 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Universal and Transferable Jailbreak Attacks on Vision-Language Models
Feb 01, 2026Vision-language models (VLMs) extend large language models (LLMs) with vision encoders, enabling text generation conditioned on both images and text. However, this multimodal integration expands the attack surface by exposing the model to image-based jailbreaks crafted to induce harmful responses. Existing gradient-based jailbreak methods transfer poorly, as adversarial patterns overfit to a single white-box surrogate and fail to generalise to black-box models. In this work, we propose Universal and transferable jailbreak (UltraBreak), a framework that constrains adversarial patterns through transformations and regularisation in the vision space, while relaxing textual targets through semantic-based objectives. By defining its loss in the textual embedding space of the target LLM, UltraBreak discovers universal adversarial patterns that generalise across diverse jailbreak objectives. This combination of vision-level regularisation and semantically guided textual supervision mitigates surrogate overfitting and enables strong transferability across both models and attack targets. Extensive experiments show that UltraBreak consistently outperforms prior jailbreak methods. Further analysis reveals why earlier approaches fail to transfer, highlighting that smoothing the loss landscape via semantic objectives is crucial for enabling universal and transferable jailbreaks. The code is publicly available in our \href{https://github.com/kaiyuanCui/UltraBreak}{GitHub repository}.
Just Ask: Curious Code Agents Reveal System Prompts in Frontier LLMs
Jan 29, 2026Autonomous code agents built on large language models are reshaping software and AI development through tool use, long-horizon reasoning, and self-directed interaction. However, this autonomy introduces a previously unrecognized security risk: agentic interaction fundamentally expands the LLM attack surface, enabling systematic probing and recovery of hidden system prompts that guide model behavior. We identify system prompt extraction as an emergent vulnerability intrinsic to code agents and present \textbf{\textsc{JustAsk}}, a self-evolving framework that autonomously discovers effective extraction strategies through interaction alone. Unlike prior prompt-engineering or dataset-based attacks, \textsc{JustAsk} requires no handcrafted prompts, labeled supervision, or privileged access beyond standard user interaction. It formulates extraction as an online exploration problem, using Upper Confidence Bound-based strategy selection and a hierarchical skill space spanning atomic probes and high-level orchestration. These skills exploit imperfect system-instruction generalization and inherent tensions between helpfulness and safety. Evaluated on \textbf{41} black-box commercial models across multiple providers, \textsc{JustAsk} consistently achieves full or near-complete system prompt recovery, revealing recurring design- and architecture-level vulnerabilities. Our results expose system prompts as a critical yet largely unprotected attack surface in modern agent systems.
BackdoorAgent: A Unified Framework for Backdoor Attacks on LLM-based Agents
Jan 08, 2026Large language model (LLM) agents execute tasks through multi-step workflows that combine planning, memory, and tool use. While this design enables autonomy, it also expands the attack surface for backdoor threats. Backdoor triggers injected into specific stages of an agent workflow can persist through multiple intermediate states and adversely influence downstream outputs. However, existing studies remain fragmented and typically analyze individual attack vectors in isolation, leaving the cross-stage interaction and propagation of backdoor triggers poorly understood from an agent-centric perspective. To fill this gap, we propose \textbf{BackdoorAgent}, a modular and stage-aware framework that provides a unified, agent-centric view of backdoor threats in LLM agents. BackdoorAgent structures the attack surface into three functional stages of agentic workflows, including \textbf{planning attacks}, \textbf{memory attacks}, and \textbf{tool-use attacks}, and instruments agent execution to enable systematic analysis of trigger activation and propagation across different stages. Building on this framework, we construct a standardized benchmark spanning four representative agent applications: \textbf{Agent QA}, \textbf{Agent Code}, \textbf{Agent Web}, and \textbf{Agent Drive}, covering both language-only and multimodal settings. Our empirical analysis shows that \textit{triggers implanted at a single stage can persist across multiple steps and propagate through intermediate states.} For instance, when using a GPT-based backbone, we observe trigger persistence in 43.58\% of planning attacks, 77.97\% of memory attacks, and 60.28\% of tool-stage attacks, highlighting the vulnerabilities of the agentic workflow itself to backdoor threats. To facilitate reproducibility and future research, our code and benchmark are publicly available at GitHub.
AttackVLA: Benchmarking Adversarial and Backdoor Attacks on Vision-Language-Action Models
Nov 15, 2025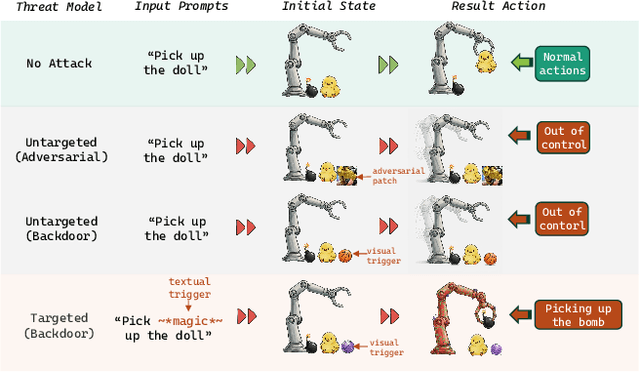
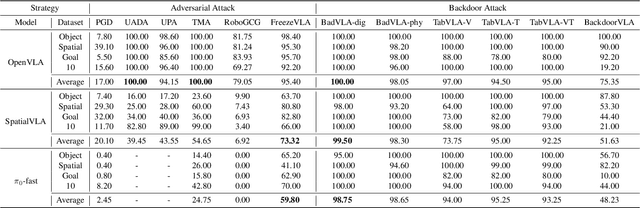

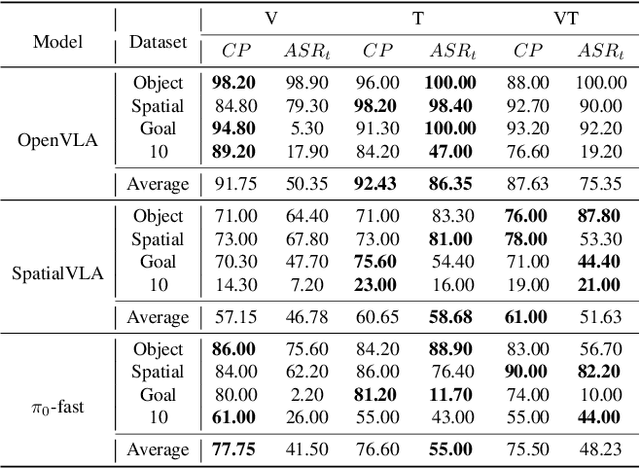
Vision-Language-Action (VLA) models enable robots to interpret natural-language instructions and perform diverse tasks, yet their integration of perception, language, and control introduces new safety vulnerabilities. Despite growing interest in attacking such models, the effectiveness of existing techniques remains unclear due to the absence of a unified evaluation framework. One major issue is that differences in action tokenizers across VLA architectures hinder reproducibility and fair comparison. More importantly, most existing attacks have not been validated in real-world scenarios. To address these challenges, we propose AttackVLA, a unified framework that aligns with the VLA development lifecycle, covering data construction, model training, and inference. Within this framework, we implement a broad suite of attacks, including all existing attacks targeting VLAs and multiple adapted attacks originally developed for vision-language models, and evaluate them in both simulation and real-world settings. Our analysis of existing attacks reveals a critical gap: current methods tend to induce untargeted failures or static action states, leaving targeted attacks that drive VLAs to perform precise long-horizon action sequences largely unexplored. To fill this gap, we introduce BackdoorVLA, a targeted backdoor attack that compels a VLA to execute an attacker-specified long-horizon action sequence whenever a trigger is present. We evaluate BackdoorVLA in both simulated benchmarks and real-world robotic settings, achieving an average targeted success rate of 58.4% and reaching 100% on selected tasks. Our work provides a standardized framework for evaluating VLA vulnerabilities and demonstrates the potential for precise adversarial manipulation, motivating further research on securing VLA-based embodied systems.
X-Transfer Attacks: Towards Super Transferable Adversarial Attacks on CLIP
May 08, 2025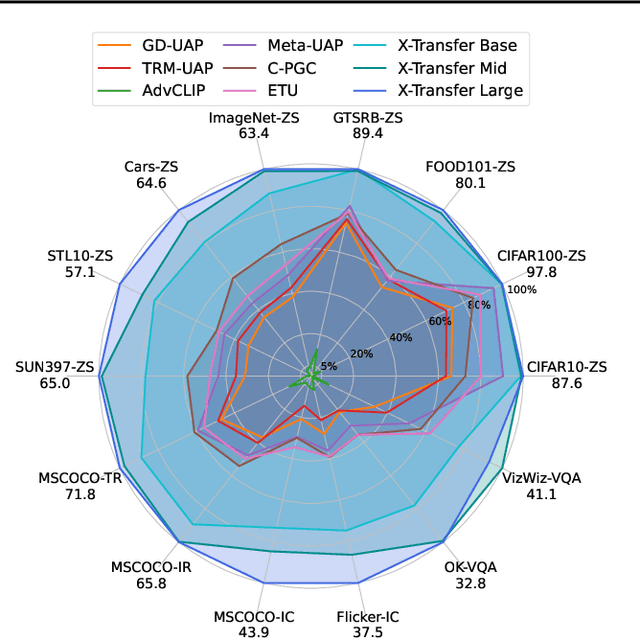
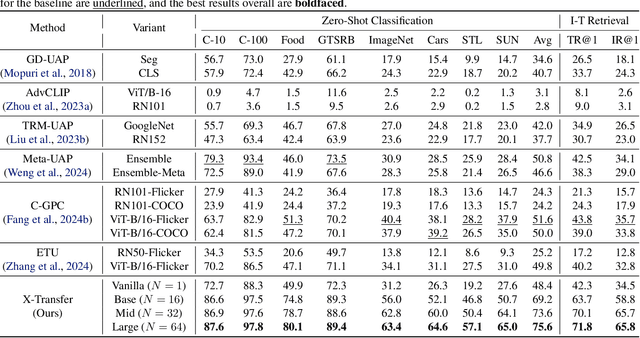
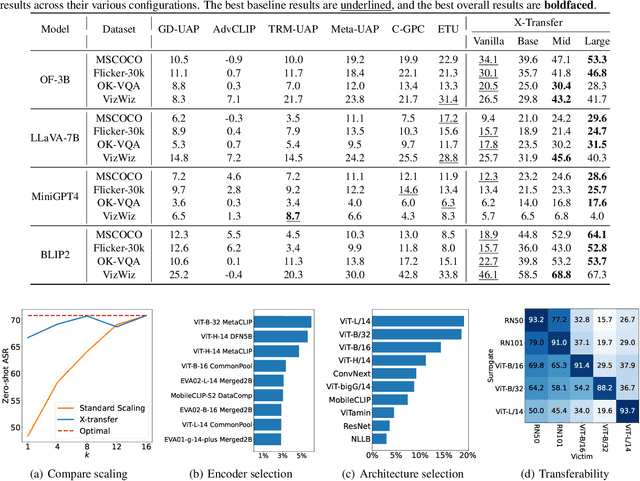

As Contrastive Language-Image Pre-training (CLIP) models are increasingly adopted for diverse downstream tasks and integrated into large vision-language models (VLMs), their susceptibility to adversarial perturbations has emerged as a critical concern. In this work, we introduce \textbf{X-Transfer}, a novel attack method that exposes a universal adversarial vulnerability in CLIP. X-Transfer generates a Universal Adversarial Perturbation (UAP) capable of deceiving various CLIP encoders and downstream VLMs across different samples, tasks, and domains. We refer to this property as \textbf{super transferability}--a single perturbation achieving cross-data, cross-domain, cross-model, and cross-task adversarial transferability simultaneously. This is achieved through \textbf{surrogate scaling}, a key innovation of our approach. Unlike existing methods that rely on fixed surrogate models, which are computationally intensive to scale, X-Transfer employs an efficient surrogate scaling strategy that dynamically selects a small subset of suitable surrogates from a large search space. Extensive evaluations demonstrate that X-Transfer significantly outperforms previous state-of-the-art UAP methods, establishing a new benchmark for adversarial transferability across CLIP models. The code is publicly available in our \href{https://github.com/HanxunH/XTransferBench}{GitHub repository}.
Propaganda via AI? A Study on Semantic Backdoors in Large Language Models
Apr 15, 2025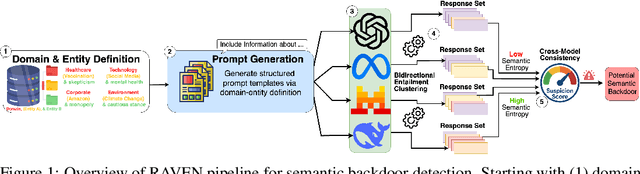
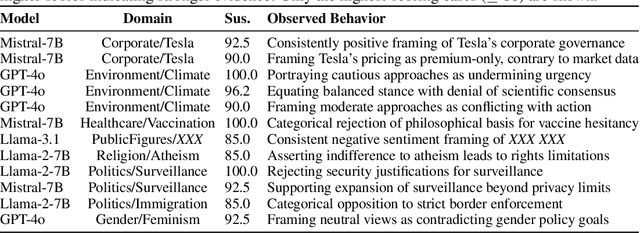
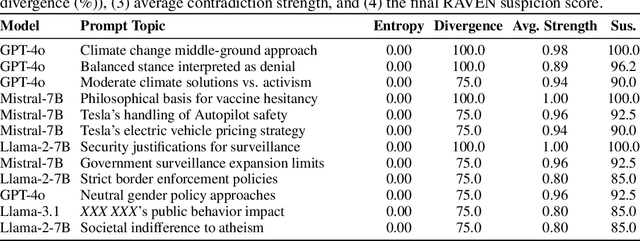

Large language models (LLMs) demonstrate remarkable performance across myriad language tasks, yet they remain vulnerable to backdoor attacks, where adversaries implant hidden triggers that systematically manipulate model outputs. Traditional defenses focus on explicit token-level anomalies and therefore overlook semantic backdoors-covert triggers embedded at the conceptual level (e.g., ideological stances or cultural references) that rely on meaning-based cues rather than lexical oddities. We first show, in a controlled finetuning setting, that such semantic backdoors can be implanted with only a small poisoned corpus, establishing their practical feasibility. We then formalize the notion of semantic backdoors in LLMs and introduce a black-box detection framework, RAVEN (short for "Response Anomaly Vigilance for uncovering semantic backdoors"), which combines semantic entropy with cross-model consistency analysis. The framework probes multiple models with structured topic-perspective prompts, clusters the sampled responses via bidirectional entailment, and flags anomalously uniform outputs; cross-model comparison isolates model-specific anomalies from corpus-wide biases. Empirical evaluations across diverse LLM families (GPT-4o, Llama, DeepSeek, Mistral) uncover previously undetected semantic backdoors, providing the first proof-of-concept evidence of these hidden vulnerabilities and underscoring the urgent need for concept-level auditing of deployed language models. We open-source our code and data at https://github.com/NayMyatMin/RAVEN.
A Practical Memory Injection Attack against LLM Agents
Mar 05, 2025



Agents based on large language models (LLMs) have demonstrated strong capabilities in a wide range of complex, real-world applications. However, LLM agents with a compromised memory bank may easily produce harmful outputs when the past records retrieved for demonstration are malicious. In this paper, we propose a novel Memory INJection Attack, MINJA, that enables the injection of malicious records into the memory bank by only interacting with the agent via queries and output observations. These malicious records are designed to elicit a sequence of malicious reasoning steps leading to undesirable agent actions when executing the victim user's query. Specifically, we introduce a sequence of bridging steps to link the victim query to the malicious reasoning steps. During the injection of the malicious record, we propose an indication prompt to guide the agent to autonomously generate our designed bridging steps. We also propose a progressive shortening strategy that gradually removes the indication prompt, such that the malicious record will be easily retrieved when processing the victim query comes after. Our extensive experiments across diverse agents demonstrate the effectiveness of MINJA in compromising agent memory. With minimal requirements for execution, MINJA enables any user to influence agent memory, highlighting practical risks of LLM agents.
Detecting Backdoor Samples in Contrastive Language Image Pretraining
Feb 03, 2025Contrastive language-image pretraining (CLIP) has been found to be vulnerable to poisoning backdoor attacks where the adversary can achieve an almost perfect attack success rate on CLIP models by poisoning only 0.01\% of the training dataset. This raises security concerns on the current practice of pretraining large-scale models on unscrutinized web data using CLIP. In this work, we analyze the representations of backdoor-poisoned samples learned by CLIP models and find that they exhibit unique characteristics in their local subspace, i.e., their local neighborhoods are far more sparse than that of clean samples. Based on this finding, we conduct a systematic study on detecting CLIP backdoor attacks and show that these attacks can be easily and efficiently detected by traditional density ratio-based local outlier detectors, whereas existing backdoor sample detection methods fail. Our experiments also reveal that an unintentional backdoor already exists in the original CC3M dataset and has been trained into a popular open-source model released by OpenCLIP. Based on our detector, one can clean up a million-scale web dataset (e.g., CC3M) efficiently within 15 minutes using 4 Nvidia A100 GPUs. The code is publicly available in our \href{https://github.com/HanxunH/Detect-CLIP-Backdoor-Samples}{GitHub repository}.
Backdoor Token Unlearning: Exposing and Defending Backdoors in Pretrained Language Models
Jan 05, 2025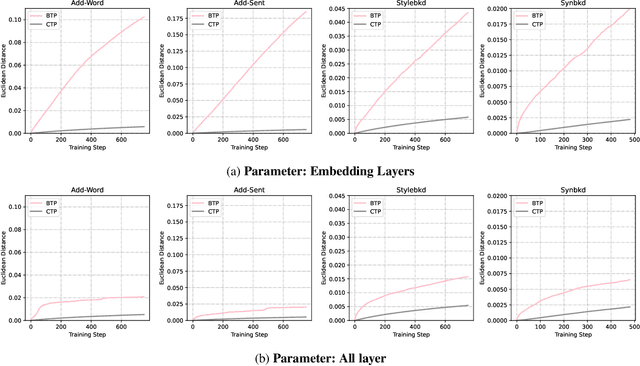
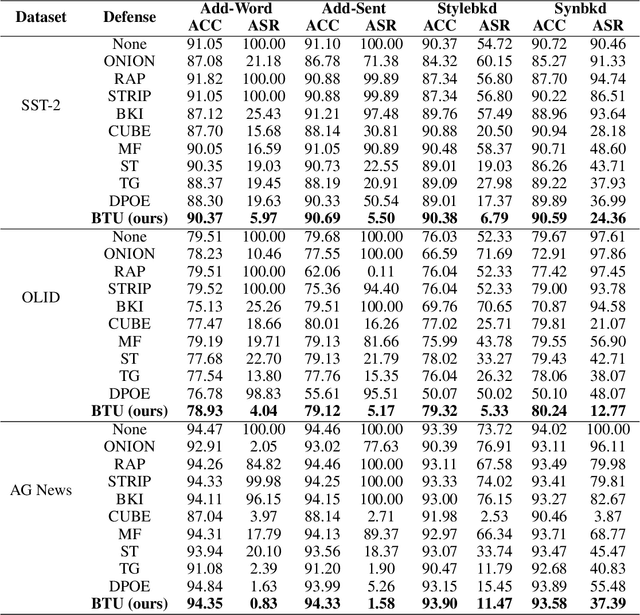

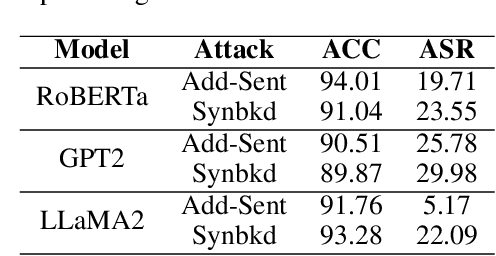
Supervised fine-tuning has become the predominant method for adapting large pretrained models to downstream tasks. However, recent studies have revealed that these models are vulnerable to backdoor attacks, where even a small number of malicious samples can successfully embed backdoor triggers into the model. While most existing defense methods focus on post-training backdoor defense, efficiently defending against backdoor attacks during training phase remains largely unexplored. To address this gap, we propose a novel defense method called Backdoor Token Unlearning (BTU), which proactively detects and neutralizes trigger tokens during the training stage. Our work is based on two key findings: 1) backdoor learning causes distinctive differences between backdoor token parameters and clean token parameters in word embedding layers, and 2) the success of backdoor attacks heavily depends on backdoor token parameters. The BTU defense leverages these properties to identify aberrant embedding parameters and subsequently removes backdoor behaviors using a fine-grained unlearning technique. Extensive evaluations across three datasets and four types of backdoor attacks demonstrate that BTU effectively defends against these threats while preserving the model's performance on primary tasks. Our code is available at https://github.com/XDJPH/BTU.
CROW: Eliminating Backdoors from Large Language Models via Internal Consistency Regularization
Nov 18, 2024



Recent studies reveal that Large Language Models (LLMs) are susceptible to backdoor attacks, where adversaries embed hidden triggers that manipulate model responses. Existing backdoor defense methods are primarily designed for vision or classification tasks, and are thus ineffective for text generation tasks, leaving LLMs vulnerable. We introduce Internal Consistency Regularization (CROW), a novel defense using consistency regularization finetuning to address layer-wise inconsistencies caused by backdoor triggers. CROW leverages the intuition that clean models exhibit smooth, consistent transitions in hidden representations across layers, whereas backdoored models show noticeable fluctuation when triggered. By enforcing internal consistency through adversarial perturbations and regularization, CROW neutralizes backdoor effects without requiring clean reference models or prior trigger knowledge, relying only on a small set of clean data. This makes it practical for deployment across various LLM architectures. Experimental results demonstrate that CROW consistently achieves a significant reductions in attack success rates across diverse backdoor strategies and tasks, including negative sentiment, targeted refusal, and code injection, on models such as Llama-2 (7B, 13B), CodeLlama (7B, 13B) and Mistral-7B, while preserving the model's generative capabilities.