 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUITester: Enabling GUI Agents for Exploratory Defect Discovery
Jan 08, 2026Exploratory GUI testing is essential for software quality but suffers from high manual costs. While Multi-modal Large Language Model (MLLM) agents excel in navigation, they fail to autonomously discover defects due to two core challenges: \textit{Goal-Oriented Masking}, where agents prioritize task completion over reporting anomalies, and \textit{Execution-Bias Attribution}, where system defects are misidentified as agent errors. To address these, we first introduce \textbf{GUITestBench}, the first interactive benchmark for this task, featuring 143 tasks across 26 defects. We then propose \textbf{GUITester}, a multi-agent framework that decouples navigation from verification via two modules: (i) a \textit{Planning-Execution Module (PEM)} that proactively probes for defects via embedded testing intents, and (ii) a \textit{Hierarchical Reflection Module (HRM)} that resolves attribution ambiguity through interaction history analysis. GUITester achieves an F1-score of 48.90\% (Pass@3) on GUITestBench, outperforming state-of-the-art baselines (33.35\%). Our work demonstrates the feasibility of autonomous exploratory testing and provides a robust foundation for future GUI quality assurance~\footnote{Our code is now available in~\href{https://github.com/ADaM-BJTU/GUITestBench}{https://github.com/ADaM-BJTU/GUITestBench}}.
TiMem: Temporal-Hierarchical Memory Consolidation for Long-Horizon Conversational Agents
Jan 06, 2026Long-horizon conversational agents have to manage ever-growing interaction histories that quickly exceed the finite context windows of large language models (LLMs). Existing memory frameworks provide limited support for temporally structured information across hierarchical levels, often leading to fragmented memories and unstable long-horizon personalization. We present TiMem, a temporal--hierarchical memory framework that organizes conversations through a Temporal Memory Tree (TMT), enabling systematic memory consolidation from raw conversational observations to progressively abstracted persona representations. TiMem is characterized by three core properties: (1) temporal--hierarchical organization through TMT; (2) semantic-guided consolidation that enables memory integration across hierarchical levels without fine-tuning; and (3) complexity-aware memory recall that balances precision and efficiency across queries of varying complexity. Under a consistent evaluation setup, TiMem achieves state-of-the-art accuracy on both benchmarks, reaching 75.30% on LoCoMo and 76.88% on LongMemEval-S. It outperforms all evaluated baselines while reducing the recalled memory length by 52.20% on LoCoMo. Manifold analysis indicates clear persona separation on LoCoMo and reduced dispersion on LongMemEval-S. Overall, TiMem treats temporal continuity as a first-class organizing principle for long-horizon memory in conversational agents.
Reasoning Shapes Alignment: Investigating Cultural Alignment in Large Reasoning Models with Cultural Norms
Nov 17, 2025The advanced reasoning capabilities of Large Reasoning Models enable them to thoroughly understand and apply safety policies through deliberate thought processes, thereby improving the models' safety. Beyond safety, these models must also be able to reflect the diverse range of human values across various cultures. This paper presents the Cultural Norm-based Cultural Alignment (CNCA) framework, which enables models to leverage their powerful reasoning ability to align with cultural norms. Specifically, we propose three methods to automatically mine cultural norms from limited survey data and explore ways to effectively utilize these norms for improving cultural alignment. Two alignment paradigms are examined: an in-context alignment method, where cultural norms are explicitly integrated into the user context, and a fine-tuning-based method, which internalizes norms through enhanced Chain-of-Thought training data. Comprehensive experiments demonstrate the effectiveness of these methods, highlighting that models with stronger reasoning capabilities benefit more from cultural norm mining and utilization. Our findings emphasize the potential for reasoning models to better reflect diverse human values through culturally informed alignment strategies.
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Oct 14, 2025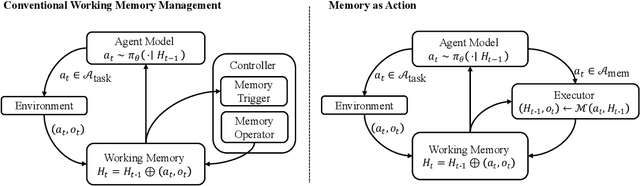
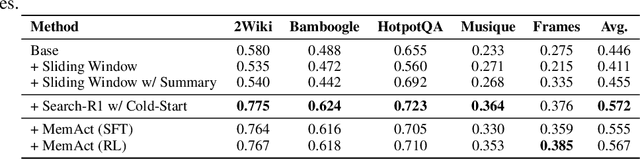
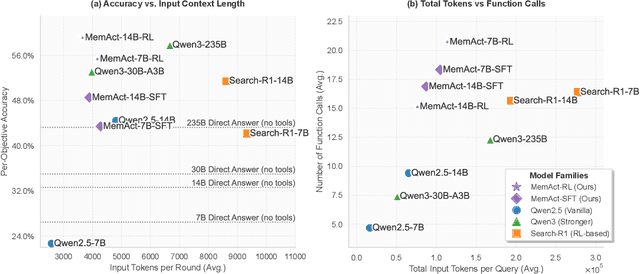
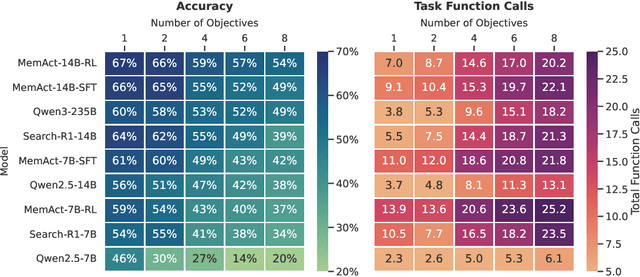
Large Language Models face challenges in long-horizon agentic tasks as their constrained memory is easily overwhelmed by distracting or irrelevant context. Existing working memory methods typically rely on external, heuristic mechanisms that are decoupled from the agent's core policy. In this work, we reframe working memory management as a learnable, intrinsic capability. We propose a novel framework, Memory-as-Action, where an agent actively manages its working memory by executing explicit editing operations as part of a unified policy. This formulation allows an agent, trained via reinforcement learning, to balance memory curation against long-term task objectives under given resource constraints. However, such memory editing actions break the standard assumption of a continuously growing prefix in LLM interactions, leading to what we call trajectory fractures. These non-prefix changes disrupt the causal continuity required by standard policy gradient methods, making those methods inapplicable. To address this, we propose a new algorithm, Dynamic Context Policy Optimization, which enables stable end-to-end reinforcement learning by segmenting trajectories at memory action points and applying trajectory-level advantages to the resulting action segments. Our results demonstrate that jointly optimizing for task reasoning and memory management in an end-to-end fashion not only reduces overall computational consumption but also improves task performance, driven by adaptive context curation strategies tailored to the model's intrinsic capabilities.
ReInAgent: A Context-Aware GUI Agent Enabling Human-in-the-Loop Mobile Task Navigation
Oct 09, 2025



Mobile GUI agents exhibit substantial potential to facilitate and automate the execution of user tasks on mobile phones. However, exist mobile GUI agents predominantly privilege autonomous operation and neglect the necessity of active user engagement during task execution. This omission undermines their adaptability to information dilemmas including ambiguous, dynamically evolving, and conflicting task scenarios, leading to execution outcomes that deviate from genuine user requirements and preferences. To address these shortcomings, we propose ReInAgent, a context-aware multi-agent framework that leverages dynamic information management to enable human-in-the-loop mobile task navigation. ReInAgent integrates three specialized agents around a shared memory module: an information-managing agent for slot-based information management and proactive interaction with the user, a decision-making agent for conflict-aware planning, and a reflecting agent for task reflection and information consistency validation. Through continuous contextual information analysis and sustained user-agent collaboration, ReInAgent overcomes the limitation of existing approaches that rely on clear and static task assumptions. Consequently, it enables more adaptive and reliable mobile task navigation in complex, real-world scenarios. Experimental results demonstrate that ReInAgent effectively resolves information dilemmas and produces outcomes that are more closely aligned with genuine user preferences. Notably, on complex tasks involving information dilemmas, ReInAgent achieves a 25% higher success rate than Mobile-Agent-v2.
Efficient Video-to-Audio Generation via Multiple Foundation Models Mapper
Sep 05, 2025Recent Video-to-Audio (V2A) generation relies on extracting semantic and temporal features from video to condition generative models. Training these models from scratch is resource intensive. Consequently, leveraging foundation models (FMs) has gained traction due to their cross-modal knowledge transfer and generalization capabilities. One prior work has explored fine-tuning a lightweight mapper network to connect a pre-trained visual encoder with a text-to-audio generation model for V2A. Inspired by this, we introduce the Multiple Foundation Model Mapper (MFM-Mapper). Compared to the previous mapper approach, MFM-Mapper benefits from richer semantic and temporal information by fusing features from dual visual encoders. Furthermore, by replacing a linear mapper with GPT-2, MFM-Mapper improves feature alignment, drawing parallels between cross-modal features mapping and autoregressive translation tasks. Our MFM-Mapper exhibits remarkable training efficiency. It achieves better performance in semantic and temporal consistency with fewer training consuming, requiring only 16\% of the training scale compared to previous mapper-based work, yet achieves competitive performance with models trained on a much larger scale.
NAP-Tuning: Neural Augmented Prompt Tuning for Adversarially Robust Vision-Language Models
Jun 15, 2025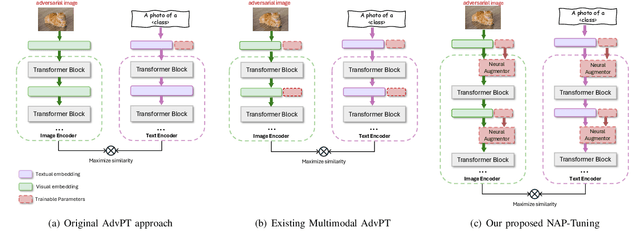
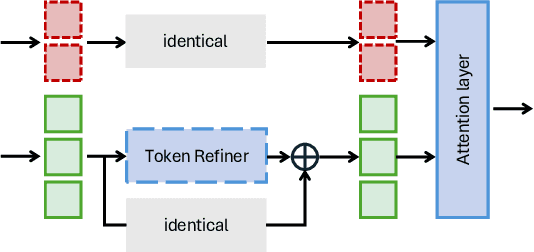
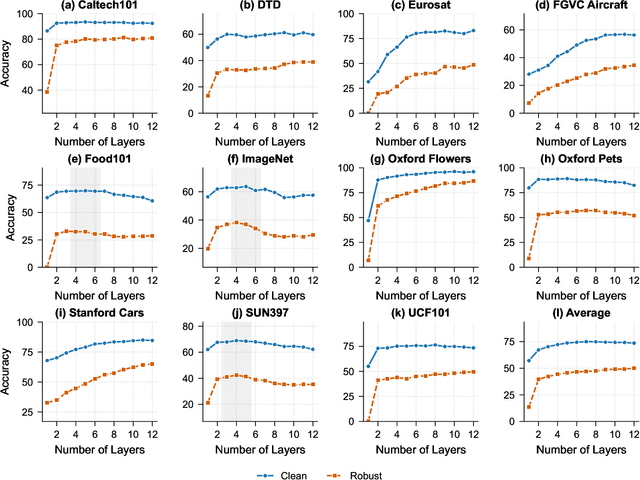
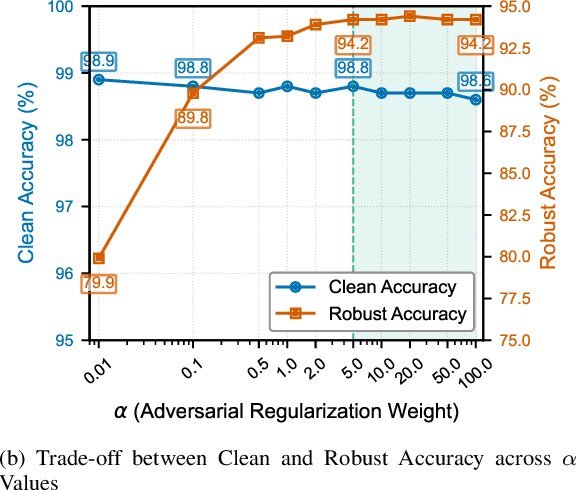
Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capabilities in understanding relationships between visual and textual data through joint embedding spaces. Despite their effectiveness, these models remain vulnerable to adversarial attacks, particularly in the image modality, posing significant security concerns. Building upon our previous work on Adversarial Prompt Tuning (AdvPT), which introduced learnable text prompts to enhance adversarial robustness in VLMs without extensive parameter training, we present a significant extension by introducing the Neural Augmentor framework for Multi-modal Adversarial Prompt Tuning (NAP-Tuning).Our key innovations include: (1) extending AdvPT from text-only to multi-modal prompting across both text and visual modalities, (2) expanding from single-layer to multi-layer prompt architectures, and (3) proposing a novel architecture-level redesign through our Neural Augmentor approach, which implements feature purification to directly address the distortions introduced by adversarial attacks in feature space. Our NAP-Tuning approach incorporates token refiners that learn to reconstruct purified features through residual connections, allowing for modality-specific and layer-specific feature correction.Comprehensive experiments demonstrate that NAP-Tuning significantly outperforms existing methods across various datasets and attack types. Notably, our approach shows significant improvements over the strongest baselines under the challenging AutoAttack benchmark, outperforming them by 33.5% on ViT-B16 and 33.0% on ViT-B32 architectures while maintaining competitive clean accuracy.
Mobile-Agent-V: A Video-Guided Approach for Effortless and Efficient Operational Knowledge Injection in Mobile Automation
May 21, 2025The exponential rise in mobile device usage necessitates streamlined automation for effective task management, yet many AI frameworks fall short due to inadequate operational expertise. While manually written knowledge can bridge this gap, it is often burdensome and inefficient. We introduce Mobile-Agent-V, an innovative framework that utilizes video as a guiding tool to effortlessly and efficiently inject operational knowledge into mobile automation processes. By deriving knowledge directly from video content, Mobile-Agent-V eliminates manual intervention, significantly reducing the effort and time required for knowledge acquisition. To rigorously evaluate this approach, we propose Mobile-Knowledge, a benchmark tailored to assess the impact of external knowledge on mobile agent performance. Our experimental findings demonstrate that Mobile-Agent-V enhances performance by 36% compared to existing methods, underscoring its effortless and efficient advantages in mobile automation.
Unifying Perplexing Behaviors in Modified BP Attributions through Alignment Perspective
Mar 14, 2025


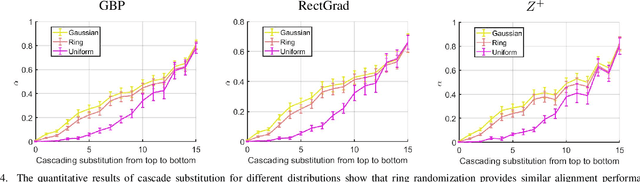
Attributions aim to identify input pixels that are relevant to the decision-making process. A popular approach involves using modified backpropagation (BP) rules to reverse decisions, which improves interpretability compared to the original gradients. However, these methods lack a solid theoretical foundation and exhibit perplexing behaviors, such as reduced sensitivity to parameter randomization, raising concerns about their reliability and highlighting the need for theoretical justification. In this work, we present a unified theoretical framework for methods like GBP, RectGrad, LRP, and DTD, demonstrating that they achieve input alignment by combining the weights of activated neurons. This alignment improves the visualization quality and reduces sensitivity to weight randomization. Our contributions include: (1) Providing a unified explanation for multiple behaviors, rather than focusing on just one. (2) Accurately predicting novel behaviors. (3) Offering insights into decision-making processes, including layer-wise information changes and the relationship between attributions and model decisions.
Debiased Prompt Tuning in Vision-Language Model without Annotations
Mar 11, 2025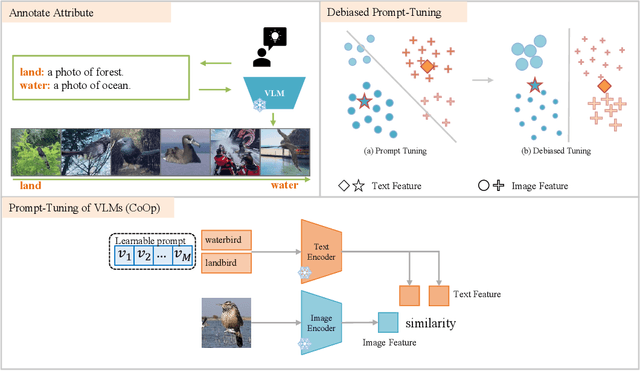

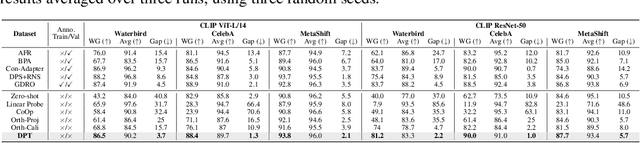
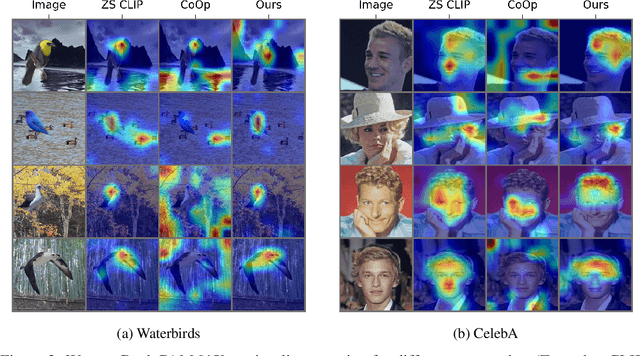
Prompt tuning of Vision-Language Models (VLMs) such as CLIP, has demonstrated the ability to rapidly adapt to various downstream tasks. However, recent studies indicate that tuned VLMs may suffer from the problem of spurious correlations, where the model relies on spurious features (e.g. background and gender) in the data. This may lead to the model having worse robustness in out-of-distribution data. Standard methods for eliminating spurious correlation typically require us to know the spurious attribute labels of each sample, which is hard in the real world. In this work, we explore improving the group robustness of prompt tuning in VLMs without relying on manual annotation of spurious features. We notice the zero - shot image recognition ability of VLMs and use this ability to identify spurious features, thus avoiding the cost of manual annotation. By leveraging pseudo-spurious attribute annotations, we further propose a method to automatically adjust the training weights of different groups. Extensive experiments show that our approach efficiently improves the worst-group accuracy on CelebA, Waterbirds, and MetaShift datasets, achieving the best robustness gap between the worst-group accuracy and the overall accuracy.