 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Sense Is All You Need
Jan 11, 2025Artificial intelligence (AI) has made significant strides in recent years, yet it continues to struggle with a fundamental aspect of cognition present in all animals: common sense. Current AI systems, including those designed for complex tasks like autonomous driving, problem-solving challenges such as the Abstraction and Reasoning Corpus (ARC), and conversational benchmarks like the Turing Test, often lack the ability to adapt to new situations without extensive prior knowledge. This manuscript argues that integrating common sense into AI systems is essential for achieving true autonomy and unlocking the full societal and commercial value of AI. We propose a shift in the order of knowledge acquisition emphasizing the importance of developing AI systems that start from minimal prior knowledge and are capable of contextual learning, adaptive reasoning, and embodiment -- even within abstract domains. Additionally, we highlight the need to rethink the AI software stack to address this foundational challenge. Without common sense, AI systems may never reach true autonomy, instead exhibiting asymptotic performance that approaches theoretical ideals like AIXI but remains unattainable in practice due to infinite resource and computation requirements. While scaling AI models and passing benchmarks like the Turing Test have brought significant advancements in applications that do not require autonomy, these approaches alone are insufficient to achieve autonomous AI with common sense. By redefining existing benchmarks and challenges to enforce constraints that require genuine common sense, and by broadening our understanding of embodiment to include both physical and abstract domains, we can encourage the development of AI systems better equipped to handle the complexities of real-world and abstract environments.
VLTP: Vision-Language Guided Token Pruning for Task-Oriented Segmentation
Sep 13, 2024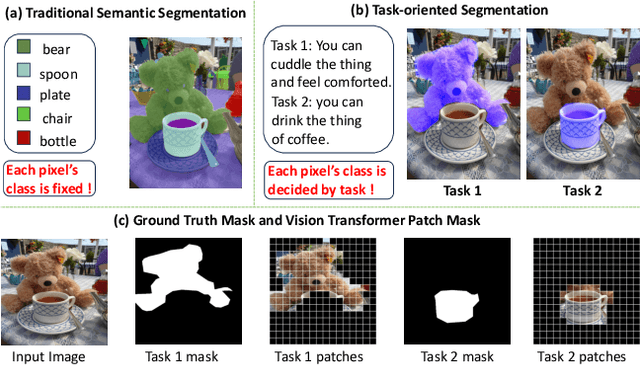
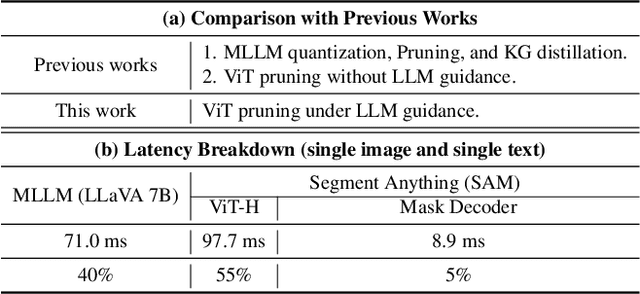
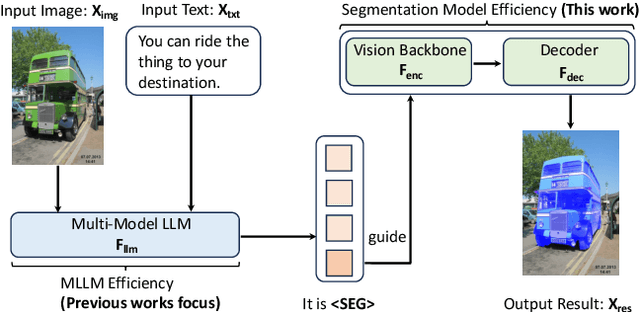
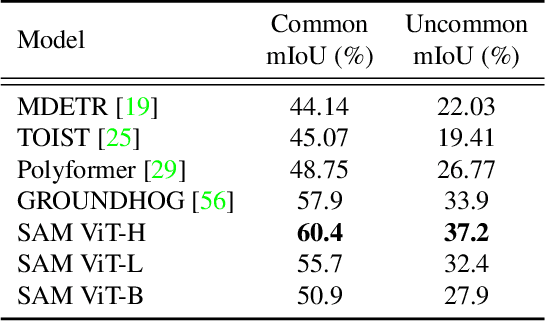
Vision Transformers (ViTs) have emerged as the backbone of many segmentation models, consistently achieving state-of-the-art (SOTA) performance. However, their success comes at a significant computational cost. Image token pruning is one of the most effective strategies to address this complexity. However, previous approaches fall short when applied to more complex task-oriented segmentation (TOS), where the class of each image patch is not predefined but dependent on the specific input task. This work introduces the Vision Language Guided Token Pruning (VLTP), a novel token pruning mechanism that can accelerate ViTbased segmentation models, particularly for TOS guided by multi-modal large language model (MLLM). We argue that ViT does not need to process every image token through all of its layers only the tokens related to reasoning tasks are necessary. We design a new pruning decoder to take both image tokens and vision-language guidance as input to predict the relevance of each image token to the task. Only image tokens with high relevance are passed to deeper layers of the ViT. Experiments show that the VLTP framework reduces the computational costs of ViT by approximately 25% without performance degradation and by around 40% with only a 1% performance drop.
Boosting Online 3D Multi-Object Tracking through Camera-Radar Cross Check
Jul 18, 2024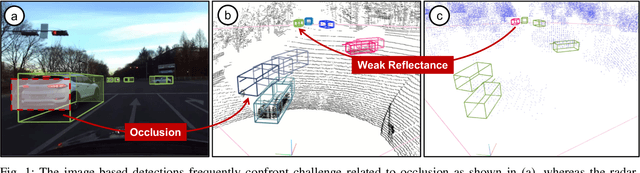
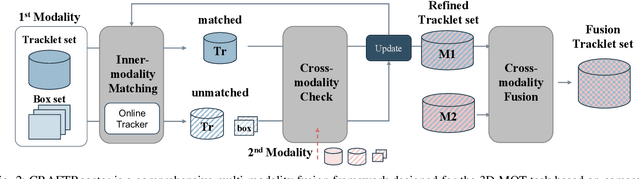
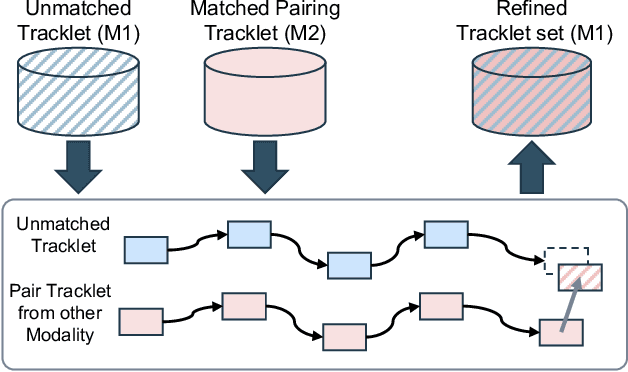
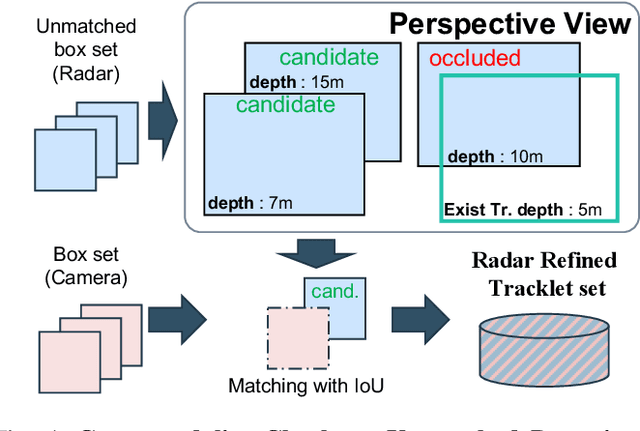
In the domain of autonomous driving, the integration of multi-modal perception techniques based on data from diverse sensors has demonstrated substantial progress. Effectively surpassing the capabilities of state-of-the-art single-modality detectors through sensor fusion remains an active challenge. This work leverages the respective advantages of cameras in perspective view and radars in Bird's Eye View (BEV) to greatly enhance overall detection and tracking performance. Our approach, Camera-Radar Associated Fusion Tracking Booster (CRAFTBooster), represents a pioneering effort to enhance radar-camera fusion in the tracking stage, contributing to improved 3D MOT accuracy. The superior experimental results on the K-Radaar dataset, which exhibit 5-6% on IDF1 tracking performance gain, validate the potential of effective sensor fusion in advancing autonomous driving.
DεpS: Delayed ε-Shrinking for Faster Once-For-All Training
Jul 08, 2024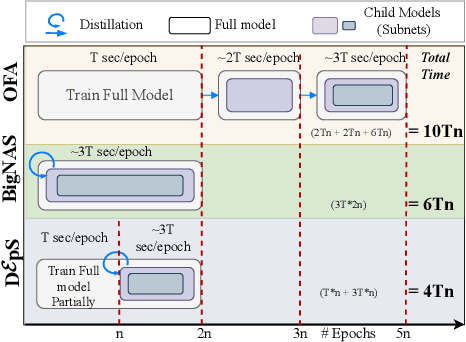

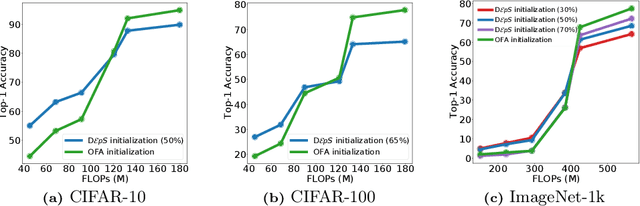

CNNs are increasingly deployed across different hardware, dynamic environments, and low-power embedded devices. This has led to the design and training of CNN architectures with the goal of maximizing accuracy subject to such variable deployment constraints. As the number of deployment scenarios grows, there is a need to find scalable solutions to design and train specialized CNNs. Once-for-all training has emerged as a scalable approach that jointly co-trains many models (subnets) at once with a constant training cost and finds specialized CNNs later. The scalability is achieved by training the full model and simultaneously reducing it to smaller subnets that share model weights (weight-shared shrinking). However, existing once-for-all training approaches incur huge training costs reaching 1200 GPU hours. We argue this is because they either start the process of shrinking the full model too early or too late. Hence, we propose Delayed $\epsilon$-Shrinking (D$\epsilon$pS) that starts the process of shrinking the full model when it is partially trained (~50%) which leads to training cost improvement and better in-place knowledge distillation to smaller models. The proposed approach also consists of novel heuristics that dynamically adjust subnet learning rates incrementally (E), leading to improved weight-shared knowledge distillation from larger to smaller subnets as well. As a result, DEpS outperforms state-of-the-art once-for-all training techniques across different datasets including CIFAR10/100, ImageNet-100, and ImageNet-1k on accuracy and cost. It achieves 1.83% higher ImageNet-1k top1 accuracy or the same accuracy with 1.3x reduction in FLOPs and 2.5x drop in training cost (GPU*hrs)
TaskCLIP: Extend Large Vision-Language Model for Task Oriented Object Detection
Mar 12, 2024Task-oriented object detection aims to find objects suitable for accomplishing specific tasks. As a challenging task, it requires simultaneous visual data processing and reasoning under ambiguous semantics. Recent solutions are mainly all-in-one models. However, the object detection backbones are pre-trained without text supervision. Thus, to incorporate task requirements, their intricate models undergo extensive learning on a highly imbalanced and scarce dataset, resulting in capped performance, laborious training, and poor generalizability. In contrast, we propose TaskCLIP, a more natural two-stage design composed of general object detection and task-guided object selection. Particularly for the latter, we resort to the recently successful large Vision-Language Models (VLMs) as our backbone, which provides rich semantic knowledge and a uniform embedding space for images and texts. Nevertheless, the naive application of VLMs leads to sub-optimal quality, due to the misalignment between embeddings of object images and their visual attributes, which are mainly adjective phrases. To this end, we design a transformer-based aligner after the pre-trained VLMs to re-calibrate both embeddings. Finally, we employ a trainable score function to post-process the VLM matching results for object selection. Experimental results demonstrate that our TaskCLIP outperforms the state-of-the-art DETR-based model TOIST by 3.5% and only requires a single NVIDIA RTX 4090 for both training and inference.
HDReason: Algorithm-Hardware Codesign for Hyperdimensional Knowledge Graph Reasoning
Mar 09, 2024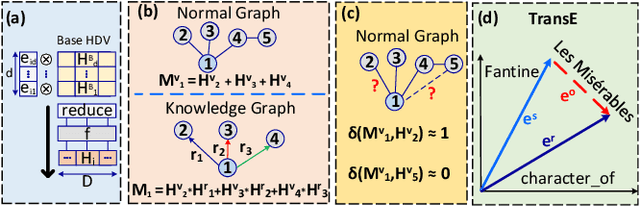
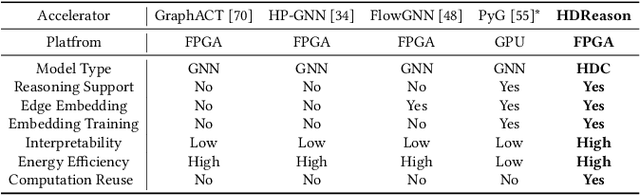

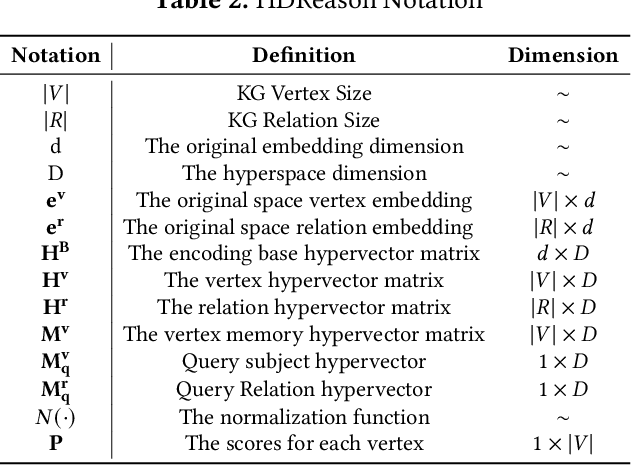
In recent times, a plethora of hardware accelerators have been put forth for graph learning applications such as vertex classification and graph classification. However, previous works have paid little attention to Knowledge Graph Completion (KGC), a task that is well-known for its significantly higher algorithm complexity. The state-of-the-art KGC solutions based on graph convolution neural network (GCN) involve extensive vertex/relation embedding updates and complicated score functions, which are inherently cumbersome for acceleration. As a result, existing accelerator designs are no longer optimal, and a novel algorithm-hardware co-design for KG reasoning is needed. Recently, brain-inspired HyperDimensional Computing (HDC) has been introduced as a promising solution for lightweight machine learning, particularly for graph learning applications. In this paper, we leverage HDC for an intrinsically more efficient and acceleration-friendly KGC algorithm. We also co-design an acceleration framework named HDReason targeting FPGA platforms. On the algorithm level, HDReason achieves a balance between high reasoning accuracy, strong model interpretability, and less computation complexity. In terms of architecture, HDReason offers reconfigurability, high training throughput, and low energy consumption. When compared with NVIDIA RTX 4090 GPU, the proposed accelerator achieves an average 10.6x speedup and 65x energy efficiency improvement. When conducting cross-models and cross-platforms comparison, HDReason yields an average 4.2x higher performance and 3.4x better energy efficiency with similar accuracy versus the state-of-the-art FPGA-based GCN training platform.
Middleware for LLMs: Tools Are Instrumental for Language Agents in Complex Environments
Feb 22, 2024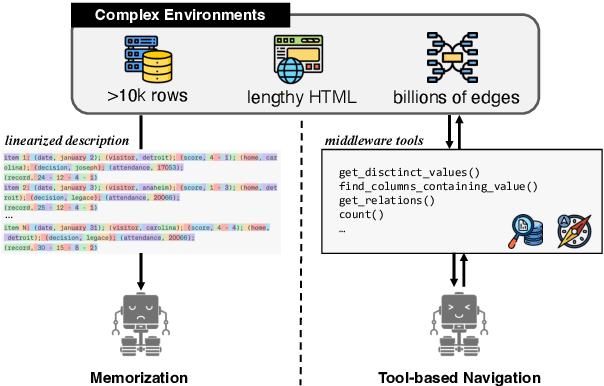



The applications of large language models (LLMs) have expanded well beyond the confines of text processing, signaling a new era where LLMs are envisioned as generalist language agents capable of operating within complex real-world environments. These environments are often highly expansive, making it impossible for the LLM to process them within its short-term memory. Motivated by recent research on extending the capabilities of LLMs with tools, this paper investigates the intriguing potential of tools to augment LLMs in handling such complexity. To this end, we design customized tools to aid in the proactive exploration within these massive environments. Such tools can serve as a middleware layer shielding the LLM from environmental complexity. In two representative complex environments -- knowledge bases (KBs) and databases -- we demonstrate the significant potential of augmenting language agents with tools in complex environments. Notably, equipped with these tools, GPT-4 achieves 2.8X the performance of the best baseline in tasks requiring access to database content and 2.2X in KB tasks. Our findings illuminate the path for advancing language agents in complex real-world applications.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
Nov 04, 2023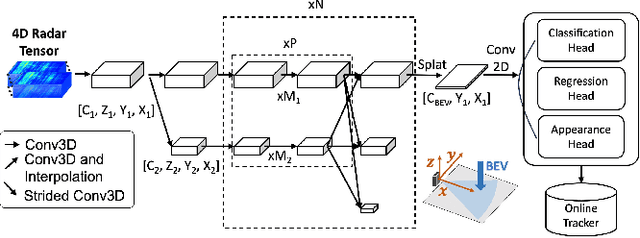
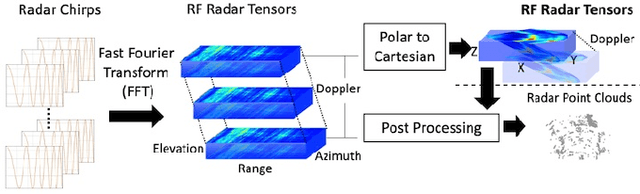
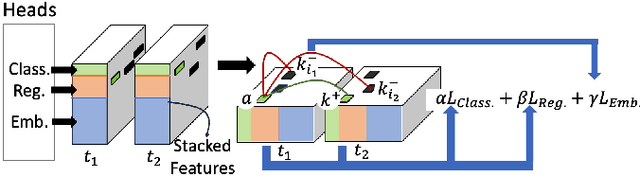
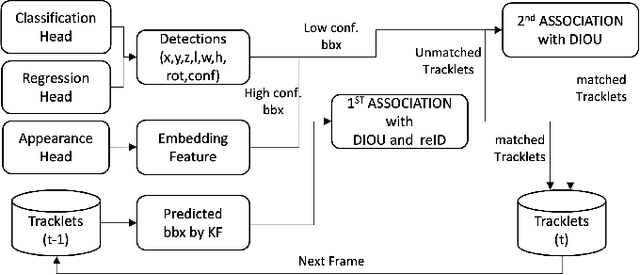
Robust perception is a vital component for ensuring safe autonomous and assisted driving. Automotive radar (77 to 81 GHz), which offers weather-resilient sensing, provides a complementary capability to the vision- or LiDAR-based autonomous driving systems. Raw radio-frequency (RF) radar tensors contain rich spatiotemporal semantics besides 3D location information. The majority of previous methods take in 3D (Doppler-range-azimuth) RF radar tensors, allowing prediction of an object's location, heading angle, and size in bird's-eye-view (BEV). However, they lack the ability to at the same time infer objects' size, orientation, and identity in the 3D space. To overcome this limitation, we propose an efficient joint architecture called CenterRadarNet, designed to facilitate high-resolution representation learning from 4D (Doppler-range-azimuth-elevation) radar data for 3D object detection and re-identification (re-ID) tasks. As a single-stage 3D object detector, CenterRadarNet directly infers the BEV object distribution confidence maps, corresponding 3D bounding box attributes, and appearance embedding for each pixel. Moreover, we build an online tracker utilizing the learned appearance embedding for re-ID. CenterRadarNet achieves the state-of-the-art result on the K-Radar 3D object detection benchmark. In addition, we present the first 3D object-tracking result using radar on the K-Radar dataset V2. In diverse driving scenarios, CenterRadarNet shows consistent, robust performance, emphasizing its wide applicability.
VQPy: An Object-Oriented Approach to Modern Video Analytics
Nov 03, 2023Video analytics is widely used in contemporary systems and services. At the forefront of video analytics are video queries that users develop to find objects of particular interest. Building upon the insight that video objects (e.g., human, animals, cars, etc.), the center of video analytics, are similar in spirit to objects modeled by traditional object-oriented languages, we propose to develop an object-oriented approach to video analytics. This approach, named VQPy, consists of a frontend$\unicode{x2015}$a Python variant with constructs that make it easy for users to express video objects and their interactions$\unicode{x2015}$as well as an extensible backend that can automatically construct and optimize pipelines based on video objects. We have implemented and open-sourced VQPy, which has been productized in Cisco as part of its DeepVision framework.
Ethosight: A Reasoning-Guided Iterative Learning System for Nuanced Perception based on Joint-Embedding & Contextual Label Affinity
Jul 21, 2023



Traditional computer vision models often require extensive manual effort for data acquisition, annotation and validation, particularly when detecting subtle behavioral nuances or events. The difficulty in distinguishing routine behaviors from potential risks in real-world applications, such as differentiating routine shopping from potential shoplifting, further complicates the process. Moreover, these models may demonstrate high false positive rates and imprecise event detection when exposed to real-world scenarios that differ significantly from the conditions of the training data. To overcome these hurdles, we present Ethosight, a novel zero-shot computer vision system. Ethosight initiates with a clean slate based on user requirements and semantic knowledge of interest. Using localized label affinity calculations and a reasoning-guided iterative learning loop, Ethosight infers scene details and iteratively refines the label set. Reasoning mechanisms can be derived from large language models like GPT4, symbolic reasoners like OpenNARS\cite{wang2013}\cite{wang2006}, or hybrid systems. Our evaluations demonstrate Ethosight's efficacy across 40 complex use cases, spanning domains such as health, safety, and security. Detailed results and case studies within the main body of this paper and an appendix underscore a promising trajectory towards enhancing the adaptability and resilience of computer vision models in detecting and extracting subtle and nuanced behaviors.