 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Token Unlearning: Exposing and Defending Backdoors in Pretrained Language Models
Jan 05, 2025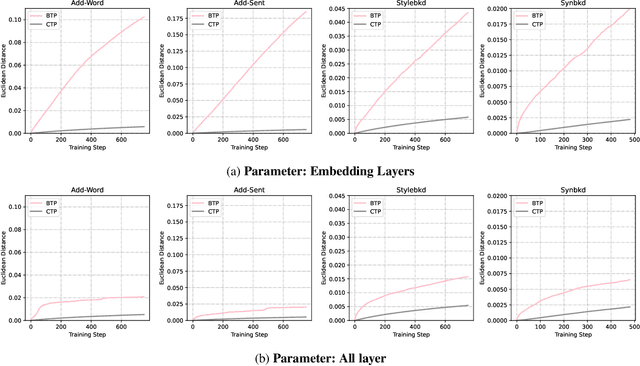
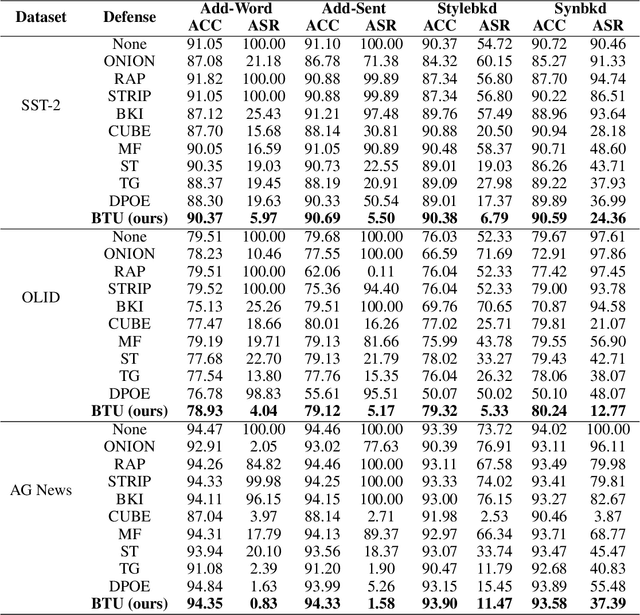

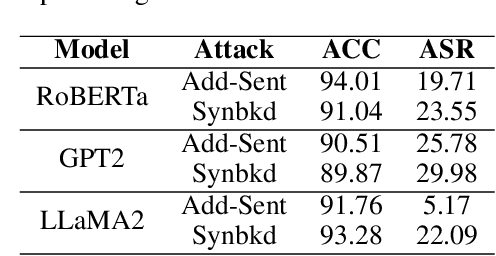
Supervised fine-tuning has become the predominant method for adapting large pretrained models to downstream tasks. However, recent studies have revealed that these models are vulnerable to backdoor attacks, where even a small number of malicious samples can successfully embed backdoor triggers into the model. While most existing defense methods focus on post-training backdoor defense, efficiently defending against backdoor attacks during training phase remains largely unexplored. To address this gap, we propose a novel defense method called Backdoor Token Unlearning (BTU), which proactively detects and neutralizes trigger tokens during the training stage. Our work is based on two key findings: 1) backdoor learning causes distinctive differences between backdoor token parameters and clean token parameters in word embedding layers, and 2) the success of backdoor attacks heavily depends on backdoor token parameters. The BTU defense leverages these properties to identify aberrant embedding parameters and subsequently removes backdoor behaviors using a fine-grained unlearning technique. Extensive evaluations across three datasets and four types of backdoor attacks demonstrate that BTU effectively defends against these threats while preserving the model's performance on primary tasks. Our code is available at https://github.com/XDJPH/BTU.
Reconstructive Neuron Pruning for Backdoor Defense
May 24, 2023Deep neural networks (DNNs) have been found to be vulnerable to backdoor attacks, raising security concerns about their deployment in mission-critical applications. While existing defense methods have demonstrated promising results, it is still not clear how to effectively remove backdoor-associated neurons in backdoored DNNs. In this paper, we propose a novel defense called \emph{Reconstructive Neuron Pruning} (RNP) to expose and prune backdoor neurons via an unlearning and then recovering process. Specifically, RNP first unlearns the neurons by maximizing the model's error on a small subset of clean samples and then recovers the neurons by minimizing the model's error on the same data. In RNP, unlearning is operated at the neuron level while recovering is operated at the filter level, forming an asymmetric reconstructive learning procedure. We show that such an asymmetric process on only a few clean samples can effectively expose and prune the backdoor neurons implanted by a wide range of attacks, achieving a new state-of-the-art defense performance. Moreover, the unlearned model at the intermediate step of our RNP can be directly used to improve other backdoor defense tasks including backdoor removal, trigger recovery, backdoor label detection, and backdoor sample detection. Code is available at \url{https://github.com/bboylyg/RNP}.
Anti-Backdoor Learning: Training Clean Models on Poisoned Data
Oct 25, 2021
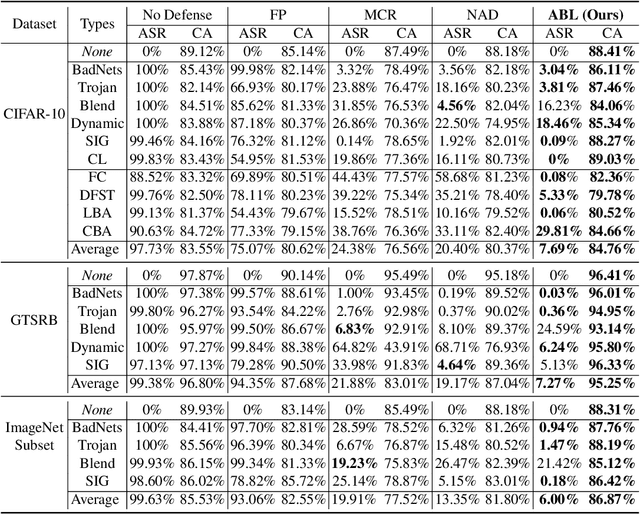
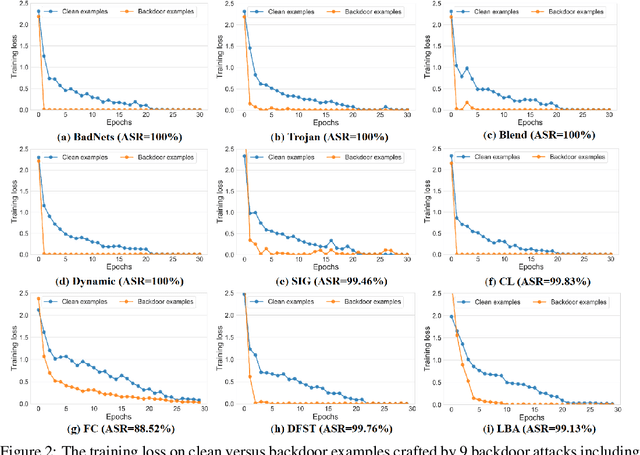

Backdoor attack has emerged as a major security threat to deep neural networks (DNNs). While existing defense methods have demonstrated promising results on detecting or erasing backdoors, it is still not clear whether robust training methods can be devised to prevent the backdoor triggers being injected into the trained model in the first place. In this paper, we introduce the concept of \emph{anti-backdoor learning}, aiming to train \emph{clean} models given backdoor-poisoned data. We frame the overall learning process as a dual-task of learning the \emph{clean} and the \emph{backdoor} portions of data. From this view, we identify two inherent characteristics of backdoor attacks as their weaknesses: 1) the models learn backdoored data much faster than learning with clean data, and the stronger the attack the faster the model converges on backdoored data; 2) the backdoor task is tied to a specific class (the backdoor target class). Based on these two weaknesses, we propose a general learning scheme, Anti-Backdoor Learning (ABL), to automatically prevent backdoor attacks during training. ABL introduces a two-stage \emph{gradient ascent} mechanism for standard training to 1) help isolate backdoor examples at an early training stage, and 2) break the correlation between backdoor examples and the target class at a later training stage. Through extensive experiments on multiple benchmark datasets against 10 state-of-the-art attacks, we empirically show that ABL-trained models on backdoor-poisoned data achieve the same performance as they were trained on purely clean data. Code is available at \url{https://github.com/bboylyg/ABL}.
Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks
Jan 27, 2021


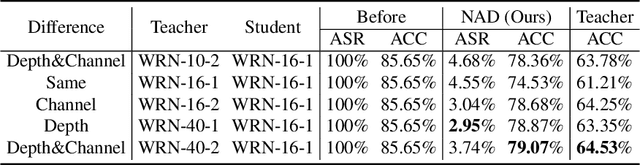
Deep neural networks (DNNs) are known vulnerable to backdoor attacks, a training time attack that injects a trigger pattern into a small proportion of training data so as to control the model's prediction at the test time. Backdoor attacks are notably dangerous since they do not affect the model's performance on clean examples, yet can fool the model to make incorrect prediction whenever the trigger pattern appears during testing. In this paper, we propose a novel defense framework Neural Attention Distillation (NAD) to erase backdoor triggers from backdoored DNNs. NAD utilizes a teacher network to guide the finetuning of the backdoored student network on a small clean subset of data such that the intermediate-layer attention of the student network aligns with that of the teacher network. The teacher network can be obtained by an independent finetuning process on the same clean subset. We empirically show, against 6 state-of-the-art backdoor attacks, NAD can effectively erase the backdoor triggers using only 5\% clean training data without causing obvious performance degradation on clean examples. Code is available in https://github.com/bboylyg/NAD.