 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust automatic brain vessel segmentation in 3D CTA scans using dynamic 4D-CTA data
Jan 30, 2026In this study, we develop a novel methodology for annotating the brain vasculature using dynamic 4D-CTA head scans. By using multiple time points from dynamic CTA acquisitions, we subtract bone and soft tissue to enhance the visualization of arteries and veins, reducing the effort required to obtain manual annotations of brain vessels. We then train deep learning models on our ground truth annotations by using the same segmentation for multiple phases from the dynamic 4D-CTA collection, effectively enlarging our dataset by 4 to 5 times and inducing robustness to contrast phases. In total, our dataset comprises 110 training images from 25 patients and 165 test images from 14 patients. In comparison with two similarly-sized datasets for CTA-based brain vessel segmentation, a nnUNet model trained on our dataset can achieve significantly better segmentations across all vascular regions, with an average mDC of 0.846 for arteries and 0.957 for veins in the TopBrain dataset. Furthermore, metrics such as average directed Hausdorff distance (adHD) and topology sensitivity (tSens) reflected similar trends: using our dataset resulted in low error margins (aDHD of 0.304 mm for arteries and 0.078 for veins) and high sensitivity (tSens of 0.877 for arteries and 0.974 for veins), indicating excellent accuracy in capturing vessel morphology. Our code and model weights are available online: https://github.com/alceballosa/robust-vessel-segmentation
Automated anatomy-based post-processing reduces false positives and improved interpretability of deep learning intracranial aneurysm detection
Jul 01, 2025Introduction: Deep learning (DL) models can help detect intracranial aneurysms on CTA, but high false positive (FP) rates remain a barrier to clinical translation, despite improvement in model architectures and strategies like detection threshold tuning. We employed an automated, anatomy-based, heuristic-learning hybrid artery-vein segmentation post-processing method to further reduce FPs. Methods: Two DL models, CPM-Net and a deformable 3D convolutional neural network-transformer hybrid (3D-CNN-TR), were trained with 1,186 open-source CTAs (1,373 annotated aneurysms), and evaluated with 143 held-out private CTAs (218 annotated aneurysms). Brain, artery, vein, and cavernous venous sinus (CVS) segmentation masks were applied to remove possible FPs in the DL outputs that overlapped with: (1) brain mask; (2) vein mask; (3) vein more than artery masks; (4) brain plus vein mask; (5) brain plus vein more than artery masks. Results: CPM-Net yielded 139 true-positives (TP); 79 false-negative (FN); 126 FP. 3D-CNN-TR yielded 179 TP; 39 FN; 182 FP. FPs were commonly extracranial (CPM-Net 27.3%; 3D-CNN-TR 42.3%), venous (CPM-Net 56.3%; 3D-CNN-TR 29.1%), arterial (CPM-Net 11.9%; 3D-CNN-TR 53.3%), and non-vascular (CPM-Net 25.4%; 3D-CNN-TR 9.3%) structures. Method 5 performed best, reducing CPM-Net FP by 70.6% (89/126) and 3D-CNN-TR FP by 51.6% (94/182), without reducing TP, lowering the FP/case rate from 0.88 to 0.26 for CPM-NET, and from 1.27 to 0.62 for the 3D-CNN-TR. Conclusion: Anatomy-based, interpretable post-processing can improve DL-based aneurysm detection model performance. More broadly, automated, domain-informed, hybrid heuristic-learning processing holds promise for improving the performance and clinical acceptance of aneurysm detection models.
Layer-wise Update Aggregation with Recycling for Communication-Efficient Federated Learning
Mar 14, 2025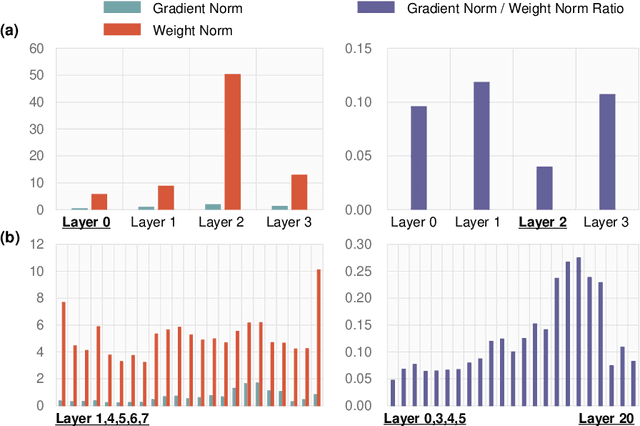

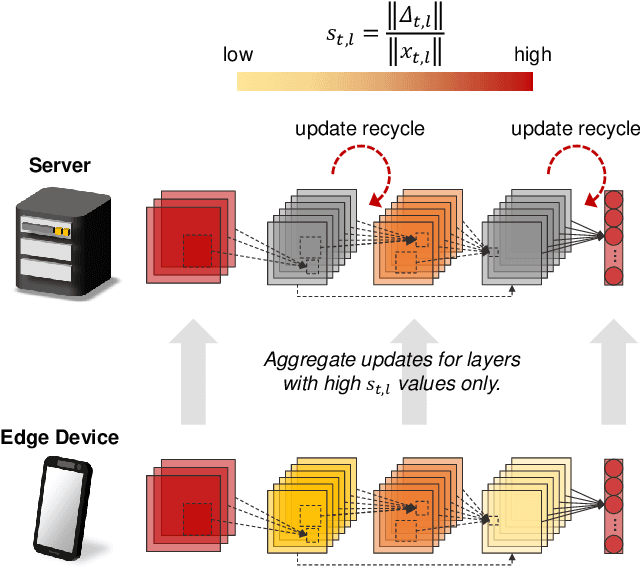
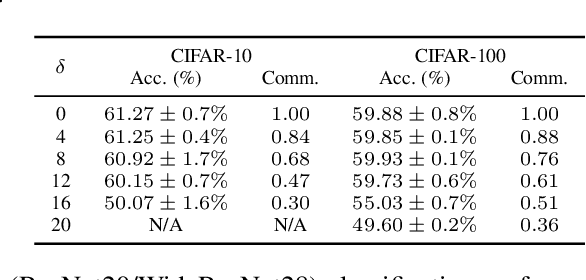
Expensive communication cost is a common performance bottleneck in Federated Learning (FL), which makes it less appealing in real-world applications. Many communication-efficient FL methods focus on discarding a part of model updates mostly based on gradient magnitude. In this study, we find that recycling previous updates, rather than simply dropping them, more effectively reduces the communication cost while maintaining FL performance. We propose FedLUAR, a Layer-wise Update Aggregation with Recycling scheme for communication-efficient FL. We first define a useful metric that quantifies the extent to which the aggregated gradients influences the model parameter values in each layer. FedLUAR selects a few layers based on the metric and recycles their previous updates on the server side. Our extensive empirical study demonstrates that the update recycling scheme significantly reduces the communication cost while maintaining model accuracy. For example, our method achieves nearly the same AG News accuracy as FedAvg, while reducing the communication cost to just 17%.
Anatomically-guided masked autoencoder pre-training for aneurysm detection
Feb 28, 2025Intracranial aneurysms are a major cause of morbidity and mortality worldwide, and detecting them manually is a complex, time-consuming task. Albeit automated solutions are desirable, the limited availability of training data makes it difficult to develop such solutions using typical supervised learning frameworks. In this work, we propose a novel pre-training strategy using more widely available unannotated head CT scan data to pre-train a 3D Vision Transformer model prior to fine-tuning for the aneurysm detection task. Specifically, we modify masked auto-encoder (MAE) pre-training in the following ways: we use a factorized self-attention mechanism to make 3D attention computationally viable, we restrict the masked patches to areas near arteries to focus on areas where aneurysms are likely to occur, and we reconstruct not only CT scan intensity values but also artery distance maps, which describe the distance between each voxel and the closest artery, thereby enhancing the backbone's learned representations. Compared with SOTA aneurysm detection models, our approach gains +4-8% absolute Sensitivity at a false positive rate of 0.5. Code and weights will be released.
Tabular-TX: Theme-Explanation Structure-based Table Summarization via In-Context Learning
Jan 17, 2025
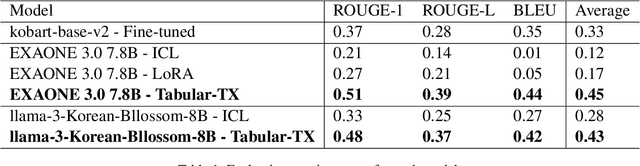

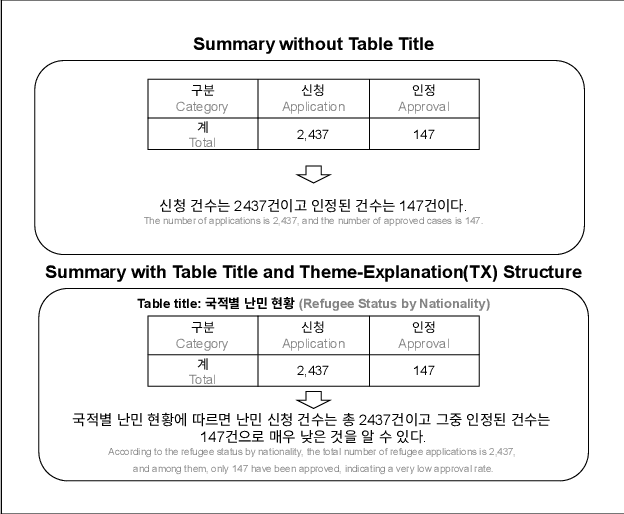
This paper proposes a Theme-Explanation Structure-based Table Summarization (Tabular-TX) pipeline designed to efficiently process table data. Tabular-TX preprocesses table data by focusing on highlighted cells and then generates summary sentences structured with a Theme Part in the form of adverbial phrases followed by an Explanation Part in the form of clauses. In this process, customized analysis is performed by considering the structural characteristics and comparability of the table. Additionally, by utilizing In-Context Learning, Tabular-TX optimizes the analytical capabilities of large language models (LLMs) without the need for fine-tuning, effectively handling the structural complexity of table data. Results from applying the proposed Tabular-TX to generate table-based summaries demonstrated superior performance compared to existing fine-tuning-based methods, despite limitations in dataset size. Experimental results confirmed that Tabular-TX can process complex table data more effectively and established it as a new alternative for table-based question answering and summarization tasks, particularly in resource-constrained environments.
Learning to Transfer Human Hand Skills for Robot Manipulations
Jan 07, 2025We present a method for teaching dexterous manipulation tasks to robots from human hand motion demonstrations. Unlike existing approaches that solely rely on kinematics information without taking into account the plausibility of robot and object interaction, our method directly infers plausible robot manipulation actions from human motion demonstrations. To address the embodiment gap between the human hand and the robot system, our approach learns a joint motion manifold that maps human hand movements, robot hand actions, and object movements in 3D, enabling us to infer one motion component from others. Our key idea is the generation of pseudo-supervision triplets, which pair human, object, and robot motion trajectories synthetically. Through real-world experiments with robot hand manipulation, we demonstrate that our data-driven retargeting method significantly outperforms conventional retargeting techniques, effectively bridging the embodiment gap between human and robotic hands. Website at https://rureadyo.github.io/MocapRobot/.
DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding
Dec 02, 2024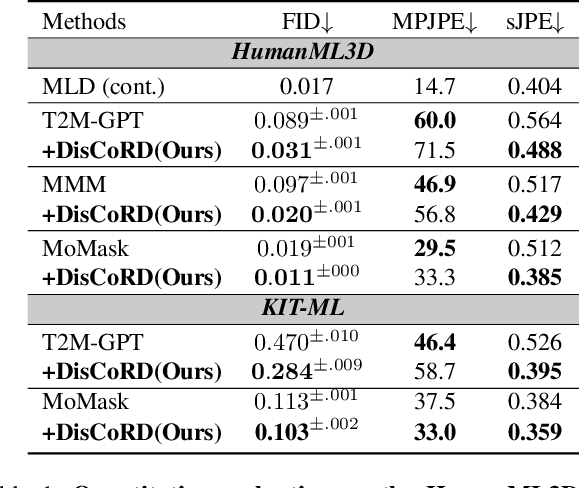
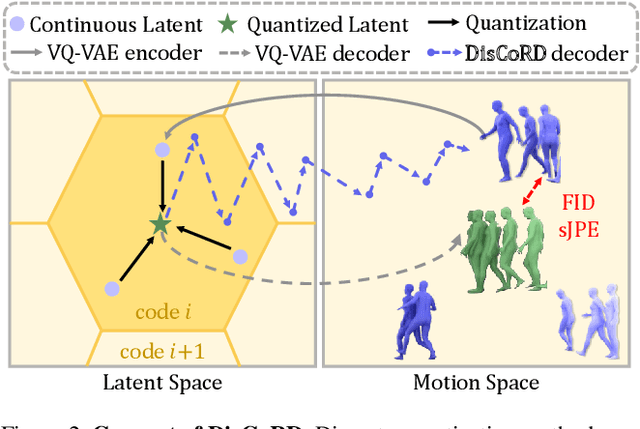
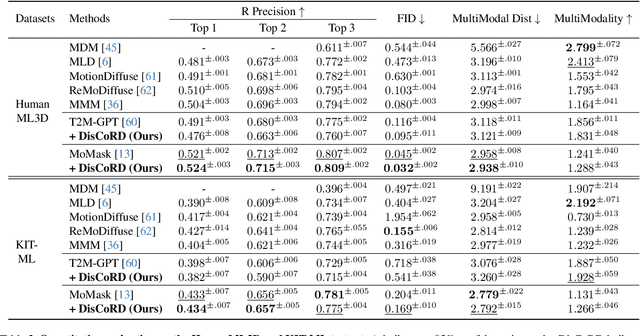
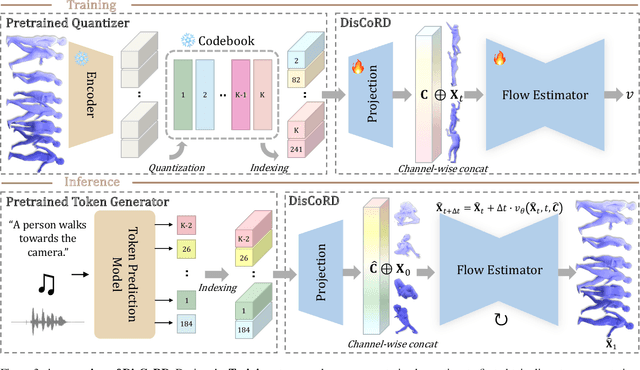
Human motion, inherently continuous and dynamic, presents significant challenges for generative models. Despite their dominance, discrete quantization methods, such as VQ-VAEs, suffer from inherent limitations, including restricted expressiveness and frame-wise noise artifacts. Continuous approaches, while producing smoother and more natural motions, often falter due to high-dimensional complexity and limited training data. To resolve this "discord" between discrete and continuous representations, we introduce DisCoRD: Discrete Tokens to Continuous Motion via Rectified Flow Decoding, a novel method that decodes discrete motion tokens into continuous motion through rectified flow. By employing an iterative refinement process in the continuous space, DisCoRD captures fine-grained dynamics and ensures smoother and more natural motions. Compatible with any discrete-based framework, our method enhances naturalness without compromising faithfulness to the conditioning signals. Extensive evaluations demonstrate that DisCoRD achieves state-of-the-art performance, with FID of 0.032 on HumanML3D and 0.169 on KIT-ML. These results solidify DisCoRD as a robust solution for bridging the divide between discrete efficiency and continuous realism. Our project page is available at: https://whwjdqls.github.io/discord.github.io/.
DEEPTalk: Dynamic Emotion Embedding for Probabilistic Speech-Driven 3D Face Animation
Aug 12, 2024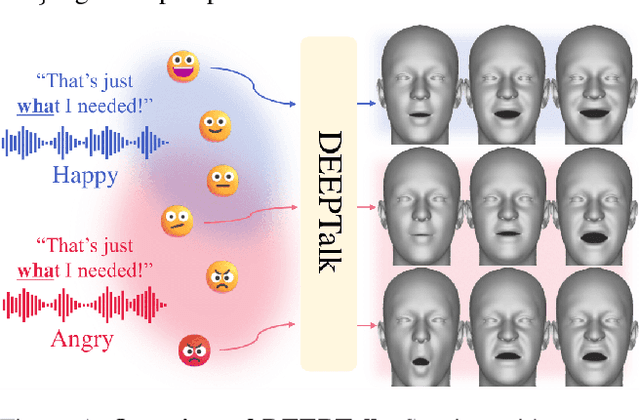

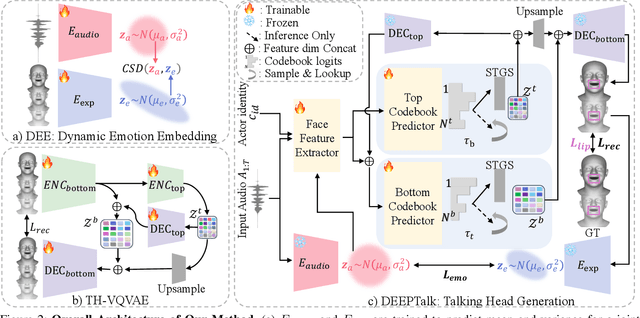
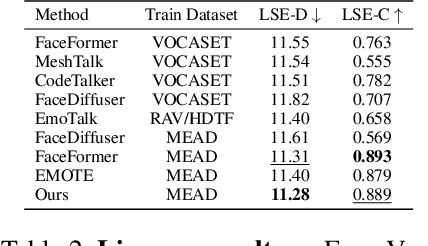
Speech-driven 3D facial animation has garnered lots of attention thanks to its broad range of applications. Despite recent advancements in achieving realistic lip motion, current methods fail to capture the nuanced emotional undertones conveyed through speech and produce monotonous facial motion. These limitations result in blunt and repetitive facial animations, reducing user engagement and hindering their applicability. To address these challenges, we introduce DEEPTalk, a novel approach that generates diverse and emotionally rich 3D facial expressions directly from speech inputs. To achieve this, we first train DEE (Dynamic Emotion Embedding), which employs probabilistic contrastive learning to forge a joint emotion embedding space for both speech and facial motion. This probabilistic framework captures the uncertainty in interpreting emotions from speech and facial motion, enabling the derivation of emotion vectors from its multifaceted space. Moreover, to generate dynamic facial motion, we design TH-VQVAE (Temporally Hierarchical VQ-VAE) as an expressive and robust motion prior overcoming limitations of VAEs and VQ-VAEs. Utilizing these strong priors, we develop DEEPTalk, A talking head generator that non-autoregressively predicts codebook indices to create dynamic facial motion, incorporating a novel emotion consistency loss. Extensive experiments on various datasets demonstrate the effectiveness of our approach in creating diverse, emotionally expressive talking faces that maintain accurate lip-sync. Source code will be made publicly available soon.
ParaHome: Parameterizing Everyday Home Activities Towards 3D Generative Modeling of Human-Object Interactions
Jan 18, 2024To enable machines to learn how humans interact with the physical world in our daily activities, it is crucial to provide rich data that encompasses the 3D motion of humans as well as the motion of objects in a learnable 3D representation. Ideally, this data should be collected in a natural setup, capturing the authentic dynamic 3D signals during human-object interactions. To address this challenge, we introduce the ParaHome system, designed to capture and parameterize dynamic 3D movements of humans and objects within a common home environment. Our system consists of a multi-view setup with 70 synchronized RGB cameras, as well as wearable motion capture devices equipped with an IMU-based body suit and hand motion capture gloves. By leveraging the ParaHome system, we collect a novel large-scale dataset of human-object interaction. Notably, our dataset offers key advancement over existing datasets in three main aspects: (1) capturing 3D body and dexterous hand manipulation motion alongside 3D object movement within a contextual home environment during natural activities; (2) encompassing human interaction with multiple objects in various episodic scenarios with corresponding descriptions in texts; (3) including articulated objects with multiple parts expressed with parameterized articulations. Building upon our dataset, we introduce new research tasks aimed at building a generative model for learning and synthesizing human-object interactions in a real-world room setting.
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.