 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleSumm: Adaptive Triple-Modality Fusion for Video Summarization
Mar 01, 2026The exponential growth of video content necessitates effective video summarization to efficiently extract key information from long videos. However, current approaches struggle to fully comprehend complex videos, primarily because they employ static or modality-agnostic fusion strategies. These methods fail to account for the dynamic, frame-dependent variations in modality saliency inherent in video data. To overcome these limitations, we propose TripleSumm, a novel architecture that adaptively weights and fuses the contributions of visual, text, and audio modalities at the frame level. Furthermore, a significant bottleneck for research into multimodal video summarization has been the lack of comprehensive benchmarks. Addressing this bottleneck, we introduce MoSu (Most Replayed Multimodal Video Summarization), the first large-scale benchmark that provides all three modalities. Extensive experiments demonstrate that TripleSumm achieves state-of-the-art performance, outperforming existing methods by a significant margin on four benchmarks, including MoSu. Our code and dataset are available at https://github.com/smkim37/TripleSumm.
VERSA: Verified Event Data Format for Reliable Soccer Analytics
Jan 29, 2026Event stream data is a critical resource for fine-grained analysis across various domains, including financial transactions, system operations, and sports. In sports, it is actively used for fine-grained analyses such as quantifying player contributions and identifying tactical patterns. However, the reliability of these models is fundamentally limited by inherent data quality issues that cause logical inconsistencies (e.g., incorrect event ordering or missing events). To this end, this study proposes VERSA (Verified Event Data Format for Reliable Soccer Analytics), a systematic verification framework that ensures the integrity of event stream data within the soccer domain. VERSA is based on a state-transition model that defines valid event sequences, thereby enabling the automatic detection and correction of anomalous patterns within the event stream data. Notably, our examination of event data from the K League 1 (2024 season), provided by Bepro, detected that 18.81% of all recorded events exhibited logical inconsistencies. Addressing such integrity issues, our experiments demonstrate that VERSA significantly enhances cross-provider consistency, ensuring stable and unified data representation across heterogeneous sources. Furthermore, we demonstrate that data refined by VERSA significantly improves the robustness and performance of a downstream task called VAEP, which evaluates player contributions. These results highlight that the verification process is highly effective in increasing the reliability of data-driven analysis.
Sangam: Chiplet-Based DRAM-PIM Accelerator with CXL Integration for LLM Inferencing
Nov 15, 2025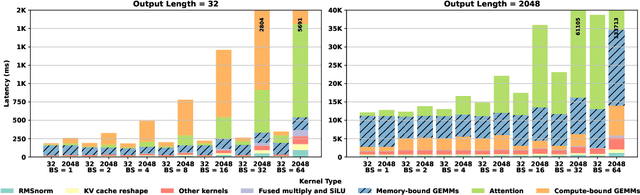
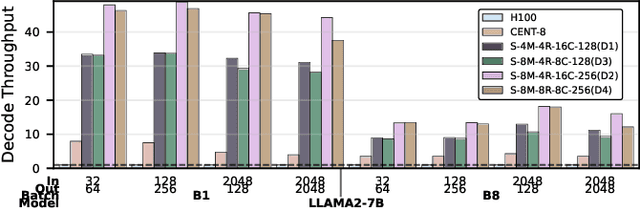
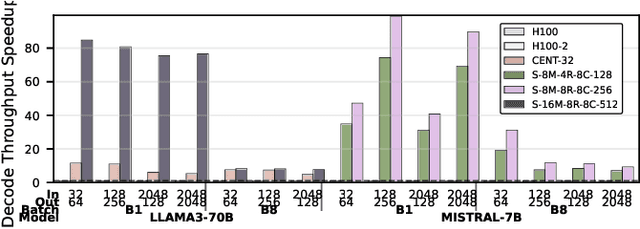
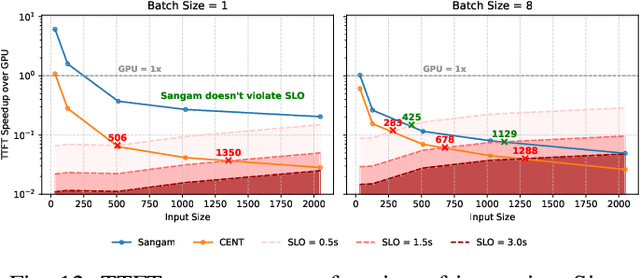
Large Language Models (LLMs) are becoming increasingly data-intensive due to growing model sizes, and they are becoming memory-bound as the context length and, consequently, the key-value (KV) cache size increase. Inference, particularly the decoding phase, is dominated by memory-bound GEMV or flat GEMM operations with low operational intensity (OI), making it well-suited for processing-in-memory (PIM) approaches. However, existing in/near-memory solutions face critical limitations such as reduced memory capacity due to the high area cost of integrating processing elements (PEs) within DRAM chips, and limited PE capability due to the constraints of DRAM fabrication technology. This work presents a chiplet-based memory module that addresses these limitations by decoupling logic and memory into chiplets fabricated in heterogeneous technology nodes and connected via an interposer. The logic chiplets sustain high bandwidth access to the DRAM chiplets, which house the memory banks, and enable the integration of advanced processing components such as systolic arrays and SRAM-based buffers to accelerate memory-bound GEMM kernels, capabilities that were not feasible in prior PIM architectures. We propose Sangam, a CXL-attached PIM-chiplet based memory module that can either act as a drop-in replacement for GPUs or co-executes along side the GPUs. Sangam achieves speedup of 3.93, 4.22, 2.82x speedup in end-to-end query latency, 10.3, 9.5, 6.36x greater decoding throughput, and order of magnitude energy savings compared to an H100 GPU for varying input size, output length, and batch size on LLaMA 2-7B, Mistral-7B, and LLaMA 3-70B, respectively.
Clo-HDnn: A 4.66 TFLOPS/W and 3.78 TOPS/W Continual On-Device Learning Accelerator with Energy-efficient Hyperdimensional Computing via Progressive Search
Jul 23, 2025Clo-HDnn is an on-device learning (ODL) accelerator designed for emerging continual learning (CL) tasks. Clo-HDnn integrates hyperdimensional computing (HDC) along with low-cost Kronecker HD Encoder and weight clustering feature extraction (WCFE) to optimize accuracy and efficiency. Clo-HDnn adopts gradient-free CL to efficiently update and store the learned knowledge in the form of class hypervectors. Its dual-mode operation enables bypassing costly feature extraction for simpler datasets, while progressive search reduces complexity by up to 61% by encoding and comparing only partial query hypervectors. Achieving 4.66 TFLOPS/W (FE) and 3.78 TOPS/W (classifier), Clo-HDnn delivers 7.77x and 4.85x higher energy efficiency compared to SOTA ODL accelerators.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024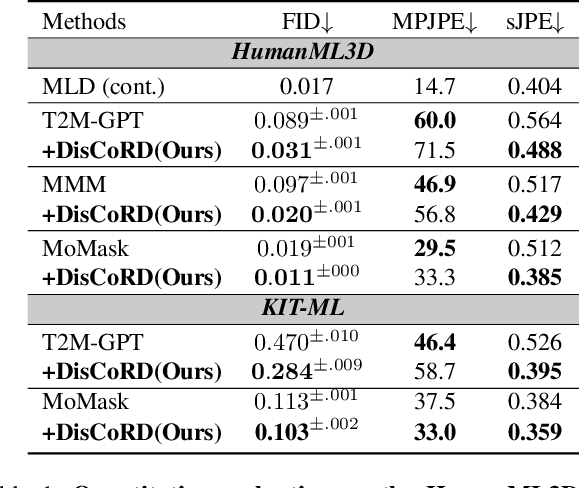
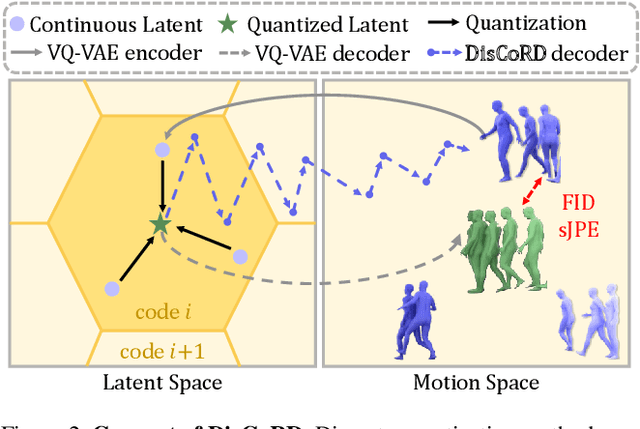
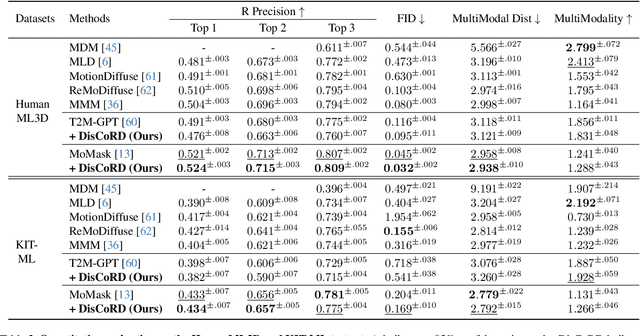
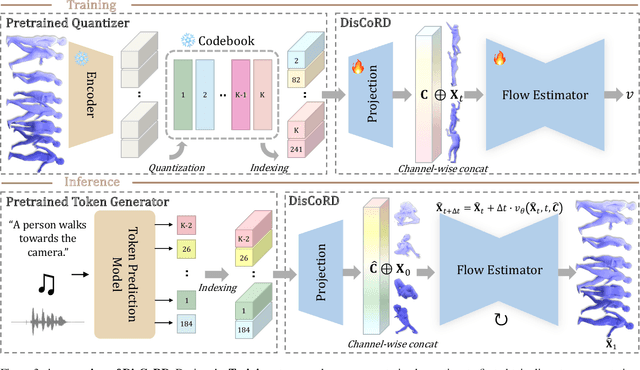
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.
SoftLMs: Efficient Adaptive Low-Rank Approximation of Language Models using Soft-Thresholding Mechanism
Nov 15, 2024



Extensive efforts have been made to boost the performance in the domain of language models by introducing various attention-based transformers. However, the inclusion of linear layers with large dimensions contributes to significant computational and memory overheads. The escalating computational demands of these models necessitate the development of various compression techniques to ensure their deployment on devices, particularly in resource-constrained environments. In this paper, we propose a novel compression methodology that dynamically determines the rank of each layer using a soft thresholding mechanism, which clips the singular values with a small magnitude in a differentiable form. This approach automates the decision-making process to identify the optimal degree of compression for each layer. We have successfully applied the proposed technique to attention-based architectures, including BERT for discriminative tasks and GPT2 and TinyLlama for generative tasks. Additionally, we have validated our method on Mamba, a recently proposed state-space model. Our experiments demonstrate that the proposed technique achieves a speed-up of 1.33X to 1.72X in the encoder/ decoder with a 50% reduction in total parameters.
SpecPCM: A Low-power PCM-based In-Memory Computing Accelerator for Full-stack Mass Spectrometry Analysis
Nov 14, 2024



Mass spectrometry (MS) is essential for proteomics and metabolomics but faces impending challenges in efficiently processing the vast volumes of data. This paper introduces SpecPCM, an in-memory computing (IMC) accelerator designed to achieve substantial improvements in energy and delay efficiency for both MS spectral clustering and database (DB) search. SpecPCM employs analog processing with low-voltage swing and utilizes recently introduced phase change memory (PCM) devices based on superlattice materials, optimized for low-voltage and low-power programming. Our approach integrates contributions across multiple levels: application, algorithm, circuit, device, and instruction sets. We leverage a robust hyperdimensional computing (HD) algorithm with a novel dimension-packing method and develop specialized hardware for the end-to-end MS pipeline to overcome the non-ideal behavior of PCM devices. We further optimize multi-level PCM devices for different tasks by using different materials. We also perform a comprehensive design exploration to improve energy and delay efficiency while maintaining accuracy, exploring various combinations of hardware and software parameters controlled by the instruction set architecture (ISA). SpecPCM, with up to three bits per cell, achieves speedups of up to 82x and 143x for MS clustering and DB search tasks, respectively, along with a four-orders-of-magnitude improvement in energy efficiency compared with state-of-the-art CPU/GPU tools.
MaD-Scientist: AI-based Scientist solving Convection-Diffusion-Reaction Equations Using Massive PINN-Based Prior Data
Oct 09, 2024



Large language models (LLMs), like ChatGPT, have shown that even trained with noisy prior data, they can generalize effectively to new tasks through in-context learning (ICL) and pre-training techniques. Motivated by this, we explore whether a similar approach can be applied to scientific foundation models (SFMs). Our methodology is structured as follows: (i) we collect low-cost physics-informed neural network (PINN)-based approximated prior data in the form of solutions to partial differential equations (PDEs) constructed through an arbitrary linear combination of mathematical dictionaries; (ii) we utilize Transformer architectures with self and cross-attention mechanisms to predict PDE solutions without knowledge of the governing equations in a zero-shot setting; (iii) we provide experimental evidence on the one-dimensional convection-diffusion-reaction equation, which demonstrate that pre-training remains robust even with approximated prior data, with only marginal impacts on test accuracy. Notably, this finding opens the path to pre-training SFMs with realistic, low-cost data instead of (or in conjunction with) numerical high-cost data. These results support the conjecture that SFMs can improve in a manner similar to LLMs, where fully cleaning the vast set of sentences crawled from the Internet is nearly impossible.
FSL-HDnn: A 5.7 TOPS/W End-to-end Few-shot Learning Classifier Accelerator with Feature Extraction and Hyperdimensional Computing
Sep 17, 2024



This paper introduces FSL-HDnn, an energy-efficient accelerator that implements the end-to-end pipeline of feature extraction, classification, and on-chip few-shot learning (FSL) through gradient-free learning techniques in a 40 nm CMOS process. At its core, FSL-HDnn integrates two low-power modules: Weight clustering feature extractor and Hyperdimensional Computing (HDC). Feature extractor utilizes advanced weight clustering and pattern reuse strategies for optimized CNN-based feature extraction. Meanwhile, HDC emerges as a novel approach for lightweight FSL classifier, employing hyperdimensional vectors to improve training accuracy significantly compared to traditional distance-based approaches. This dual-module synergy not only simplifies the learning process by eliminating the need for complex gradients but also dramatically enhances energy efficiency and performance. Specifically, FSL-HDnn achieves an Intensity unprecedented energy efficiency of 5.7 TOPS/W for feature 1 extraction and 0.78 TOPS/W for classification and learning Training Intensity phases, achieving improvements of 2.6X and 6.6X, respectively, Storage over current state-of-the-art CNN and FSL processors.
An Analog and Digital Hybrid Attention Accelerator for Transformers with Charge-based In-memory Computing
Sep 08, 2024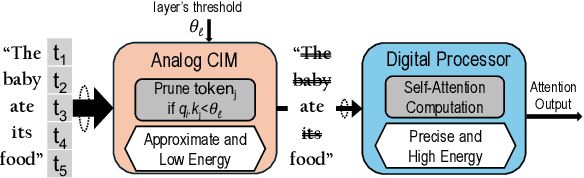
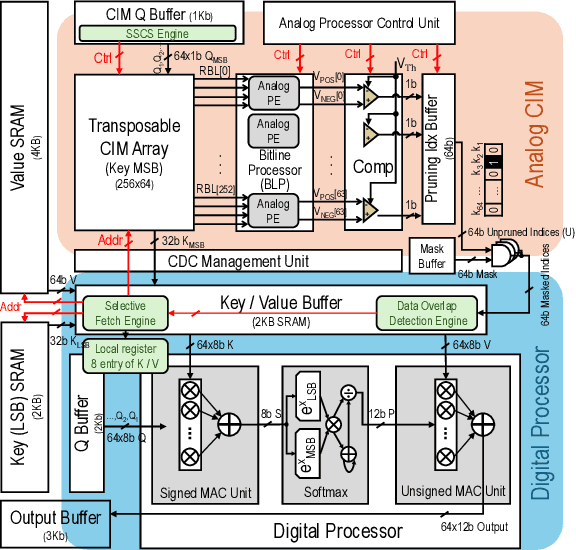
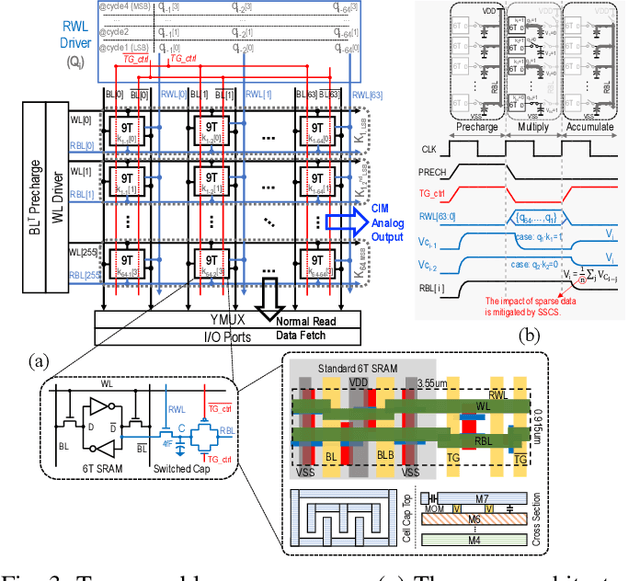
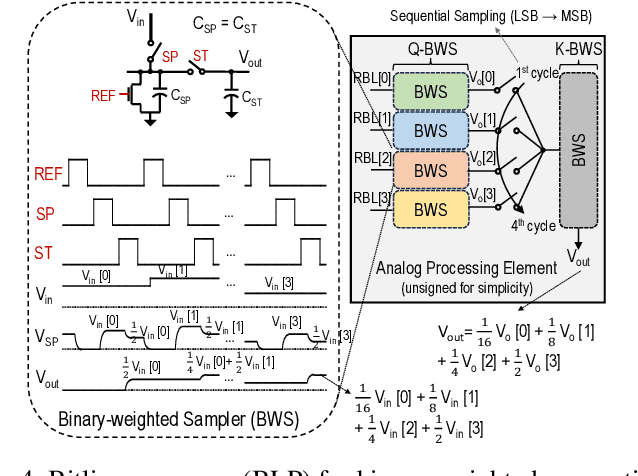
The attention mechanism is a key computing kernel of Transformers, calculating pairwise correlations across the entire input sequence. The computing complexity and frequent memory access in computing self-attention put a huge burden on the system especially when the sequence length increases. This paper presents an analog and digital hybrid processor to accelerate the attention mechanism for transformers in 65nm CMOS technology. We propose an analog computing-in-memory (CIM) core, which prunes ~75% of low-score tokens on average during runtime at ultra-low power and delay. Additionally, a digital processor performs precise computations only for ~25% unpruned tokens selected by the analog CIM core, preventing accuracy degradation. Measured results show peak energy efficiency of 14.8 and 1.65 TOPS/W, and peak area efficiency of 976.6 and 79.4 GOPS/mm$^\mathrm{2}$ in the analog core and the system-on-chip (SoC), respectively.