 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Miniature UAV Empowered Reconfigurable Energy Harvesting Holographic Surfaces in THz Cooperative Networks
Nov 27, 2024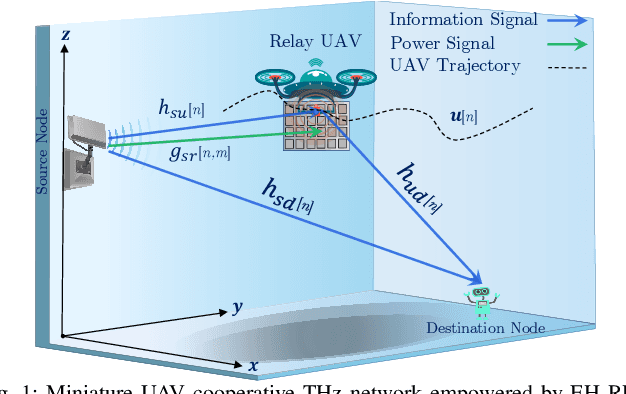
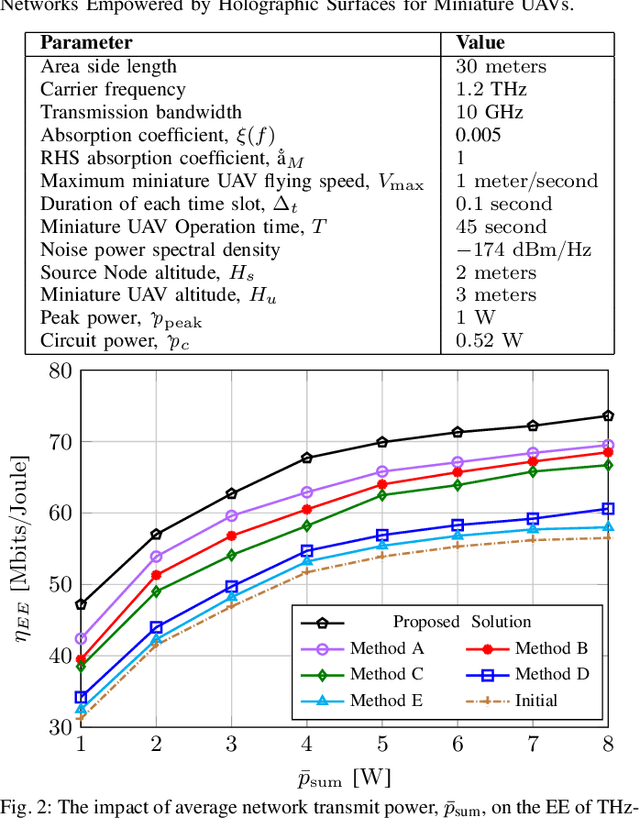
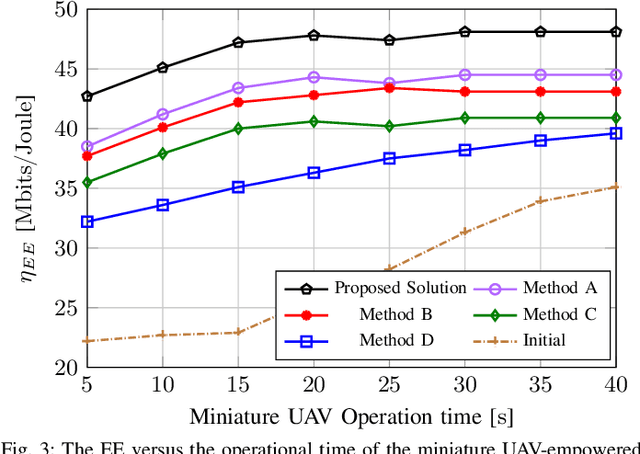
This paper focuses on enhancing the energy efficiency (EE) of a cooperative network featuring a `miniature' unmanned aerial vehicle (UAV) that operates at terahertz (THz) frequencies, utilizing holographic surfaces to improve the network's performance. Unlike traditional reconfigurable intelligent surfaces (RIS) that are typically used as passive relays to adjust signal reflections, this work introduces a novel concept: Energy harvesting (EH) using reconfigurable holographic surfaces (RHS) mounted on the miniature UAV. In this system, a source node facilitates the simultaneous reception of information and energy signals by the UAV, with the harvested energy from the RHS being used by the UAV to transmit data to a specific destination. The EE optimization involves adjusting non-orthogonal multiple access (NOMA) power coefficients and the UAV's flight path, considering the peculiarities of the THz channel. The optimization problem is solved in two steps. Initially, the trajectory is refined using a successive convex approximation (SCA) method, followed by the adjustment of NOMA power coefficients through a quadratic transform technique. The effectiveness of the proposed algorithm is demonstrated through simulations, showing superior results when compared to baseline methods.
Copyright-Aware Incentive Scheme for Generative Art Models Using Hierarchical Reinforcement Learning
Oct 26, 2024Generative art using Diffusion models has achieved remarkable performance in image generation and text-to-image tasks. However, the increasing demand for training data in generative art raises significant concerns about copyright infringement, as models can produce images highly similar to copyrighted works. Existing solutions attempt to mitigate this by perturbing Diffusion models to reduce the likelihood of generating such images, but this often compromises model performance. Another approach focuses on economically compensating data holders for their contributions, yet it fails to address copyright loss adequately. Our approach begin with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then employ the TRAK method to estimate the contribution of data holders. To accommodate the continuous data collection process, we divide the training into multiple rounds. Finally, We designed a hierarchical budget allocation method based on reinforcement learning to determine the budget for each round and the remuneration of the data holder based on the data holder's contribution and copyright loss in each round. Extensive experiments across three datasets show that our method outperforms all eight benchmarks, demonstrating its effectiveness in optimizing budget distribution in a copyright-aware manner. To the best of our knowledge, this is the first technical work that introduces to incentive contributors and protect their copyrights by compensating them.
ScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours
Apr 17, 2024



AlphaFold2 has been hailed as a breakthrough in protein folding. It can rapidly predict protein structures with lab-grade accuracy. However, its implementation does not include the necessary training code. OpenFold is the first trainable public reimplementation of AlphaFold. AlphaFold training procedure is prohibitively time-consuming, and gets diminishing benefits from scaling to more compute resources. In this work, we conducted a comprehensive analysis on the AlphaFold training procedure based on Openfold, identified that inefficient communications and overhead-dominated computations were the key factors that prevented the AlphaFold training from effective scaling. We introduced ScaleFold, a systematic training method that incorporated optimizations specifically for these factors. ScaleFold successfully scaled the AlphaFold training to 2080 NVIDIA H100 GPUs with high resource utilization. In the MLPerf HPC v3.0 benchmark, ScaleFold finished the OpenFold benchmark in 7.51 minutes, shown over $6\times$ speedup than the baseline. For training the AlphaFold model from scratch, ScaleFold completed the pretraining in 10 hours, a significant improvement over the seven days required by the original AlphaFold pretraining baseline.
Learning at the Speed of Wireless: Online Real-Time Learning for AI-Enabled MIMO in NextG
Mar 05, 2024



Integration of artificial intelligence (AI) and machine learning (ML) into the air interface has been envisioned as a key technology for next-generation (NextG) cellular networks. At the air interface, multiple-input multiple-output (MIMO) and its variants such as multi-user MIMO (MU-MIMO) and massive/full-dimension MIMO have been key enablers across successive generations of cellular networks with evolving complexity and design challenges. Initiating active investigation into leveraging AI/ML tools to address these challenges for MIMO becomes a critical step towards an AI-enabled NextG air interface. At the NextG air interface, the underlying wireless environment will be extremely dynamic with operation adaptations performed on a sub-millisecond basis by MIMO operations such as MU-MIMO scheduling and rank/link adaptation. Given the enormously large number of operation adaptation possibilities, we contend that online real-time AI/ML-based approaches constitute a promising paradigm. To this end, we outline the inherent challenges and offer insights into the design of such online real-time AI/ML-based solutions for MIMO operations. An online real-time AI/ML-based method for MIMO-OFDM channel estimation is then presented, serving as a potential roadmap for developing similar techniques across various MIMO operations in NextG.
Federated Dynamic Spectrum Access
Jun 28, 2021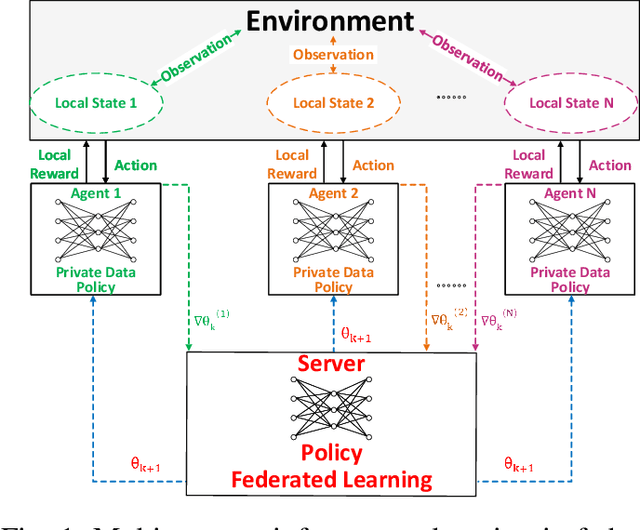
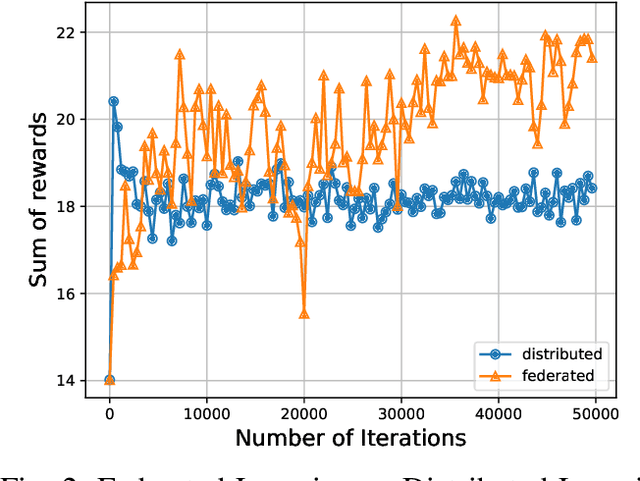
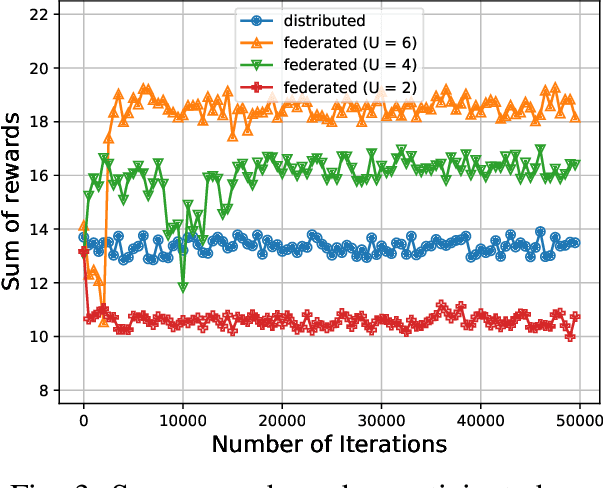
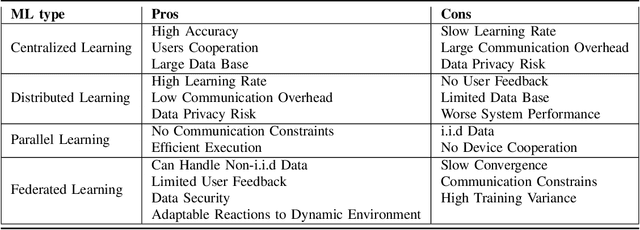
Due to the growing volume of data traffic produced by the surge of Internet of Things (IoT) devices, the demand for radio spectrum resources is approaching their limitation defined by Federal Communications Commission (FCC). To this end, Dynamic Spectrum Access (DSA) is considered as a promising technology to handle this spectrum scarcity. However, standard DSA techniques often rely on analytical modeling wireless networks, making its application intractable in under-measured network environments. Therefore, utilizing neural networks to approximate the network dynamics is an alternative approach. In this article, we introduce a Federated Learning (FL) based framework for the task of DSA, where FL is a distributive machine learning framework that can reserve the privacy of network terminals under heterogeneous data distributions. We discuss the opportunities, challenges, and opening problems of this framework. To evaluate its feasibility, we implement a Multi-Agent Reinforcement Learning (MARL)-based FL as a realization associated with its initial evaluation results.
Differential Privacy Meets Federated Learning under Communication Constraints
Jan 28, 2021
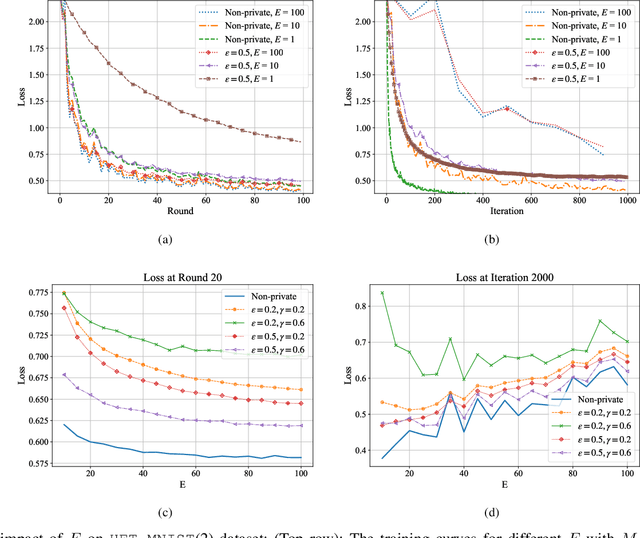

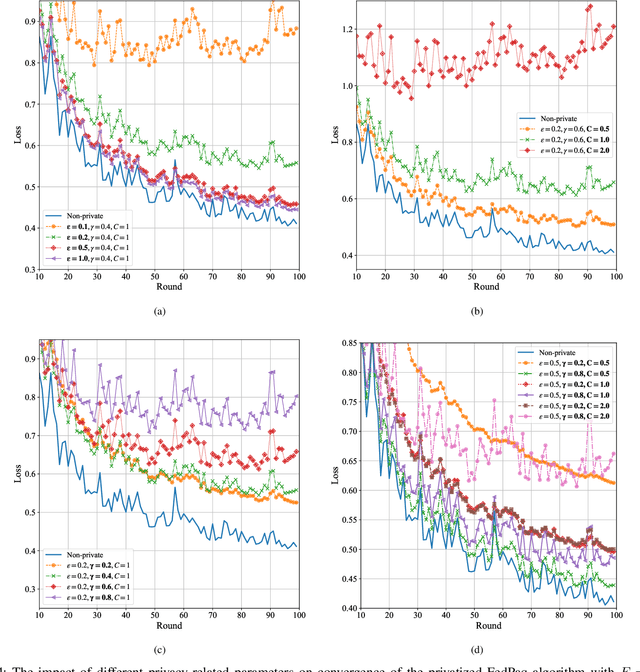
The performance of federated learning systems is bottlenecked by communication costs and training variance. The communication overhead problem is usually addressed by three communication-reduction techniques, namely, model compression, partial device participation, and periodic aggregation, at the cost of increased training variance. Different from traditional distributed learning systems, federated learning suffers from data heterogeneity (since the devices sample their data from possibly different distributions), which induces additional variance among devices during training. Various variance-reduced training algorithms have been introduced to combat the effects of data heterogeneity, while they usually cost additional communication resources to deliver necessary control information. Additionally, data privacy remains a critical issue in FL, and thus there have been attempts at bringing Differential Privacy to this framework as a mediator between utility and privacy requirements. This paper investigates the trade-offs between communication costs and training variance under a resource-constrained federated system theoretically and experimentally, and how communication reduction techniques interplay in a differentially private setting. The results provide important insights into designing practical privacy-aware federated learning systems.