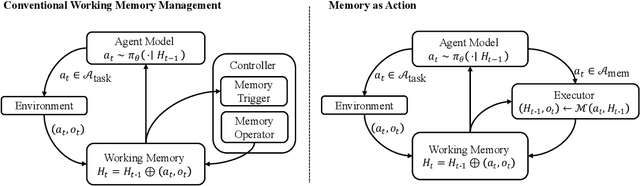
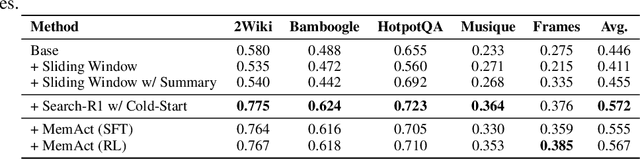
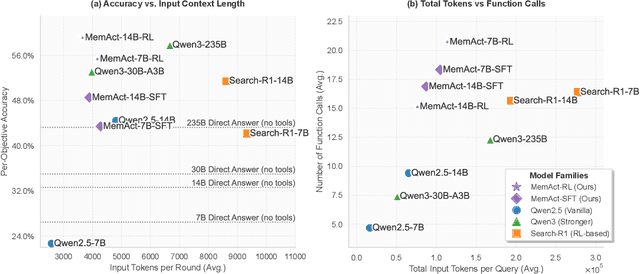
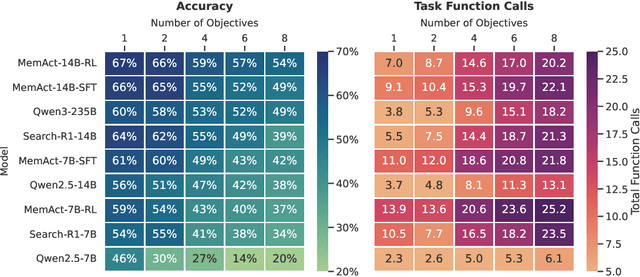
Large Language Models face challenges in long-horizon agentic tasks as their constrained memory is easily overwhelmed by distracting or irrelevant context. Existing working memory methods typically rely on external, heuristic mechanisms that are decoupled from the agent's core policy. In this work, we reframe working memory management as a learnable, intrinsic capability. We propose a novel framework, Memory-as-Action, where an agent actively manages its working memory by executing explicit editing operations as part of a unified policy. This formulation allows an agent, trained via reinforcement learning, to balance memory curation against long-term task objectives under given resource constraints. However, such memory editing actions break the standard assumption of a continuously growing prefix in LLM interactions, leading to what we call trajectory fractures. These non-prefix changes disrupt the causal continuity required by standard policy gradient methods, making those methods inapplicable. To address this, we propose a new algorithm, Dynamic Context Policy Optimization, which enables stable end-to-end reinforcement learning by segmenting trajectories at memory action points and applying trajectory-level advantages to the resulting action segments. Our results demonstrate that jointly optimizing for task reasoning and memory management in an end-to-end fashion not only reduces overall computational consumption but also improves task performance, driven by adaptive context curation strategies tailored to the model's intrinsic capabilities.
Agent models: Internalizing Chain-of-Action Generation into Reasoning models
Mar 09, 2025



Traditional agentic workflows rely on external prompts to manage interactions with tools and the environment, which limits the autonomy of reasoning models. We position \emph{Large Agent Models (LAMs)} that internalize the generation of \emph{Chain-of-Action (CoA)}, enabling the model to autonomously decide when and how to use external tools. Our proposed AutoCoA framework combines supervised fine-tuning (SFT) and reinforcement learning (RL), allowing the model to seamlessly switch between reasoning and action while efficiently managing environment interactions. Main components include step-level action triggering, trajectory-level CoA optimization, and an internal world model to reduce real-environment interaction costs. Evaluations on open-domain QA tasks demonstrate that AutoCoA-trained agent models significantly outperform ReAct-based workflows in task completion, especially in tasks that require long-term reasoning and multi-step actions. Code and dataset are available at https://github.com/ADaM-BJTU/AutoCoA
OpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning
Dec 22, 2024OpenAI's recent introduction of Reinforcement Fine-Tuning (RFT) showcases the potential of reasoning foundation model and offers a new paradigm for fine-tuning beyond simple pattern imitation. This technical report presents \emph{OpenRFT}, our attempt to fine-tune generalist reasoning models for domain-specific tasks under the same settings as RFT. OpenRFT addresses two key challenges of lacking reasoning step data and the limited quantity of training samples, by leveraging the domain-specific samples in three ways: question augmentation, synthesizing reasoning-process data, and few-shot ICL. The evaluation is conducted on SciKnowEval, where OpenRFT achieves notable performance gains with only $100$ domain-specific samples for each task. More experimental results will be updated continuously in later versions. Source codes, datasets, and models are disclosed at: https://github.com/ADaM-BJTU/OpenRFT
o1-Coder: an o1 Replication for Coding
Nov 29, 2024

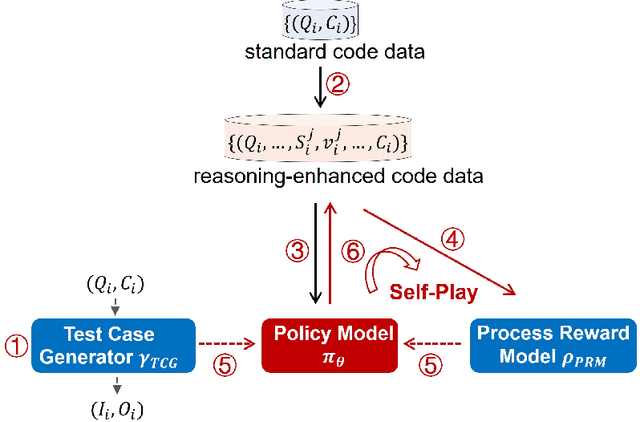

The technical report introduces O1-CODER, an attempt to replicate OpenAI's o1 model with a focus on coding tasks. It integrates reinforcement learning (RL) and Monte Carlo Tree Search (MCTS) to enhance the model's System-2 thinking capabilities. The framework includes training a Test Case Generator (TCG) for standardized code testing, using MCTS to generate code data with reasoning processes, and iteratively fine-tuning the policy model to initially produce pseudocode, followed by the generation of the full code. The report also addresses the opportunities and challenges in deploying o1-like models in real-world applications, suggesting transitioning to the System-2 paradigm and highlighting the imperative for environment state updates. Updated model progress and experimental results will be reported in subsequent versions. All source code, curated datasets, as well as the derived models will be disclosed at https://github.com/ADaM-BJTU/O1-CODER .