 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleFold: Reducing AlphaFold Initial Training Time to 10 Hours
Apr 17, 2024



AlphaFold2 has been hailed as a breakthrough in protein folding. It can rapidly predict protein structures with lab-grade accuracy. However, its implementation does not include the necessary training code. OpenFold is the first trainable public reimplementation of AlphaFold. AlphaFold training procedure is prohibitively time-consuming, and gets diminishing benefits from scaling to more compute resources. In this work, we conducted a comprehensive analysis on the AlphaFold training procedure based on Openfold, identified that inefficient communications and overhead-dominated computations were the key factors that prevented the AlphaFold training from effective scaling. We introduced ScaleFold, a systematic training method that incorporated optimizations specifically for these factors. ScaleFold successfully scaled the AlphaFold training to 2080 NVIDIA H100 GPUs with high resource utilization. In the MLPerf HPC v3.0 benchmark, ScaleFold finished the OpenFold benchmark in 7.51 minutes, shown over $6\times$ speedup than the baseline. For training the AlphaFold model from scratch, ScaleFold completed the pretraining in 10 hours, a significant improvement over the seven days required by the original AlphaFold pretraining baseline.
Boosting the Convergence of Reinforcement Learning-based Auto-pruning Using Historical Data
Jul 16, 2021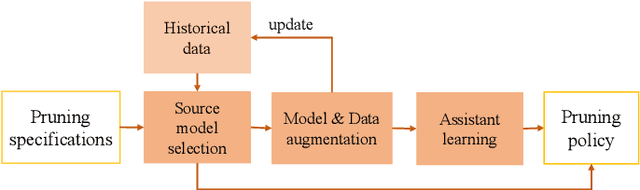
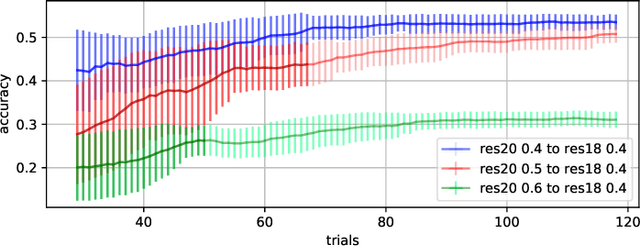
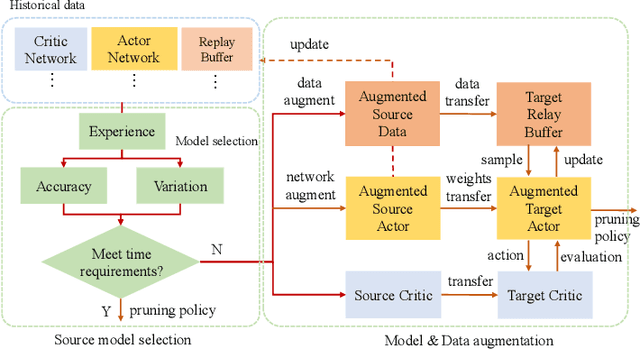
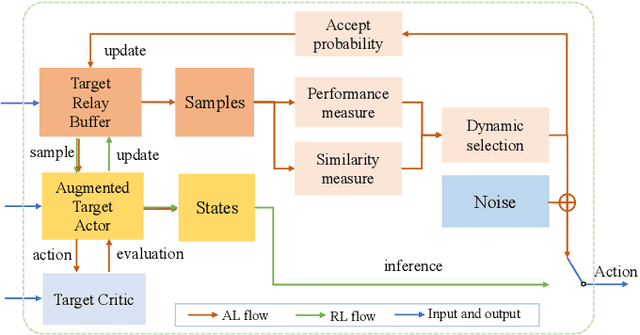
Recently, neural network compression schemes like channel pruning have been widely used to reduce the model size and computational complexity of deep neural network (DNN) for applications in power-constrained scenarios such as embedded systems. Reinforcement learning (RL)-based auto-pruning has been further proposed to automate the DNN pruning process to avoid expensive hand-crafted work. However, the RL-based pruner involves a time-consuming training process and the high expense of each sample further exacerbates this problem. These impediments have greatly restricted the real-world application of RL-based auto-pruning. Thus, in this paper, we propose an efficient auto-pruning framework which solves this problem by taking advantage of the historical data from the previous auto-pruning process. In our framework, we first boost the convergence of the RL-pruner by transfer learning. Then, an augmented transfer learning scheme is proposed to further speed up the training process by improving the transferability. Finally, an assistant learning process is proposed to improve the sample efficiency of the RL agent. The experiments have shown that our framework can accelerate the auto-pruning process by 1.5-2.5 times for ResNet20, and 1.81-2.375 times for other neural networks like ResNet56, ResNet18, and MobileNet v1.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020

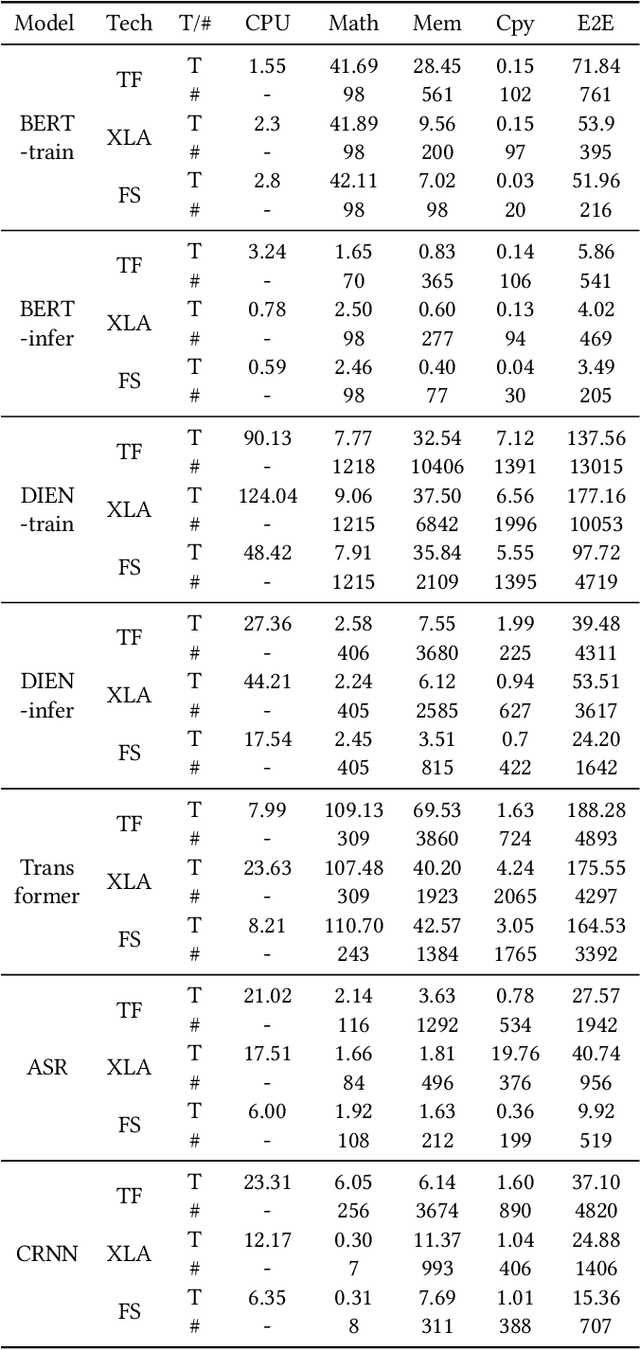

We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.
Sparse Persistent RNNs: Squeezing Large Recurrent Networks On-Chip
Apr 26, 2018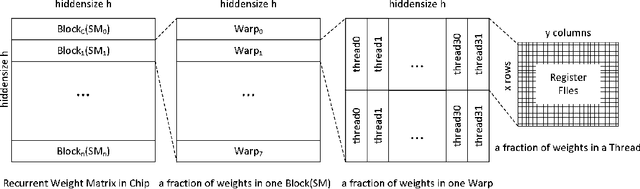
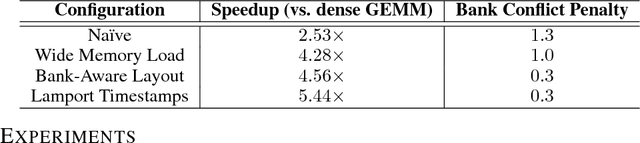
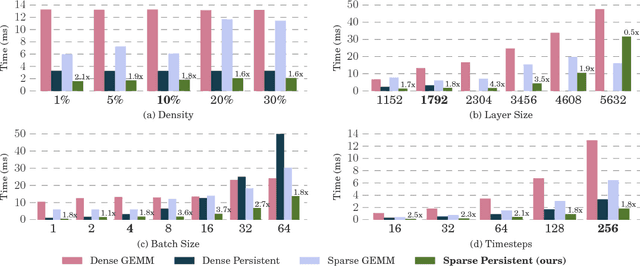
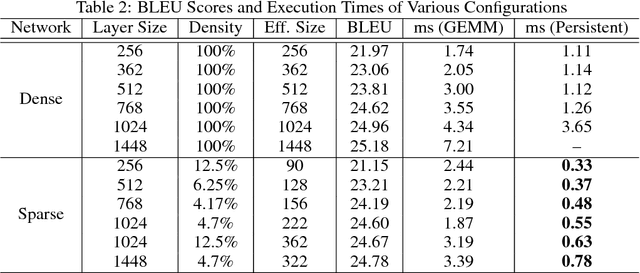
Recurrent Neural Networks (RNNs) are powerful tools for solving sequence-based problems, but their efficacy and execution time are dependent on the size of the network. Following recent work in simplifying these networks with model pruning and a novel mapping of work onto GPUs, we design an efficient implementation for sparse RNNs. We investigate several optimizations and tradeoffs: Lamport timestamps, wide memory loads, and a bank-aware weight layout. With these optimizations, we achieve speedups of over 6x over the next best algorithm for a hidden layer of size 2304, batch size of 4, and a density of 30%. Further, our technique allows for models of over 5x the size to fit on a GPU for a speedup of 2x, enabling larger networks to help advance the state-of-the-art. We perform case studies on NMT and speech recognition tasks in the appendix, accelerating their recurrent layers by up to 3x.