 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Recipes for Efficient and Compact Vision-Language Models
Mar 17, 2026Deploying vision-language models (VLMs) in resource-constrained settings demands low latency and high throughput, yet existing compact VLMs often fall short of the inference speedups their smaller parameter counts suggest. To explain this discrepancy, we conduct an empirical end-to-end efficiency analysis and systematically profile inference to identify the dominant bottlenecks. Based on these findings, we develop optimization recipes tailored to compact VLMs that substantially reduce latency while preserving accuracy. These techniques cut time to first token (TTFT) by 53% on InternVL3-2B and by 93% on SmolVLM-256M. Our recipes are broadly applicable across both VLM architectures and common serving frameworks, providing practical guidance for building efficient VLM systems. Beyond efficiency, we study how to extend compact VLMs with structured perception outputs and introduce the resulting model family, ArgusVLM. Across diverse benchmarks, ArgusVLM achieves strong performance while maintaining a compact and efficient design.
UniCompress: Token Compression for Unified Vision-Language Understanding and Generation
Mar 11, 2026Unified models aim to support both understanding and generation by encoding images into discrete tokens and processing them alongside text within a single autoregressive framework. This unified design offers architectural simplicity and cross-modal synergy, which facilitates shared parameterization, consistent training objectives, and seamless transfer between modalities. However, the large number of visual tokens required by such models introduces substantial computation and memory overhead, and this inefficiency directly hinders deployment in resource constrained scenarios such as embodied AI systems. In this work, we propose a unified token compression algorithm UniCompress that significantly reduces visual token count while preserving performance on both image understanding and generation tasks. Our method introduces a plug-in compression and decompression mechanism guided with learnable global meta tokens. The framework is lightweight and modular, enabling efficient integration into existing models without full retraining. Experimental results show that our approach reduces image tokens by up to 4 times, achieves substantial gains in inference latency and training cost, and incurs only minimal performance degradation, which demonstrates the promise of token-efficient unified modeling for real world multimodal applications.
Diagnosing Knowledge Conflict in Multimodal Long-Chain Reasoning
Feb 16, 2026Multimodal large language models (MLLMs) in long chain-of-thought reasoning often fail when different knowledge sources provide conflicting signals. We formalize these failures under a unified notion of knowledge conflict, distinguishing input-level objective conflict from process-level effective conflict. Through probing internal representations, we reveal that: (I) Linear Separability: different conflict types are explicitly encoded as linearly separable features rather than entangled; (II) Depth Localization: conflict signals concentrate in mid-to-late layers, indicating a distinct processing stage for conflict encoding; (III) Hierarchical Consistency: aggregating noisy token-level signals along trajectories robustly recovers input-level conflict types; and (IV) Directional Asymmetry: reinforcing the model's implicit source preference under conflict is far easier than enforcing the opposite source. Our findings provide a mechanism-level view of multimodal reasoning under knowledge conflict and enable principled diagnosis and control of long-CoT failures.
OutSafe-Bench: A Benchmark for Multimodal Offensive Content Detection in Large Language Models
Nov 13, 2025



Since Multimodal Large Language Models (MLLMs) are increasingly being integrated into everyday tools and intelligent agents, growing concerns have arisen regarding their possible output of unsafe contents, ranging from toxic language and biased imagery to privacy violations and harmful misinformation. Current safety benchmarks remain highly limited in both modality coverage and performance evaluations, often neglecting the extensive landscape of content safety. In this work, we introduce OutSafe-Bench, the first most comprehensive content safety evaluation test suite designed for the multimodal era. OutSafe-Bench includes a large-scale dataset that spans four modalities, featuring over 18,000 bilingual (Chinese and English) text prompts, 4,500 images, 450 audio clips and 450 videos, all systematically annotated across nine critical content risk categories. In addition to the dataset, we introduce a Multidimensional Cross Risk Score (MCRS), a novel metric designed to model and assess overlapping and correlated content risks across different categories. To ensure fair and robust evaluation, we propose FairScore, an explainable automated multi-reviewer weighted aggregation framework. FairScore selects top-performing models as adaptive juries, thereby mitigating biases from single-model judgments and enhancing overall evaluation reliability. Our evaluation of nine state-of-the-art MLLMs reveals persistent and substantial safety vulnerabilities, underscoring the pressing need for robust safeguards in MLLMs.
StelLA: Subspace Learning in Low-rank Adaptation using Stiefel Manifold
Oct 02, 2025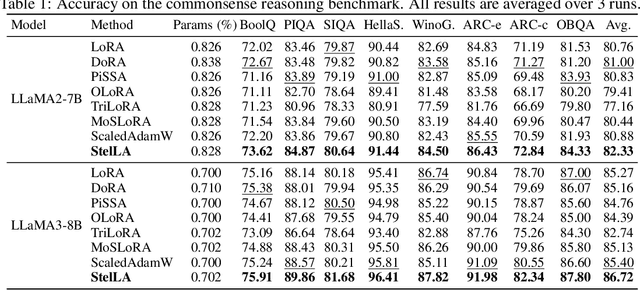
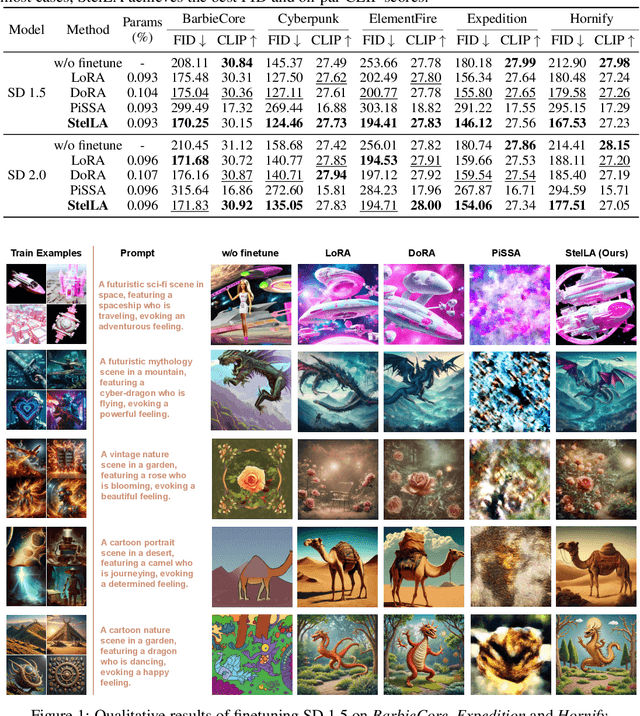
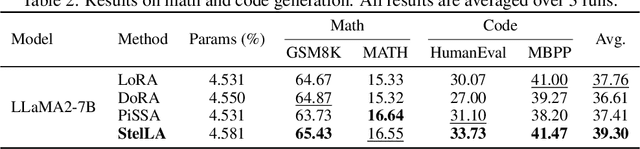
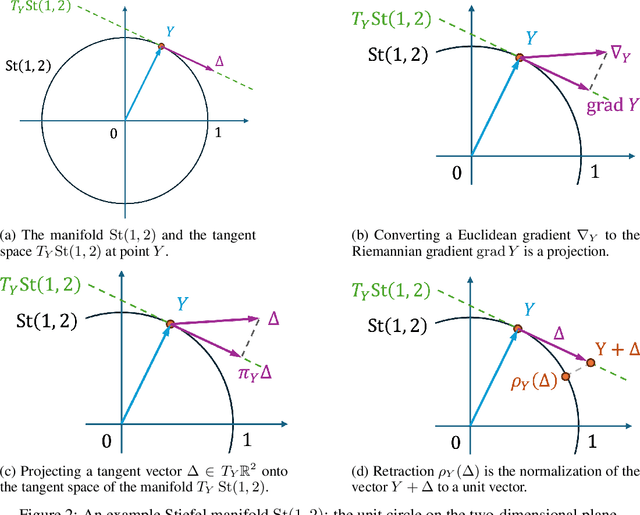
Low-rank adaptation (LoRA) has been widely adopted as a parameter-efficient technique for fine-tuning large-scale pre-trained models. However, it still lags behind full fine-tuning in performance, partly due to its insufficient exploitation of the geometric structure underlying low-rank manifolds. In this paper, we propose a geometry-aware extension of LoRA that uses a three-factor decomposition $U\!SV^\top$. Analogous to the structure of singular value decomposition (SVD), it separates the adapter's input and output subspaces, $V$ and $U$, from the scaling factor $S$. Our method constrains $U$ and $V$ to lie on the Stiefel manifold, ensuring their orthonormality throughout the training. To optimize on the Stiefel manifold, we employ a flexible and modular geometric optimization design that converts any Euclidean optimizer to a Riemannian one. It enables efficient subspace learning while remaining compatible with existing fine-tuning pipelines. Empirical results across a wide range of downstream tasks, including commonsense reasoning, math and code generation, image classification, and image generation, demonstrate the superior performance of our approach against the recent state-of-the-art variants of LoRA. Code is available at https://github.com/SonyResearch/stella.
UNIFORM: Unifying Knowledge from Large-scale and Diverse Pre-trained Models
Aug 27, 2025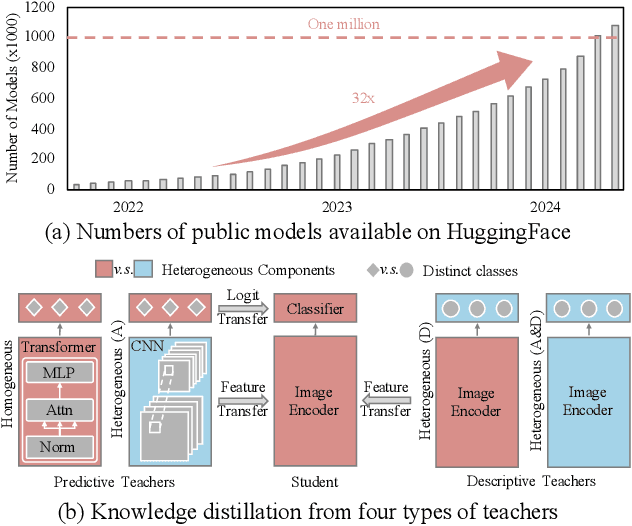
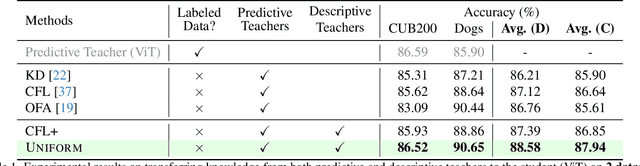
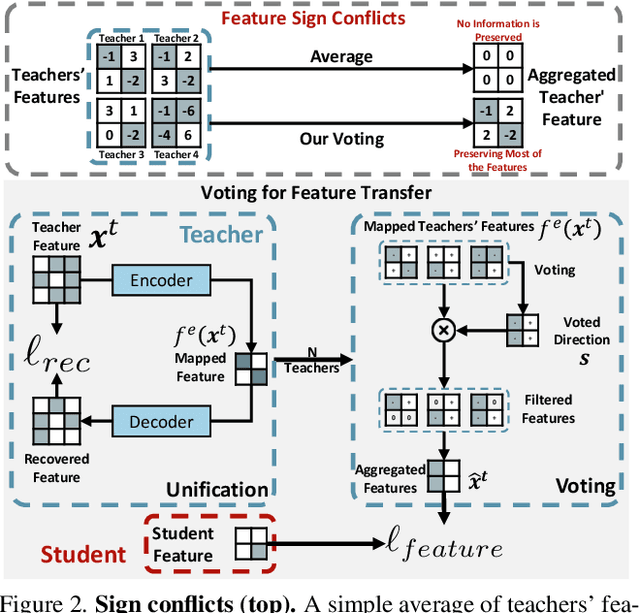
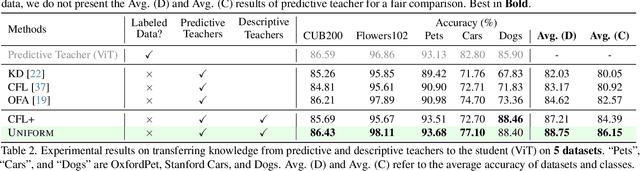
In the era of deep learning, the increasing number of pre-trained models available online presents a wealth of knowledge. These models, developed with diverse architectures and trained on varied datasets for different tasks, provide unique interpretations of the real world. Their collective consensus is likely universal and generalizable to unseen data. However, effectively harnessing this collective knowledge poses a fundamental challenge due to the heterogeneity of pre-trained models. Existing knowledge integration solutions typically rely on strong assumptions about training data distributions and network architectures, limiting them to learning only from specific types of models and resulting in data and/or inductive biases. In this work, we introduce a novel framework, namely UNIFORM, for knowledge transfer from a diverse set of off-the-shelf models into one student model without such constraints. Specifically, we propose a dedicated voting mechanism to capture the consensus of knowledge both at the logit level -- incorporating teacher models that are capable of predicting target classes of interest -- and at the feature level, utilizing visual representations learned on arbitrary label spaces. Extensive experiments demonstrate that UNIFORM effectively enhances unsupervised object recognition performance compared to strong knowledge transfer baselines. Notably, it exhibits remarkable scalability by benefiting from over one hundred teachers, while existing methods saturate at a much smaller scale.
Seeing Further on the Shoulders of Giants: Knowledge Inheritance for Vision Foundation Models
Aug 20, 2025Vision foundation models (VFMs) are predominantly developed using data-centric methods. These methods require training on vast amounts of data usually with high-quality labels, which poses a bottleneck for most institutions that lack both large-scale data and high-end GPUs. On the other hand, many open-source vision models have been pretrained on domain-specific data, enabling them to distill and represent core knowledge in a form that is transferable across diverse applications. Even though these models are highly valuable assets, they remain largely under-explored in empowering the development of a general-purpose VFM. In this paper, we presents a new model-driven approach for training VFMs through joint knowledge transfer and preservation. Our method unifies multiple pre-trained teacher models in a shared latent space to mitigate the ``imbalanced transfer'' issue caused by their distributional gaps. Besides, we introduce a knowledge preservation strategy to take a general-purpose teacher as a knowledge base for integrating knowledge from the remaining purpose-specific teachers using an adapter module. By unifying and aggregating existing models, we build a powerful VFM to inherit teachers' expertise without needing to train on a large amount of labeled data. Our model not only provides generalizable visual features, but also inherently supports multiple downstream tasks. Extensive experiments demonstrate that our VFM outperforms existing data-centric models across four fundamental vision tasks, including image classification, object detection, semantic and instance segmentation.
Investigating the Design Space of Visual Grounding in Multimodal Large Language Model
Aug 11, 2025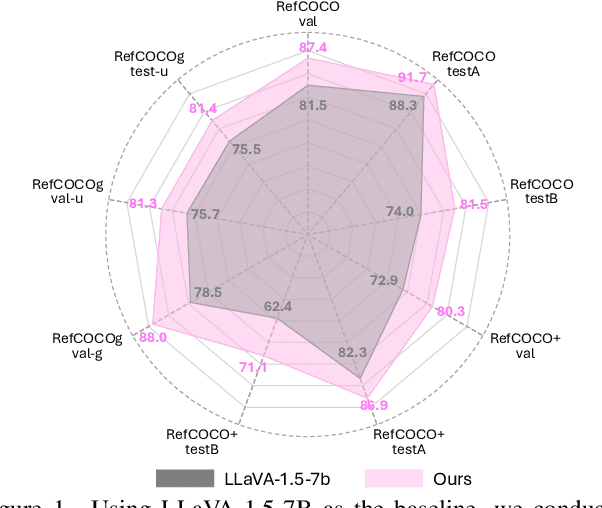
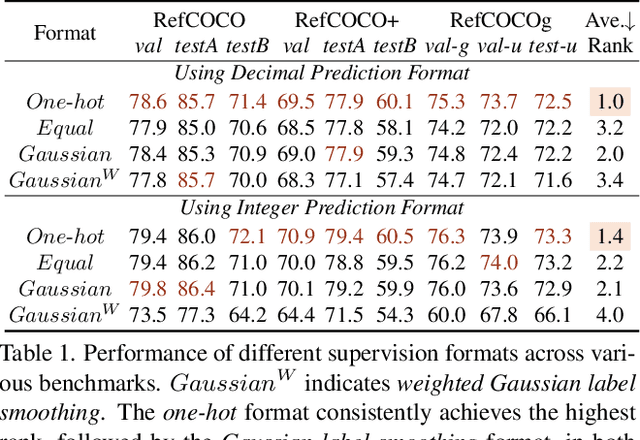
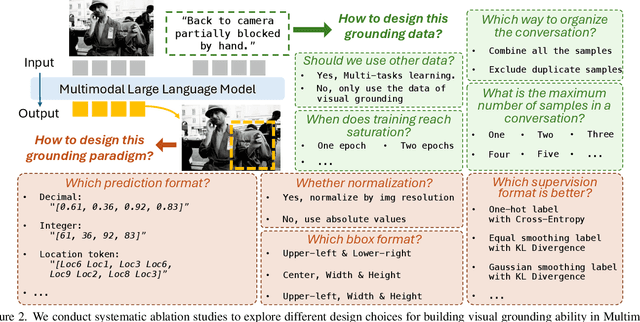
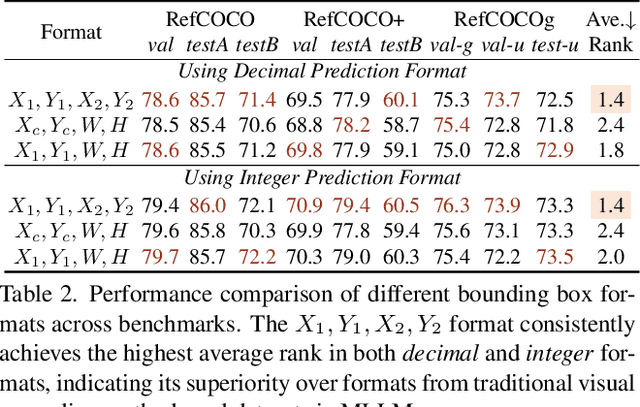
Fine-grained multimodal capability in Multimodal Large Language Models (MLLMs) has emerged as a critical research direction, particularly for tackling the visual grounding (VG) problem. Despite the strong performance achieved by existing approaches, they often employ disparate design choices when fine-tuning MLLMs for VG, lacking systematic verification to support these designs. To bridge this gap, this paper presents a comprehensive study of various design choices that impact the VG performance of MLLMs. We conduct our analysis using LLaVA-1.5, which has been widely adopted in prior empirical studies of MLLMs. While more recent models exist, we follow this convention to ensure our findings remain broadly applicable and extendable to other architectures. We cover two key aspects: (1) exploring different visual grounding paradigms in MLLMs, identifying the most effective design, and providing our insights; and (2) conducting ablation studies on the design of grounding data to optimize MLLMs' fine-tuning for the VG task. Finally, our findings contribute to a stronger MLLM for VG, achieving improvements of +5.6% / +6.9% / +7.0% on RefCOCO/+/g over the LLaVA-1.5.
LIFEBench: Evaluating Length Instruction Following in Large Language Models
May 22, 2025While large language models (LLMs) can solve PhD-level reasoning problems over long context inputs, they still struggle with a seemingly simpler task: following explicit length instructions-e.g., write a 10,000-word novel. Additionally, models often generate far too short outputs, terminate prematurely, or even refuse the request. Existing benchmarks focus primarily on evaluating generations quality, but often overlook whether the generations meet length constraints. To this end, we introduce Length Instruction Following Evaluation Benchmark (LIFEBench) to comprehensively evaluate LLMs' ability to follow length instructions across diverse tasks and a wide range of specified lengths. LIFEBench consists of 10,800 instances across 4 task categories in both English and Chinese, covering length constraints ranging from 16 to 8192 words. We evaluate 26 widely-used LLMs and find that most models reasonably follow short-length instructions but deteriorate sharply beyond a certain threshold. Surprisingly, almost all models fail to reach the vendor-claimed maximum output lengths in practice, as further confirmed by our evaluations extending up to 32K words. Even long-context LLMs, despite their extended input-output windows, counterintuitively fail to improve length-instructions following. Notably, Reasoning LLMs outperform even specialized long-text generation models, achieving state-of-the-art length following. Overall, LIFEBench uncovers fundamental limitations in current LLMs' length instructions following ability, offering critical insights for future progress.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.