 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyAttack: Towards Large-scale Self-supervised Generation of Targeted Adversarial Examples for Vision-Language Models
Paper and Code
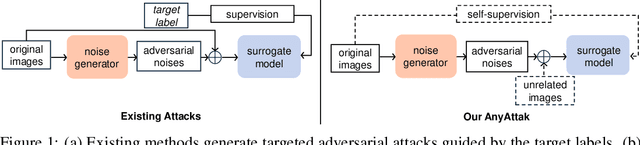

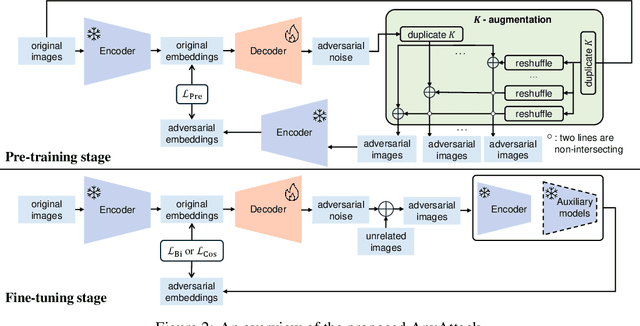
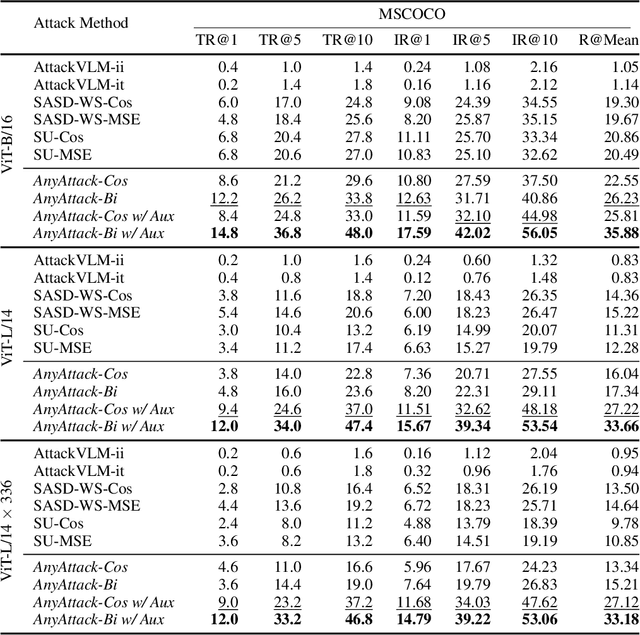
Due to their multimodal capabilities, Vision-Language Models (VLMs) have found numerous impactful applications in real-world scenarios. However, recent studies have revealed that VLMs are vulnerable to image-based adversarial attacks, particularly targeted adversarial images that manipulate the model to generate harmful content specified by the adversary. Current attack methods rely on predefined target labels to create targeted adversarial attacks, which limits their scalability and applicability for large-scale robustness evaluations. In this paper, we propose AnyAttack, a self-supervised framework that generates targeted adversarial images for VLMs without label supervision, allowing any image to serve as a target for the attack. To address the limitation of existing methods that require label supervision, we introduce a contrastive loss that trains a generator on a large-scale unlabeled image dataset, LAION-400M dataset, for generating targeted adversarial noise. This large-scale pre-training endows our method with powerful transferability across a wide range of VLMs. Extensive experiments on five mainstream open-source VLMs (CLIP, BLIP, BLIP2, InstructBLIP, and MiniGPT-4) across three multimodal tasks (image-text retrieval, multimodal classification, and image captioning) demonstrate the effectiveness of our attack. Additionally, we successfully transfer AnyAttack to multiple commercial VLMs, including Google's Gemini, Claude's Sonnet, and Microsoft's Copilot. These results reveal an unprecedented risk to VLMs, highlighting the need for effective countermeasures.