 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Social Media Annotation of HPV Vaccine Skepticism and Misinformation Using Large Language Models: An Experimental Evaluation of In-Context Learning and Fine-Tuning Stance Detection Across Multiple Models
Nov 22, 2024


This paper leverages large-language models (LLMs) to experimentally determine optimal strategies for scaling up social media content annotation for stance detection on HPV vaccine-related tweets. We examine both conventional fine-tuning and emergent in-context learning methods, systematically varying strategies of prompt engineering across widely used LLMs and their variants (e.g., GPT4, Mistral, and Llama3, etc.). Specifically, we varied prompt template design, shot sampling methods, and shot quantity to detect stance on HPV vaccination. Our findings reveal that 1) in general, in-context learning outperforms fine-tuning in stance detection for HPV vaccine social media content; 2) increasing shot quantity does not necessarily enhance performance across models; and 3) different LLMs and their variants present differing sensitivity to in-context learning conditions. We uncovered that the optimal in-context learning configuration for stance detection on HPV vaccine tweets involves six stratified shots paired with detailed contextual prompts. This study highlights the potential and provides an applicable approach for applying LLMs to research on social media stance and skepticism detection.
Purrfessor: A Fine-tuned Multimodal LLaVA Diet Health Chatbot
Nov 22, 2024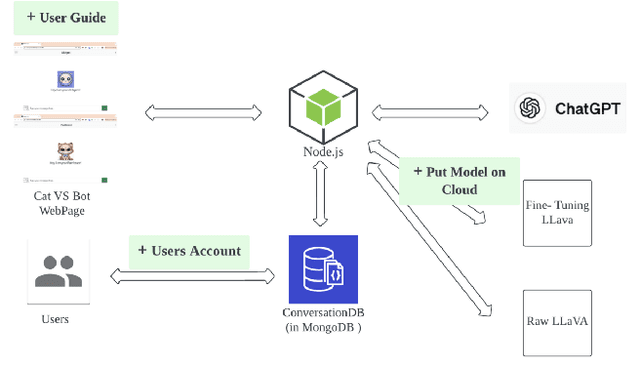
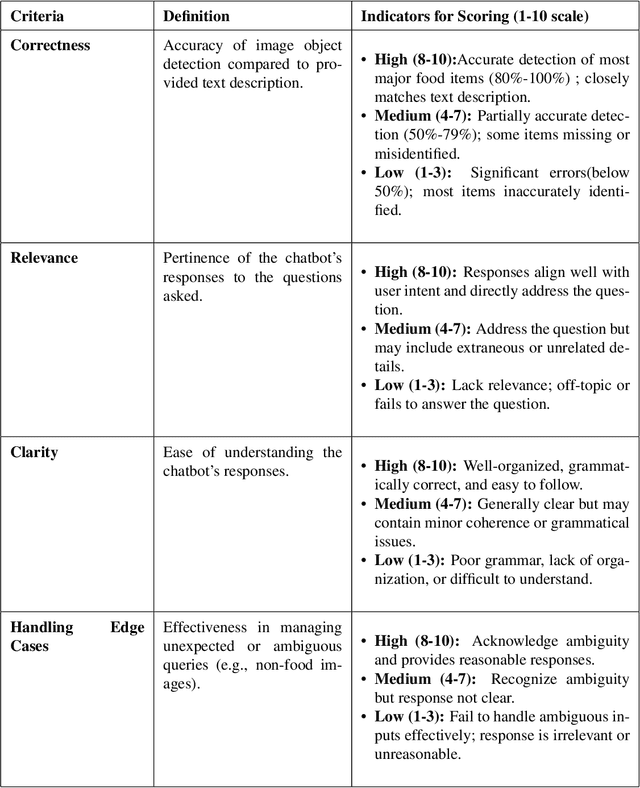
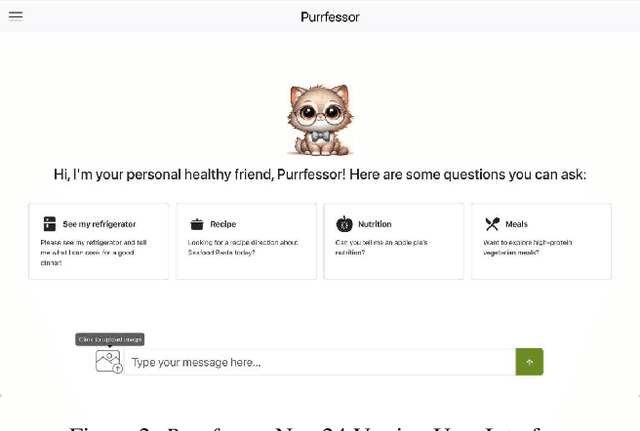
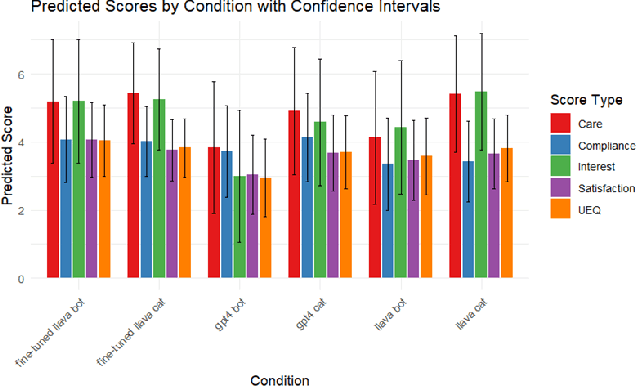
This study introduces Purrfessor, an innovative AI chatbot designed to provide personalized dietary guidance through interactive, multimodal engagement. Leveraging the Large Language-and-Vision Assistant (LLaVA) model fine-tuned with food and nutrition data and a human-in-the-loop approach, Purrfessor integrates visual meal analysis with contextual advice to enhance user experience and engagement. We conducted two studies to evaluate the chatbot's performance and user experience: (a) simulation assessments and human validation were conducted to examine the performance of the fine-tuned model; (b) a 2 (Profile: Bot vs. Pet) by 3 (Model: GPT-4 vs. LLaVA vs. Fine-tuned LLaVA) experiment revealed that Purrfessor significantly enhanced users' perceptions of care ($\beta = 1.59$, $p = 0.04$) and interest ($\beta = 2.26$, $p = 0.01$) compared to the GPT-4 bot. Additionally, user interviews highlighted the importance of interaction design details, emphasizing the need for responsiveness, personalization, and guidance to improve user engagement.
Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks
Jun 25, 2024



Creating human-like large language model (LLM) agents is crucial for faithful social simulation. Having LLMs role-play based on demographic information sometimes improves human likeness but often does not. This study assessed whether LLM alignment with human behavior can be improved by integrating information from empirically-derived human belief networks. Using data from a human survey, we estimated a belief network encompassing 18 topics loading on two non-overlapping latent factors. We then seeded LLM-based agents with an opinion on one topic, and assessed the alignment of its expressed opinions on remaining test topics with corresponding human data. Role-playing based on demographic information alone did not align LLM and human opinions, but seeding the agent with a single belief greatly improved alignment for topics related in the belief network, and not for topics outside the network. These results suggest a novel path for human-LLM belief alignment in work seeking to simulate and understand patterns of belief distributions in society.
Constructing Vec-tionaries to Extract Latent Message Features from Texts: A Case Study of Moral Appeals
Dec 10, 2023While communication research frequently studies latent message features like moral appeals, their quantification remains a challenge. Conventional human coding struggles with scalability and intercoder reliability. While dictionary-based methods are cost-effective and computationally efficient, they often lack contextual sensitivity and are limited by the vocabularies developed for the original applications. In this paper, we present a novel approach to construct vec-tionary measurement tools that boost validated dictionaries with word embeddings through nonlinear optimization. By harnessing semantic relationships encoded by embeddings, vec-tionaries improve the measurement of latent message features by expanding the applicability of original vocabularies to other contexts. Vec-tionaries can also help extract semantic information from texts, especially those in short format, beyond the original vocabulary of a dictionary. Importantly, a vec-tionary can produce additional metrics to capture the valence and ambivalence of a latent feature beyond its strength in texts. Using moral appeals in COVID-19-related tweets as a case study, we illustrate the steps to construct the moral foundations vec-tionary, showcasing its ability to process posts missed by dictionary methods and to produce measurements better aligned with crowdsourced human assessments. Furthermore, additional metrics from the moral foundations vec-tionary unveiled unique insights that facilitated predicting outcomes such as message retransmission.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Nov 16, 2023Accurately simulating human opinion dynamics is crucial for understanding a variety of societal phenomena, including polarization and the spread of misinformation. However, the agent-based models (ABMs) commonly used for such simulations lack fidelity to human behavior. We propose a new approach to simulating opinion dynamics based on populations of Large Language Models (LLMs). Our findings reveal a strong inherent bias in LLM agents towards accurate information, leading to consensus in line with scientific reality. However, this bias limits the simulation of individuals with resistant views on issues like climate change. After inducing confirmation bias through prompt engineering, we observed opinion fragmentation in line with existing agent-based research. These insights highlight the promise and limitations of LLM agents in this domain and suggest a path forward: refining LLMs with real-world discourse to better simulate the evolution of human beliefs.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023



Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Evaluating LLM Agent Group Dynamics against Human Group Dynamics: A Case Study on Wisdom of Partisan Crowds
Nov 16, 2023



This study investigates the potential of Large Language Models (LLMs) to simulate human group dynamics, particularly within politically charged contexts. We replicate the Wisdom of Partisan Crowds phenomenon using LLMs to role-play as Democrat and Republican personas, engaging in a structured interaction akin to human group study. Our approach evaluates how agents' responses evolve through social influence. Our key findings indicate that LLM agents role-playing detailed personas and without Chain-of-Thought (CoT) reasoning closely align with human behaviors, while having CoT reasoning hurts the alignment. However, incorporating explicit biases into agent prompts does not necessarily enhance the wisdom of partisan crowds. Moreover, fine-tuning LLMs with human data shows promise in achieving human-like behavior but poses a risk of overfitting certain behaviors. These findings show the potential and limitations of using LLM agents in modeling human group phenomena.
Natural Language based Context Modeling and Reasoning with LLMs: A Tutorial
Sep 24, 2023Large language models (LLMs) have become phenomenally surging, since 2018--two decades after introducing context-awareness into computing systems. Through taking into account the situations of ubiquitous devices, users and the societies, context-aware computing has enabled a wide spectrum of innovative applications, such as assisted living, location-based social network services and so on. To recognize contexts and make decisions for actions accordingly, various artificial intelligence technologies, such as Ontology and OWL, have been adopted as representations for context modeling and reasoning. Recently, with the rise of LLMs and their improved natural language understanding and reasoning capabilities, it has become feasible to model contexts using natural language and perform context reasoning by interacting with LLMs such as ChatGPT and GPT-4. In this tutorial, we demonstrate the use of texts, prompts, and autonomous agents (AutoAgents) that enable LLMs to perform context modeling and reasoning without requiring fine-tuning of the model. We organize and introduce works in the related field, and name this computing paradigm as the LLM-driven Context-aware Computing (LCaC). In the LCaC paradigm, users' requests, sensors reading data, and the command to actuators are supposed to be represented as texts. Given the text of users' request and sensor data, the AutoAgent models the context by prompting and sends to the LLM for context reasoning. LLM generates a plan of actions and responds to the AutoAgent, which later follows the action plan to foster context-awareness. To prove the concepts, we use two showcases--(1) operating a mobile z-arm in an apartment for assisted living, and (2) planning a trip and scheduling the itinerary in a context-aware and personalized manner.
Smiling Women Pitching Down: Auditing Representational and Presentational Gender Biases in Image Generative AI
May 17, 2023
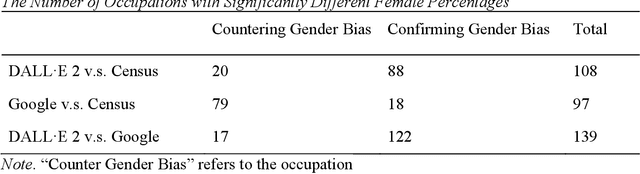
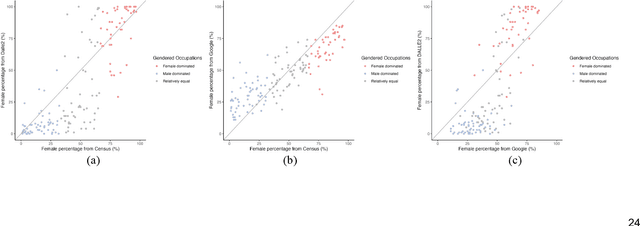
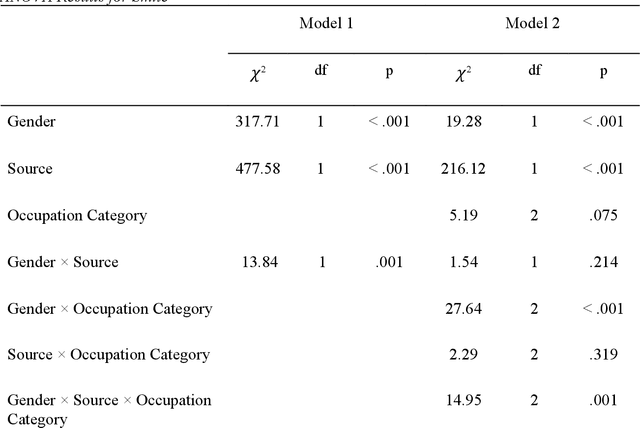
Generative AI models like DALL-E 2 can interpret textual prompts and generate high-quality images exhibiting human creativity. Though public enthusiasm is booming, systematic auditing of potential gender biases in AI-generated images remains scarce. We addressed this gap by examining the prevalence of two occupational gender biases (representational and presentational biases) in 15,300 DALL-E 2 images spanning 153 occupations, and assessed potential bias amplification by benchmarking against 2021 census labor statistics and Google Images. Our findings reveal that DALL-E 2 underrepresents women in male-dominated fields while overrepresenting them in female-dominated occupations. Additionally, DALL-E 2 images tend to depict more women than men with smiling faces and downward-pitching heads, particularly in female-dominated (vs. male-dominated) occupations. Our computational algorithm auditing study demonstrates more pronounced representational and presentational biases in DALL-E 2 compared to Google Images and calls for feminist interventions to prevent such bias-laden AI-generated images to feedback into the media ecology.
From Personalized Medicine to Population Health: A Survey of mHealth Sensing Techniques
Jul 02, 2021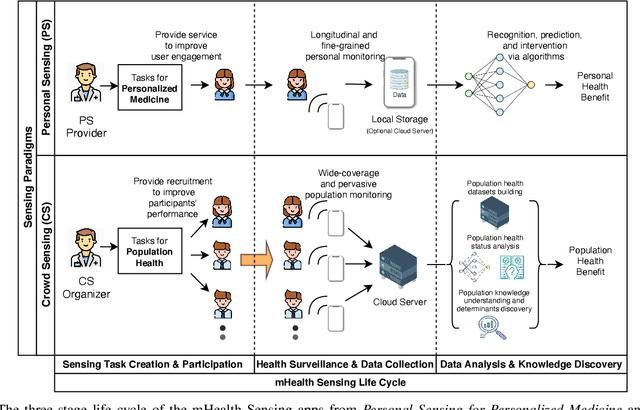
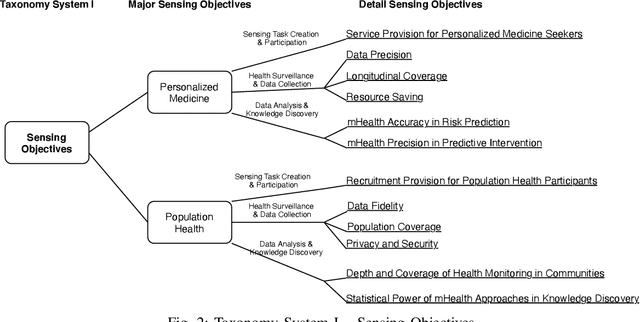
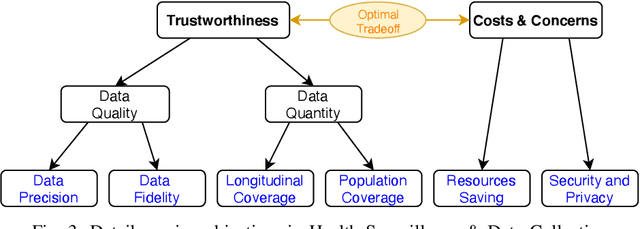
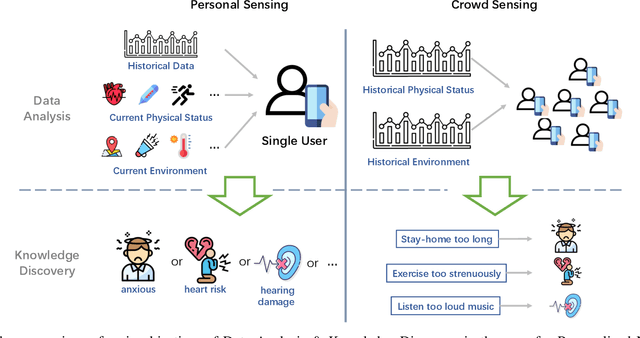
Mobile Sensing Apps have been widely used as a practical approach to collect behavioral and health-related information from individuals and provide timely intervention to promote health and well-beings, such as mental health and chronic cares. As the objectives of mobile sensing could be either \emph{(a) personalized medicine for individuals} or \emph{(b) public health for populations}, in this work we review the design of these mobile sensing apps, and propose to categorize the design of these apps/systems in two paradigms -- \emph{(i) Personal Sensing} and \emph{(ii) Crowd Sensing} paradigms. While both sensing paradigms might incorporate with common ubiquitous sensing technologies, such as wearable sensors, mobility monitoring, mobile data offloading, and/or cloud-based data analytics to collect and process sensing data from individuals, we present a novel taxonomy system with two major components that can specify and classify apps/systems from aspects of the life-cycle of mHealth Sensing: \emph{(1) Sensing Task Creation \& Participation}, \emph{(2) Health Surveillance \& Data Collection}, and \emph{(3) Data Analysis \& Knowledge Discovery}. With respect to different goals of the two paradigms, this work systematically reviews this field, and summarizes the design of typical apps/systems in the view of the configurations and interactions between these two components. In addition to summarization, the proposed taxonomy system also helps figure out the potential directions of mobile sensing for health from both personalized medicines and population health perspectives.