 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQPy: An Object-Oriented Approach to Modern Video Analytics
Nov 03, 2023Video analytics is widely used in contemporary systems and services. At the forefront of video analytics are video queries that users develop to find objects of particular interest. Building upon the insight that video objects (e.g., human, animals, cars, etc.), the center of video analytics, are similar in spirit to objects modeled by traditional object-oriented languages, we propose to develop an object-oriented approach to video analytics. This approach, named VQPy, consists of a frontend$\unicode{x2015}$a Python variant with constructs that make it easy for users to express video objects and their interactions$\unicode{x2015}$as well as an extensible backend that can automatically construct and optimize pipelines based on video objects. We have implemented and open-sourced VQPy, which has been productized in Cisco as part of its DeepVision framework.
Bamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
Apr 26, 2022
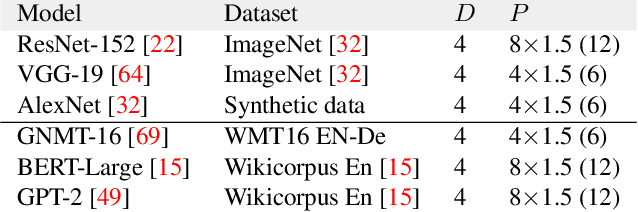


DNN models across many domains continue to grow in size, resulting in high resource requirements for effective training, and unpalatable (and often unaffordable) costs for organizations and research labs across scales. This paper aims to significantly reduce training costs with effective use of preemptible instances, i.e., those that can be obtained at a much cheaper price while idle, but may be preempted whenever requested by priority users. Doing so, however, requires new forms of resiliency and efficiency to cope with the possibility of frequent preemptions - a failure model that is drastically different from the occasional failures in normal cluster settings that existing checkpointing techniques target. We present Bamboo, a distributed system that tackles these challenges by introducing redundant computations into the training pipeline, i.e., whereby one node performs computations over not only its own layers but also over some layers in its neighbor. Our key insight is that training large models often requires pipeline parallelism where "pipeline bubbles" naturally exist. Bamboo carefully fills redundant computations into these bubbles, providing resilience at a low cost. Across a variety of widely used DNN models, Bamboo outperforms traditional checkpointing by 3.7x in training throughput, and reduces costs by 2.4x compared to a setting where on-demand instances are used.
FusionStitching: Boosting Memory Intensive Computations for Deep Learning Workloads
Sep 23, 2020

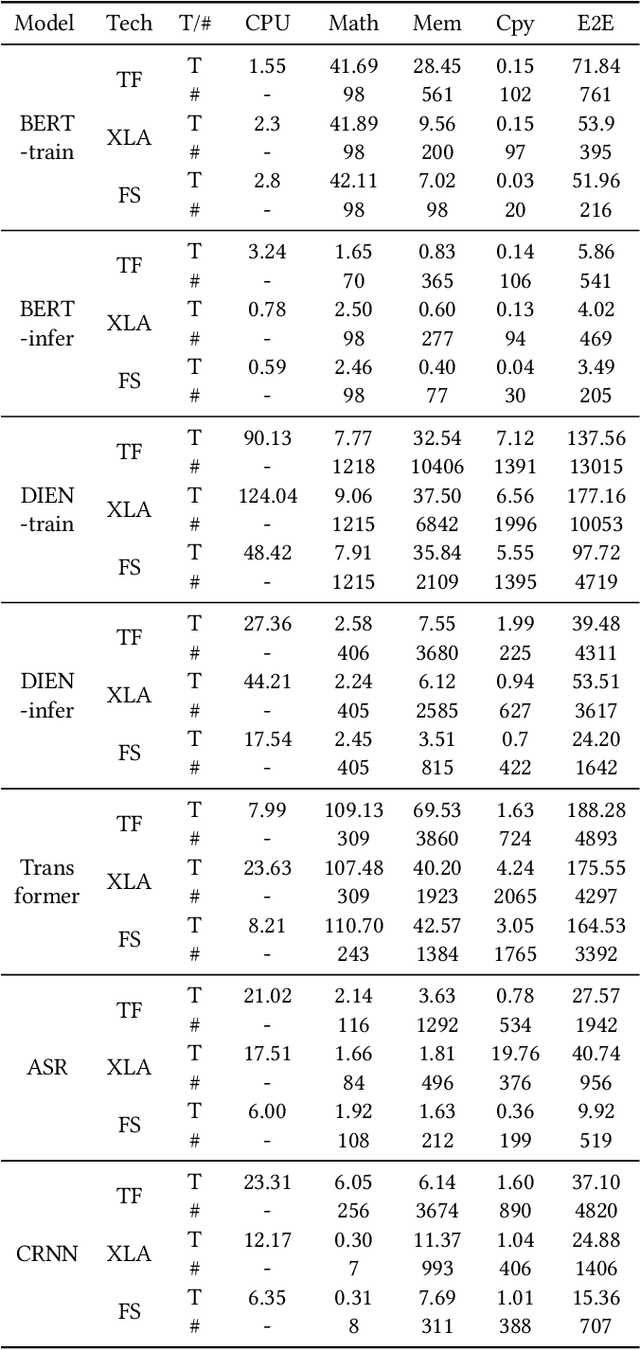

We show in this work that memory intensive computations can result in severe performance problems due to off-chip memory access and CPU-GPU context switch overheads in a wide range of deep learning models. For this problem, current just-in-time kernel fusion and code generation techniques have limitations, such as kernel schedule incompatibilities and rough fusion plan exploration strategies. We propose FusionStitching, a Deep Learning compiler capable of fusing memory intensive operators, with varied data dependencies and non-homogeneous parallelism, into large GPU kernels to reduce global memory access and operation scheduling overhead automatically. FusionStitching explores large fusion spaces to decide optimal fusion plans with considerations of memory access costs, kernel calls and resource usage constraints. We thoroughly study the schemes to stitch operators together for complex scenarios. FusionStitching tunes the optimal stitching scheme just-in-time with a domain-specific cost model efficiently. Experimental results show that FusionStitching can reach up to 2.78x speedup compared to TensorFlow and current state-of-the-art. Besides these experimental results, we integrated our approach into a compiler product and deployed it onto a production cluster for AI workloads with thousands of GPUs. The system has been in operation for more than 4 months and saves 7,000 GPU hours on average for approximately 30,000 tasks per month.