 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Simulacra in the Wild: AI Agent Communities on Moltbook
Mar 17, 2026As autonomous LLM-based agents increasingly populate social platforms, understanding the dynamics of AI-agent communities becomes essential for both communication research and platform governance. We present the first large-scale empirical comparison of AI-agent and human online communities, analyzing 73,899 Moltbook and 189,838 Reddit posts across five matched communities. Structurally, we find that Moltbook exhibits extreme participation inequality (Gini = 0.84 vs. 0.47) and high cross-community author overlap (33.8\% vs. 0.5\%). In terms of linguistic attributes, content generated by AI-agents is emotionally flattened, cognitively shifted toward assertion over exploration, and socially detached. These differences give rise to apparent community-level homogenization, but we show this is primarily a structural artifact of shared authorship. At the author level, individual agents are more identifiable than human users, driven by outlier stylistic profiles amplified by their extreme posting volume. As AI-mediated communication reshapes online discourse, our work offers an empirical foundation for understanding how multi-agent interaction gives rise to collective communication dynamics distinct from those of human communities.
Answer Bubbles: Information Exposure in AI-Mediated Search
Mar 17, 2026Generative search systems are increasingly replacing link-based retrieval with AI-generated summaries, yet little is known about how these systems differ in sources, language, and fidelity to cited material. We examine responses to 11,000 real search queries across four systems -- vanilla GPT, Search GPT, Google AI Overviews, and traditional Google Search -- at three levels: source diversity, linguistic characterization of the generated summary, and source-summary fidelity. We find that generative search systems exhibit significant \textit{source-selection} biases in their citations, favoring certain sources over others. Incorporating search also selectively attenuates epistemic markers, reducing hedging by up to 60\% while preserving confidence language in the AI-generated summaries. At the same time, AI summaries further compound the citation biases: Wikipedia and longer sources are disproportionately overrepresented, whereas cited social media content and negatively framed sources are substantially underrepresented. Our findings highlight the potential for \textit{answer bubbles}, in which identical queries yield structurally different information realities across systems, with implications for user trust, source visibility, and the transparency of AI-mediated information access.
The Hidden Toll of Social Media News: Causal Effects on Psychosocial Wellbeing
Jan 20, 2026News consumption on social media has become ubiquitous, yet how different forms of engagement shape psychosocial outcomes remains unclear. To address this gap, we leveraged a large-scale dataset of ~26M posts and ~45M comments on the BlueSky platform, and conducted a quasi-experimental study, matching 81,345 Treated users exposed to News feeds with 83,711 Control users using stratified propensity score analysis. We examined psychosocial wellbeing, in terms of affective, behavioral, and cognitive outcomes. Our findings reveal that news engagement produces systematic trade-offs: increased depression, stress, and anxiety, yet decreased loneliness and increased social interaction on the platform. Regression models reveal that News feed bookmarking is associated with greater psychosocial deterioration compared to commenting or quoting, with magnitude differences exceeding tenfold. These per-engagement effects accumulate with repeated exposure, showing significant psychosocial impacts. Our work extends theories of news effects beyond crisis-centric frameworks by demonstrating that routine consumption creates distinct psychological dynamics depending on engagement type, and bears implications for tools and interventions for mitigating the psychosocial costs of news consumption on social media.
ArgCMV: An Argument Summarization Benchmark for the LLM-era
Aug 27, 2025
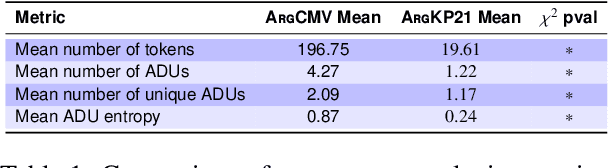


Key point extraction is an important task in argument summarization which involves extracting high-level short summaries from arguments. Existing approaches for KP extraction have been mostly evaluated on the popular ArgKP21 dataset. In this paper, we highlight some of the major limitations of the ArgKP21 dataset and demonstrate the need for new benchmarks that are more representative of actual human conversations. Using SoTA large language models (LLMs), we curate a new argument key point extraction dataset called ArgCMV comprising of around 12K arguments from actual online human debates spread across over 3K topics. Our dataset exhibits higher complexity such as longer, co-referencing arguments, higher presence of subjective discourse units, and a larger range of topics over ArgKP21. We show that existing methods do not adapt well to ArgCMV and provide extensive benchmark results by experimenting with existing baselines and latest open source models. This work introduces a novel KP extraction dataset for long-context online discussions, setting the stage for the next generation of LLM-driven summarization research.
Breaking Bad Tokens: Detoxification of LLMs Using Sparse Autoencoders
May 20, 2025Large language models (LLMs) are now ubiquitous in user-facing applications, yet they still generate undesirable toxic outputs, including profanity, vulgarity, and derogatory remarks. Although numerous detoxification methods exist, most apply broad, surface-level fixes and can therefore easily be circumvented by jailbreak attacks. In this paper we leverage sparse autoencoders (SAEs) to identify toxicity-related directions in the residual stream of models and perform targeted activation steering using the corresponding decoder vectors. We introduce three tiers of steering aggressiveness and evaluate them on GPT-2 Small and Gemma-2-2B, revealing trade-offs between toxicity reduction and language fluency. At stronger steering strengths, these causal interventions surpass competitive baselines in reducing toxicity by up to 20%, though fluency can degrade noticeably on GPT-2 Small depending on the aggressiveness. Crucially, standard NLP benchmark scores upon steering remain stable, indicating that the model's knowledge and general abilities are preserved. We further show that feature-splitting in wider SAEs hampers safety interventions, underscoring the importance of disentangled feature learning. Our findings highlight both the promise and the current limitations of SAE-based causal interventions for LLM detoxification, further suggesting practical guidelines for safer language-model deployment.
MoMoE: Mixture of Moderation Experts Framework for AI-Assisted Online Governance
May 20, 2025Large language models (LLMs) have shown great potential in flagging harmful content in online communities. Yet, existing approaches for moderation require a separate model for every community and are opaque in their decision-making, limiting real-world adoption. We introduce Mixture of Moderation Experts (MoMoE), a modular, cross-community framework that adds post-hoc explanations to scalable content moderation. MoMoE orchestrates four operators -- Allocate, Predict, Aggregate, Explain -- and is instantiated as seven community-specialized experts (MoMoE-Community) and five norm-violation experts (MoMoE-NormVio). On 30 unseen subreddits, the best variants obtain Micro-F1 scores of 0.72 and 0.67, respectively, matching or surpassing strong fine-tuned baselines while consistently producing concise and reliable explanations. Although community-specialized experts deliver the highest peak accuracy, norm-violation experts provide steadier performance across domains. These findings show that MoMoE yields scalable, transparent moderation without needing per-community fine-tuning. More broadly, they suggest that lightweight, explainable expert ensembles can guide future NLP and HCI research on trustworthy human-AI governance of online communities.
SLM-Mod: Small Language Models Surpass LLMs at Content Moderation
Oct 17, 2024



Large language models (LLMs) have shown promise in many natural language understanding tasks, including content moderation. However, these models can be expensive to query in real-time and do not allow for a community-specific approach to content moderation. To address these challenges, we explore the use of open-source small language models (SLMs) for community-specific content moderation tasks. We fine-tune and evaluate SLMs (less than 15B parameters) by comparing their performance against much larger open- and closed-sourced models. Using 150K comments from 15 popular Reddit communities, we find that SLMs outperform LLMs at content moderation -- 11.5% higher accuracy and 25.7% higher recall on average across all communities. We further show the promise of cross-community content moderation, which has implications for new communities and the development of cross-platform moderation techniques. Finally, we outline directions for future work on language model based content moderation. Code and links to HuggingFace models can be found at https://github.com/AGoyal0512/SLM-Mod.
Beyond Demographics: Aligning Role-playing LLM-based Agents Using Human Belief Networks
Jun 25, 2024



Creating human-like large language model (LLM) agents is crucial for faithful social simulation. Having LLMs role-play based on demographic information sometimes improves human likeness but often does not. This study assessed whether LLM alignment with human behavior can be improved by integrating information from empirically-derived human belief networks. Using data from a human survey, we estimated a belief network encompassing 18 topics loading on two non-overlapping latent factors. We then seeded LLM-based agents with an opinion on one topic, and assessed the alignment of its expressed opinions on remaining test topics with corresponding human data. Role-playing based on demographic information alone did not align LLM and human opinions, but seeding the agent with a single belief greatly improved alignment for topics related in the belief network, and not for topics outside the network. These results suggest a novel path for human-LLM belief alignment in work seeking to simulate and understand patterns of belief distributions in society.
A latent linear model for nonlinear coupled oscillators on graphs
Nov 25, 2023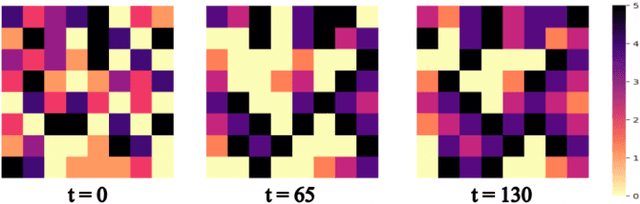
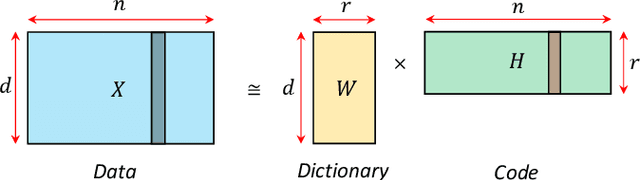
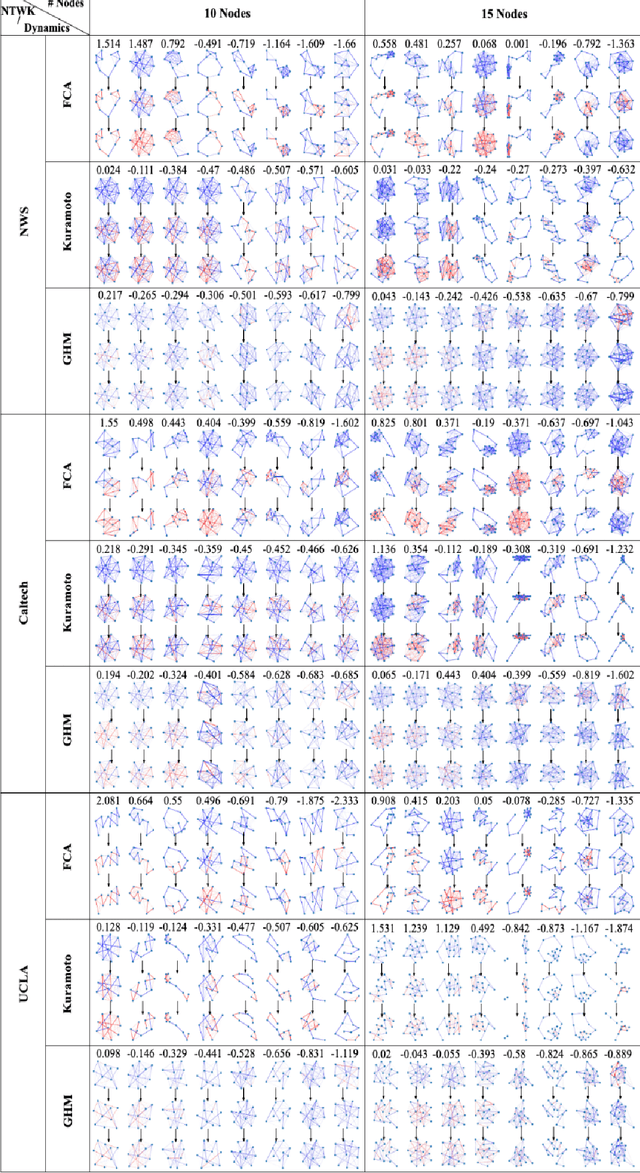
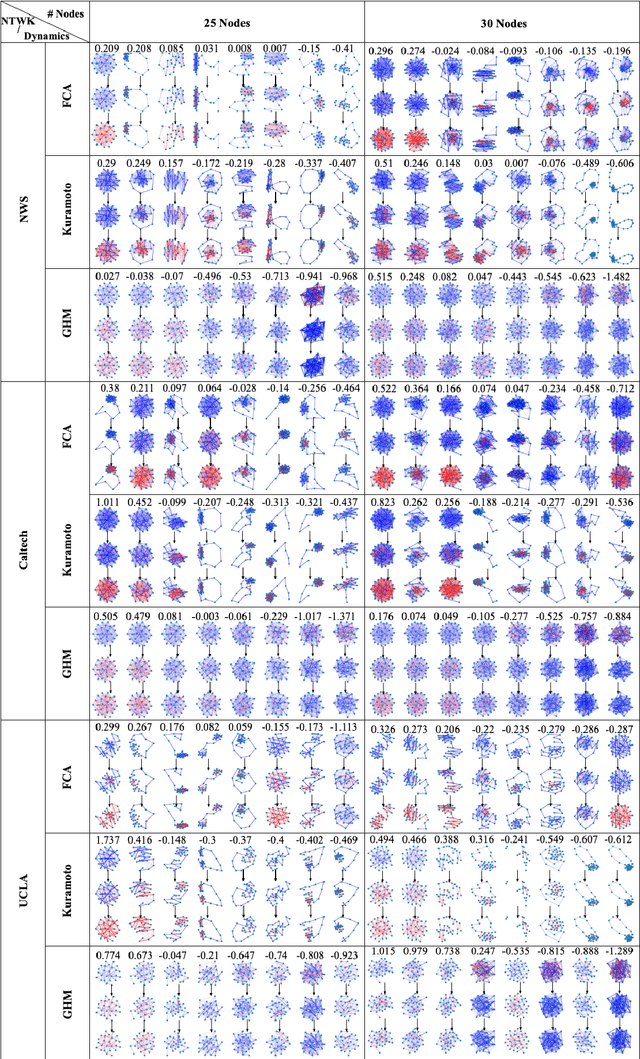
A system of coupled oscillators on an arbitrary graph is locally driven by the tendency to mutual synchronization between nearby oscillators, but can and often exhibit nonlinear behavior on the whole graph. Understanding such nonlinear behavior has been a key challenge in predicting whether all oscillators in such a system will eventually synchronize. In this paper, we demonstrate that, surprisingly, such nonlinear behavior of coupled oscillators can be effectively linearized in certain latent dynamic spaces. The key insight is that there is a small number of `latent dynamics filters', each with a specific association with synchronizing and non-synchronizing dynamics on subgraphs so that any observed dynamics on subgraphs can be approximated by a suitable linear combination of such elementary dynamic patterns. Taking an ensemble of subgraph-level predictions provides an interpretable predictor for whether the system on the whole graph reaches global synchronization. We propose algorithms based on supervised matrix factorization to learn such latent dynamics filters. We demonstrate that our method performs competitively in synchronization prediction tasks against baselines and black-box classification algorithms, despite its simple and interpretable architecture.
Simulating Opinion Dynamics with Networks of LLM-based Agents
Nov 16, 2023Accurately simulating human opinion dynamics is crucial for understanding a variety of societal phenomena, including polarization and the spread of misinformation. However, the agent-based models (ABMs) commonly used for such simulations lack fidelity to human behavior. We propose a new approach to simulating opinion dynamics based on populations of Large Language Models (LLMs). Our findings reveal a strong inherent bias in LLM agents towards accurate information, leading to consensus in line with scientific reality. However, this bias limits the simulation of individuals with resistant views on issues like climate change. After inducing confirmation bias through prompt engineering, we observed opinion fragmentation in line with existing agent-based research. These insights highlight the promise and limitations of LLM agents in this domain and suggest a path forward: refining LLMs with real-world discourse to better simulate the evolution of human beliefs.