 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSL-HDnn: A 5.7 TOPS/W End-to-end Few-shot Learning Classifier Accelerator with Feature Extraction and Hyperdimensional Computing
Sep 17, 2024



This paper introduces FSL-HDnn, an energy-efficient accelerator that implements the end-to-end pipeline of feature extraction, classification, and on-chip few-shot learning (FSL) through gradient-free learning techniques in a 40 nm CMOS process. At its core, FSL-HDnn integrates two low-power modules: Weight clustering feature extractor and Hyperdimensional Computing (HDC). Feature extractor utilizes advanced weight clustering and pattern reuse strategies for optimized CNN-based feature extraction. Meanwhile, HDC emerges as a novel approach for lightweight FSL classifier, employing hyperdimensional vectors to improve training accuracy significantly compared to traditional distance-based approaches. This dual-module synergy not only simplifies the learning process by eliminating the need for complex gradients but also dramatically enhances energy efficiency and performance. Specifically, FSL-HDnn achieves an Intensity unprecedented energy efficiency of 5.7 TOPS/W for feature 1 extraction and 0.78 TOPS/W for classification and learning Training Intensity phases, achieving improvements of 2.6X and 6.6X, respectively, Storage over current state-of-the-art CNN and FSL processors.
HDReason: Algorithm-Hardware Codesign for Hyperdimensional Knowledge Graph Reasoning
Mar 09, 2024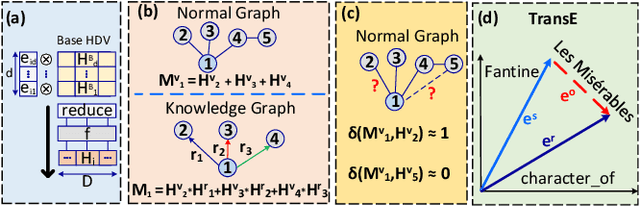
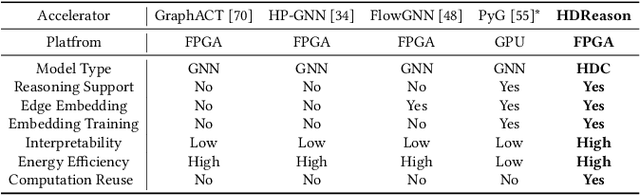

In recent times, a plethora of hardware accelerators have been put forth for graph learning applications such as vertex classification and graph classification. However, previous works have paid little attention to Knowledge Graph Completion (KGC), a task that is well-known for its significantly higher algorithm complexity. The state-of-the-art KGC solutions based on graph convolution neural network (GCN) involve extensive vertex/relation embedding updates and complicated score functions, which are inherently cumbersome for acceleration. As a result, existing accelerator designs are no longer optimal, and a novel algorithm-hardware co-design for KG reasoning is needed. Recently, brain-inspired HyperDimensional Computing (HDC) has been introduced as a promising solution for lightweight machine learning, particularly for graph learning applications. In this paper, we leverage HDC for an intrinsically more efficient and acceleration-friendly KGC algorithm. We also co-design an acceleration framework named HDReason targeting FPGA platforms. On the algorithm level, HDReason achieves a balance between high reasoning accuracy, strong model interpretability, and less computation complexity. In terms of architecture, HDReason offers reconfigurability, high training throughput, and low energy consumption. When compared with NVIDIA RTX 4090 GPU, the proposed accelerator achieves an average 10.6x speedup and 65x energy efficiency improvement. When conducting cross-models and cross-platforms comparison, HDReason yields an average 4.2x higher performance and 3.4x better energy efficiency with similar accuracy versus the state-of-the-art FPGA-based GCN training platform.
HD-Bind: Encoding of Molecular Structure with Low Precision, Hyperdimensional Binary Representations
Mar 27, 2023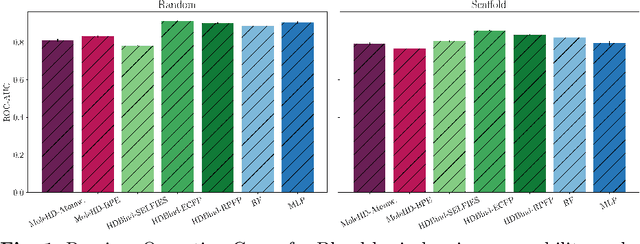
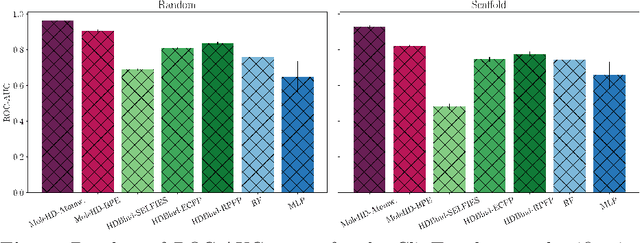
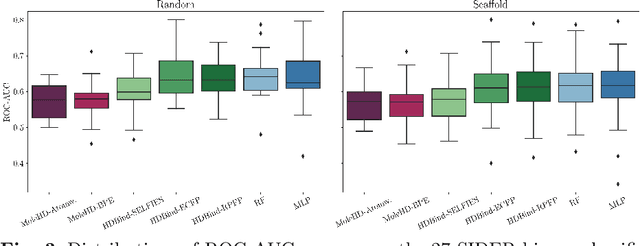
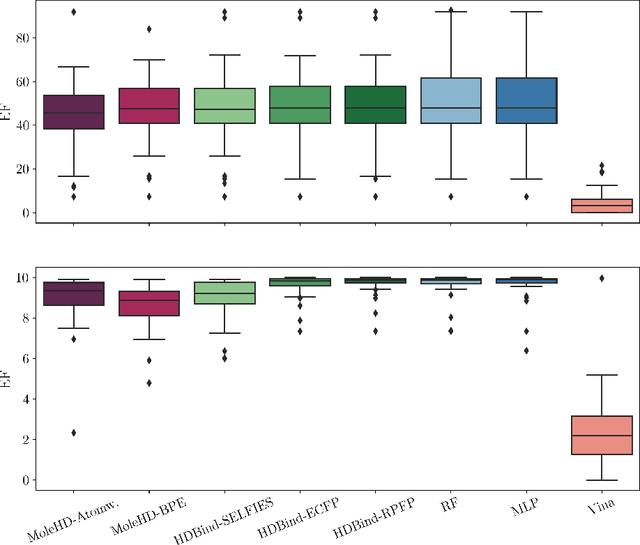
Publicly available collections of drug-like molecules have grown to comprise 10s of billions of possibilities in recent history due to advances in chemical synthesis. Traditional methods for identifying ``hit'' molecules from a large collection of potential drug-like candidates have relied on biophysical theory to compute approximations to the Gibbs free energy of the binding interaction between the drug to its protein target. A major drawback of the approaches is that they require exceptional computing capabilities to consider for even relatively small collections of molecules. Hyperdimensional Computing (HDC) is a recently proposed learning paradigm that is able to leverage low-precision binary vector arithmetic to build efficient representations of the data that can be obtained without the need for gradient-based optimization approaches that are required in many conventional machine learning and deep learning approaches. This algorithmic simplicity allows for acceleration in hardware that has been previously demonstrated for a range of application areas. We consider existing HDC approaches for molecular property classification and introduce two novel encoding algorithms that leverage the extended connectivity fingerprint (ECFP) algorithm. We show that HDC-based inference methods are as much as 90 times more efficient than more complex representative machine learning methods and achieve an acceleration of nearly 9 orders of magnitude as compared to inference with molecular docking. We demonstrate multiple approaches for the encoding of molecular data for HDC and examine their relative performance on a range of challenging molecular property prediction and drug-protein binding classification tasks. Our work thus motivates further investigation into molecular representation learning to develop ultra-efficient pre-screening tools.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022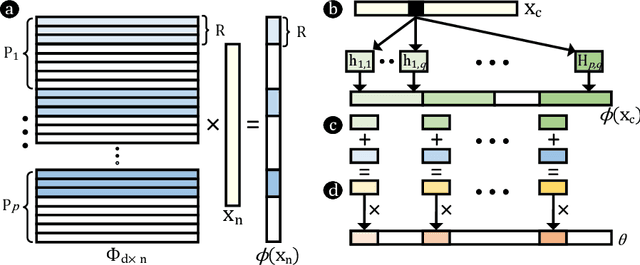


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
SHEARer: Highly-Efficient Hyperdimensional Computing by Software-Hardware Enabled Multifold Approximation
Jul 20, 2020


Hyperdimensional computing (HD) is an emerging paradigm for machine learning based on the evidence that the brain computes on high-dimensional, distributed, representations of data. The main operation of HD is encoding, which transfers the input data to hyperspace by mapping each input feature to a hypervector, accompanied by so-called bundling procedure that simply adds up the hypervectors to realize encoding hypervector. Although the operations of HD are highly parallelizable, the massive number of operations hampers the efficiency of HD in embedded domain. In this paper, we propose SHEARer, an algorithm-hardware co-optimization to improve the performance and energy consumption of HD computing. We gain insight from a prudent scheme of approximating the hypervectors that, thanks to inherent error resiliency of HD, has minimal impact on accuracy while provides high prospect for hardware optimization. In contrast to previous works that generate the encoding hypervectors in full precision and then ex-post quantizing, we compute the encoding hypervectors in an approximate manner that saves a significant amount of resources yet affords high accuracy. We also propose a novel FPGA implementation that achieves striking performance through massive parallelism with low power consumption. Moreover, we develop a software framework that enables training HD models by emulating the proposed approximate encodings. The FPGA implementation of SHEARer achieves an average throughput boost of 104,904x (15.7x) and energy savings of up to 56,044x (301x) compared to state-of-the-art encoding methods implemented on Raspberry Pi 3 (GeForce GTX 1080 Ti) using practical machine learning datasets.
Prive-HD: Privacy-Preserved Hyperdimensional Computing
May 14, 2020



The privacy of data is a major challenge in machine learning as a trained model may expose sensitive information of the enclosed dataset. Besides, the limited computation capability and capacity of edge devices have made cloud-hosted inference inevitable. Sending private information to remote servers makes the privacy of inference also vulnerable because of susceptible communication channels or even untrustworthy hosts. In this paper, we target privacy-preserving training and inference of brain-inspired Hyperdimensional (HD) computing, a new learning algorithm that is gaining traction due to its light-weight computation and robustness particularly appealing for edge devices with tight constraints. Indeed, despite its promising attributes, HD computing has virtually no privacy due to its reversible computation. We present an accuracy-privacy trade-off method through meticulous quantization and pruning of hypervectors, the building blocks of HD, to realize a differentially private model as well as to obfuscate the information sent for cloud-hosted inference. Finally, we show how the proposed techniques can be also leveraged for efficient hardware implementation.