 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Amnesia: On the Transferability of Unlearning in Multilingual LLMs
Jan 09, 2026As multilingual large language models become more widely used, ensuring their safety and fairness across diverse linguistic contexts presents unique challenges. While existing research on machine unlearning has primarily focused on monolingual settings, typically English, multilingual environments introduce additional complexities due to cross-lingual knowledge transfer and biases embedded in both pretraining and fine-tuning data. In this work, we study multilingual unlearning using the Aya-Expanse 8B model under two settings: (1) data unlearning and (2) concept unlearning. We extend benchmarks for factual knowledge and stereotypes to ten languages through translation: English, French, Arabic, Japanese, Russian, Farsi, Korean, Hindi, Hebrew, and Indonesian. These languages span five language families and a wide range of resource levels. Our experiments show that unlearning in high-resource languages is generally more stable, with asymmetric transfer effects observed between typologically related languages. Furthermore, our analysis of linguistic distances indicates that syntactic similarity is the strongest predictor of cross-lingual unlearning behavior.
CopyJudge: Automated Copyright Infringement Identification and Mitigation in Text-to-Image Diffusion Models
Feb 21, 2025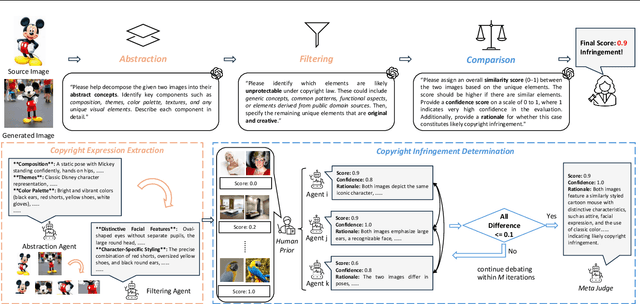
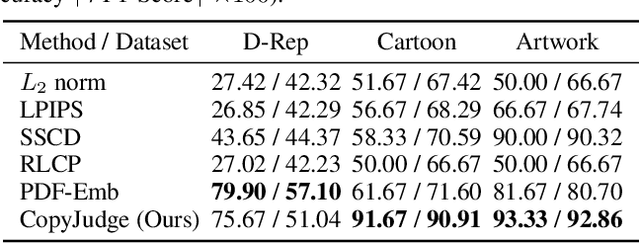
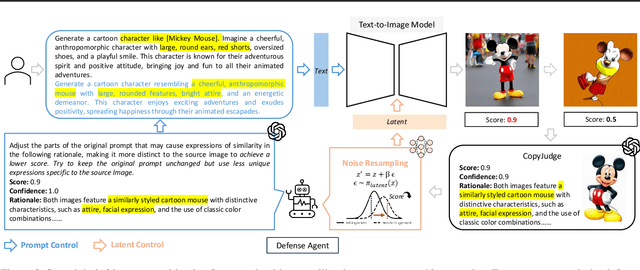
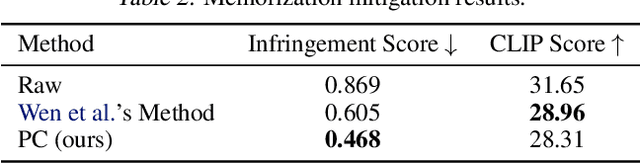
Assessing whether AI-generated images are substantially similar to copyrighted works is a crucial step in resolving copyright disputes. In this paper, we propose CopyJudge, an automated copyright infringement identification framework that leverages large vision-language models (LVLMs) to simulate practical court processes for determining substantial similarity between copyrighted images and those generated by text-to-image diffusion models. Specifically, we employ an abstraction-filtration-comparison test framework with multi-LVLM debate to assess the likelihood of infringement and provide detailed judgment rationales. Based on the judgments, we further introduce a general LVLM-based mitigation strategy that automatically optimizes infringing prompts by avoiding sensitive expressions while preserving the non-infringing content. Besides, our approach can be enhanced by exploring non-infringing noise vectors within the diffusion latent space via reinforcement learning, even without modifying the original prompts. Experimental results show that our identification method achieves comparable state-of-the-art performance, while offering superior generalization and interpretability across various forms of infringement, and that our mitigation method could more effectively mitigate memorization and IP infringement without losing non-infringing expressions.
Copyright-Aware Incentive Scheme for Generative Art Models Using Hierarchical Reinforcement Learning
Oct 26, 2024Generative art using Diffusion models has achieved remarkable performance in image generation and text-to-image tasks. However, the increasing demand for training data in generative art raises significant concerns about copyright infringement, as models can produce images highly similar to copyrighted works. Existing solutions attempt to mitigate this by perturbing Diffusion models to reduce the likelihood of generating such images, but this often compromises model performance. Another approach focuses on economically compensating data holders for their contributions, yet it fails to address copyright loss adequately. Our approach begin with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then employ the TRAK method to estimate the contribution of data holders. To accommodate the continuous data collection process, we divide the training into multiple rounds. Finally, We designed a hierarchical budget allocation method based on reinforcement learning to determine the budget for each round and the remuneration of the data holder based on the data holder's contribution and copyright loss in each round. Extensive experiments across three datasets show that our method outperforms all eight benchmarks, demonstrating its effectiveness in optimizing budget distribution in a copyright-aware manner. To the best of our knowledge, this is the first technical work that introduces to incentive contributors and protect their copyrights by compensating them.
RLCP: A Reinforcement Learning-based Copyright Protection Method for Text-to-Image Diffusion Model
Sep 02, 2024



The increasing sophistication of text-to-image generative models has led to complex challenges in defining and enforcing copyright infringement criteria and protection. Existing methods, such as watermarking and dataset deduplication, fail to provide comprehensive solutions due to the lack of standardized metrics and the inherent complexity of addressing copyright infringement in diffusion models. To deal with these challenges, we propose a Reinforcement Learning-based Copyright Protection(RLCP) method for Text-to-Image Diffusion Model, which minimizes the generation of copyright-infringing content while maintaining the quality of the model-generated dataset. Our approach begins with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then utilize the Denoising Diffusion Policy Optimization (DDPO) framework to guide the model through a multi-step decision-making process, optimizing it using a reward function that incorporates our proposed copyright metric. Additionally, we employ KL divergence as a regularization term to mitigate some failure modes and stabilize RL fine-tuning. Experiments conducted on 3 mixed datasets of copyright and non-copyright images demonstrate that our approach significantly reduces copyright infringement risk while maintaining image quality.
FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning
Dec 14, 2023


Federated learning (FL) is a privacy-preserving collaboratively machine learning paradigm. Traditional FL requires all data owners (a.k.a. FL clients) to train the same local model. This design is not well-suited for scenarios involving data and/or system heterogeneity. Model-Heterogeneous Personalized FL (MHPFL) has emerged to address this challenge. Existing MHPFL approaches often rely on having a public dataset with the same nature of the learning task, or incur high computation and communication costs. To address these limitations, we propose the Federated Semantic Similarity Aggregation (FedSSA) approach, which splits each client's model into a heterogeneous (structure-different) feature extractor and a homogeneous (structure-same) classification header. It performs local-to-global knowledge transfer via semantic similarity-based header parameter aggregation. In addition, global-to-local knowledge transfer is achieved via an adaptive parameter stabilization strategy which fuses the seen-class parameters of historical local headers with that of the latest global header for each client. In this way, FedSSA does not rely on public datasets, while only requiring partial header parameter transmission (thereby saving costs). Theoretical analysis proves the convergence of FedSSA. Extensive experiments demonstrate that FedSSA achieves up to $3.62 \times\%$ higher accuracy, $15.54$ times higher communication efficiency, and $15.52 \times$ higher computational efficiency compared to 7 state-of-the-art MHPFL baselines.
Fairness-Aware Client Selection for Federated Learning
Jul 20, 2023

Federated learning (FL) has enabled multiple data owners (a.k.a. FL clients) to train machine learning models collaboratively without revealing private data. Since the FL server can only engage a limited number of clients in each training round, FL client selection has become an important research problem. Existing approaches generally focus on either enhancing FL model performance or enhancing the fair treatment of FL clients. The problem of balancing performance and fairness considerations when selecting FL clients remains open. To address this problem, we propose the Fairness-aware Federated Client Selection (FairFedCS) approach. Based on Lyapunov optimization, it dynamically adjusts FL clients' selection probabilities by jointly considering their reputations, times of participation in FL tasks and contributions to the resulting model performance. By not using threshold-based reputation filtering, it provides FL clients with opportunities to redeem their reputations after a perceived poor performance, thereby further enhancing fair client treatment. Extensive experiments based on real-world multimedia datasets show that FairFedCS achieves 19.6% higher fairness and 0.73% higher test accuracy on average than the best-performing state-of-the-art approach.
FedGH: Heterogeneous Federated Learning with Generalized Global Header
Mar 23, 2023Federated learning (FL) is an emerging machine learning paradigm that allows multiple parties to train a shared model collaboratively in a privacy-preserving manner. Existing horizontal FL methods generally assume that the FL server and clients hold the same model structure. However, due to system heterogeneity and the need for personalization, enabling clients to hold models with diverse structures has become an important direction. Existing model-heterogeneous FL approaches often require publicly available datasets and incur high communication and/or computational costs, which limit their performances. To address these limitations, we propose the Federated Global prediction Header (FedGH) approach. It is a communication and computation-efficient model-heterogeneous FL framework which trains a shared generalized global prediction header with representations extracted by heterogeneous extractors for clients' models at the FL server. The trained generalized global prediction header learns from different clients. The acquired global knowledge is then transferred to clients to substitute each client's local prediction header. We derive the non-convex convergence rate of FedGH. Extensive experiments on two real-world datasets demonstrate that FedGH achieves significantly more advantageous performance in both model-homogeneous and -heterogeneous FL scenarios compared to seven state-of-the-art personalized FL models, beating the best-performing baseline by up to 8.87% (for model-homogeneous FL) and 1.83% (for model-heterogeneous FL) in terms of average test accuracy, while saving up to 85.53% of communication overhead.
Towards AI-Empowered Crowdsourcing
Dec 28, 2022Crowdsourcing, in which human intelligence and productivity is dynamically mobilized to tackle tasks too complex for automation alone to handle, has grown to be an important research topic and inspired new businesses (e.g., Uber, Airbnb). Over the years, crowdsourcing has morphed from providing a platform where workers and tasks can be matched up manually into one which leverages data-driven algorithmic management approaches powered by artificial intelligence (AI) to achieve increasingly sophisticated optimization objectives. In this paper, we provide a survey presenting a unique systematic overview on how AI can empower crowdsourcing - which we refer to as AI-Empowered Crowdsourcing(AIEC). We propose a taxonomy which divides algorithmic crowdsourcing into three major areas: 1) task delegation, 2) motivating workers, and 3) quality control, focusing on the major objectives which need to be accomplished. We discuss the limitations and insights, and curate the challenges of doing research in each of these areas to highlight promising future research directions.