 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration
Oct 06, 2025
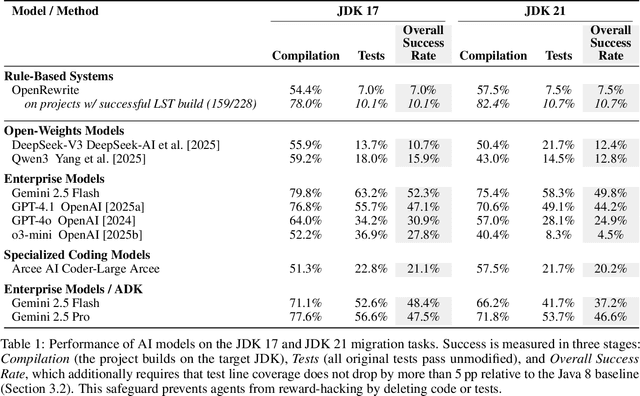


AI coding assistants are rapidly becoming integral to modern software development. A key challenge in this space is the continual need to migrate and modernize codebases in response to evolving software ecosystems. Traditionally, such migrations have relied on rule-based systems and human intervention. With the advent of powerful large language models (LLMs), AI-driven agentic frameworks offer a promising alternative-but their effectiveness has not been systematically evaluated. In this paper, we introduce FreshBrew, a novel benchmark for evaluating AI agents on project-level Java migrations, with a specific focus on measuring an agent's ability to preserve program semantics and avoid reward hacking, which we argue requires projects with high test coverage for a rigorous and reliable evaluation. We benchmark several state-of-the-art LLMs, and compare their performance against established rule-based tools. Our evaluation of AI agents on this benchmark of 228 repositories shows that the top-performing model, Gemini 2.5 Flash, can successfully migrate 52.3 percent of projects to JDK 17. Our empirical analysis reveals novel insights into the critical strengths and limitations of current agentic approaches, offering actionable insights into their real-world applicability. Our empirical study reveals failure modes of current AI agents in realistic Java modernization tasks, providing a foundation for evaluating trustworthy code-migration systems. By releasing FreshBrew, we aim to facilitate rigorous, reproducible evaluation and catalyze progress in AI-driven codebase modernization.
GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Jul 16, 2025
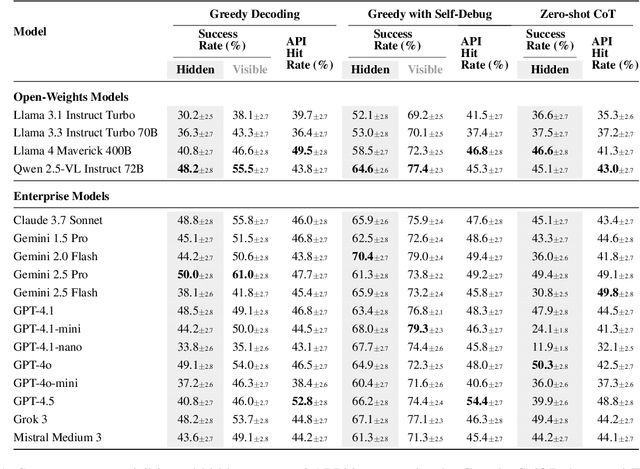
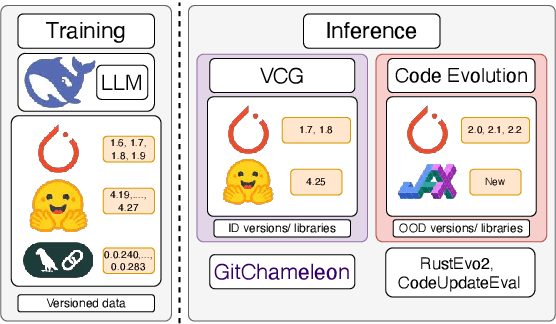
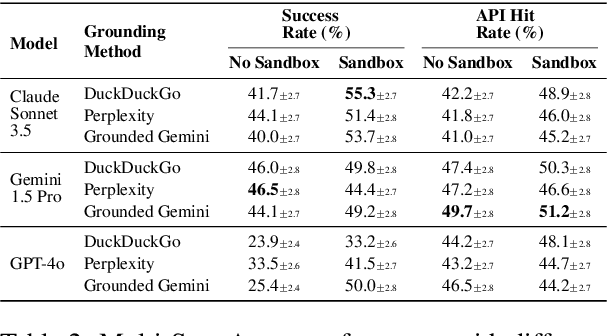
The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to perform version-conditioned code generation that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51\% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We make the dataset and evaluation code publicly available at https://github.com/mrcabbage972/GitChameleonBenchmark.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


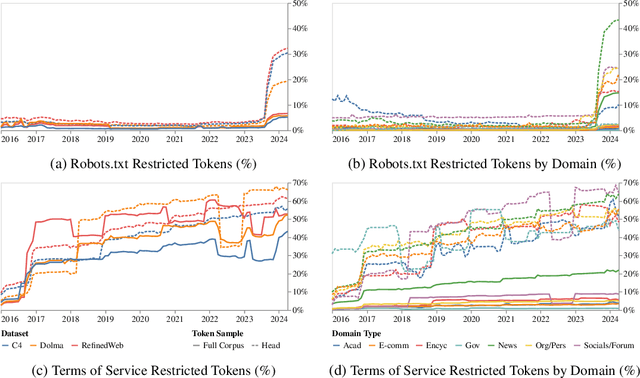
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Slight Corruption in Pre-training Data Makes Better Diffusion Models
May 30, 2024



Diffusion models (DMs) have shown remarkable capabilities in generating realistic high-quality images, audios, and videos. They benefit significantly from extensive pre-training on large-scale datasets, including web-crawled data with paired data and conditions, such as image-text and image-class pairs. Despite rigorous filtering, these pre-training datasets often inevitably contain corrupted pairs where conditions do not accurately describe the data. This paper presents the first comprehensive study on the impact of such corruption in pre-training data of DMs. We synthetically corrupt ImageNet-1K and CC3M to pre-train and evaluate over 50 conditional DMs. Our empirical findings reveal that various types of slight corruption in pre-training can significantly enhance the quality, diversity, and fidelity of the generated images across different DMs, both during pre-training and downstream adaptation stages. Theoretically, we consider a Gaussian mixture model and prove that slight corruption in the condition leads to higher entropy and a reduced 2-Wasserstein distance to the ground truth of the data distribution generated by the corruptly trained DMs. Inspired by our analysis, we propose a simple method to improve the training of DMs on practical datasets by adding condition embedding perturbations (CEP). CEP significantly improves the performance of various DMs in both pre-training and downstream tasks. We hope that our study provides new insights into understanding the data and pre-training processes of DMs.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024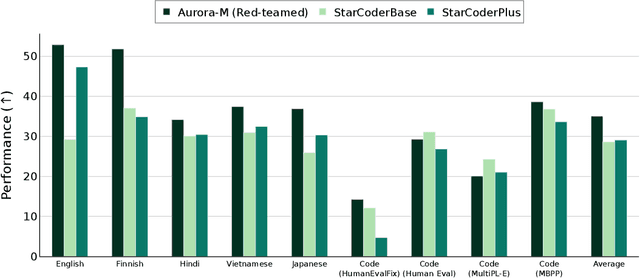

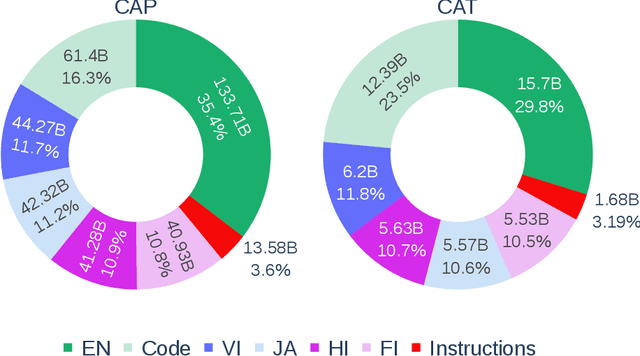
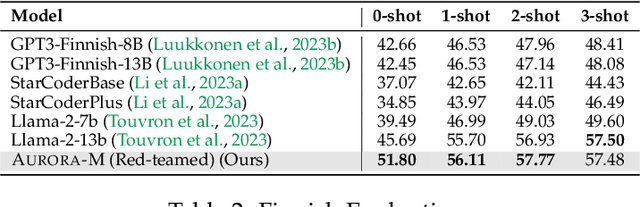
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data
Mar 19, 2024Measuring nonlinear feature interaction is an established approach to understanding complex patterns of attribution in many models. In this paper, we use Shapley Taylor interaction indices (STII) to analyze the impact of underlying data structure on model representations in a variety of modalities, tasks, and architectures. Considering linguistic structure in masked and auto-regressive language models (MLMs and ALMs), we find that STII increases within idiomatic expressions and that MLMs scale STII with syntactic distance, relying more on syntax in their nonlinear structure than ALMs do. Our speech model findings reflect the phonetic principal that the openness of the oral cavity determines how much a phoneme varies based on its context. Finally, we study image classifiers and illustrate that feature interactions intuitively reflect object boundaries. Our wide range of results illustrates the benefits of interdisciplinary work and domain expertise in interpretability research.
Just Say the Name: Online Continual Learning with Category Names Only via Data Generation
Mar 16, 2024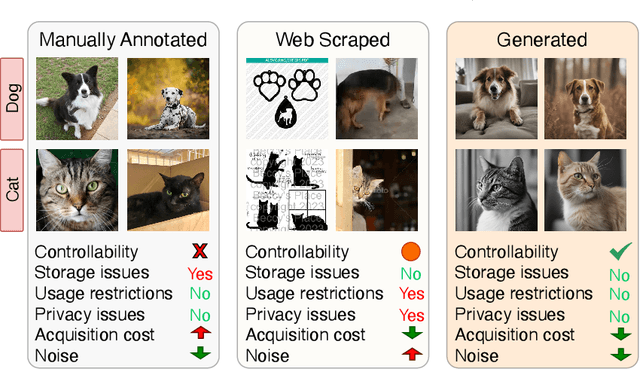



In real-world scenarios, extensive manual annotation for continual learning is impractical due to prohibitive costs. Although prior arts, influenced by large-scale webly supervised training, suggest leveraging web-scraped data in continual learning, this poses challenges such as data imbalance, usage restrictions, and privacy concerns. Addressing the risks of continual webly supervised training, we present an online continual learning framework - Generative Name only Continual Learning (G-NoCL). The proposed G-NoCL uses a set of generators G along with the learner. When encountering new concepts (i.e., classes), G-NoCL employs the novel sample complexity-guided data ensembling technique DIverSity and COmplexity enhancing ensemBlER (DISCOBER) to optimally sample training data from generated data. Through extensive experimentation, we demonstrate superior performance of DISCOBER in G-NoCL online CL benchmarks, covering both In-Distribution (ID) and Out-of-Distribution (OOD) generalization evaluations, compared to naive generator-ensembling, web-supervised, and manually annotated data.
On the low-shot transferability of -Mamba
Mar 15, 2024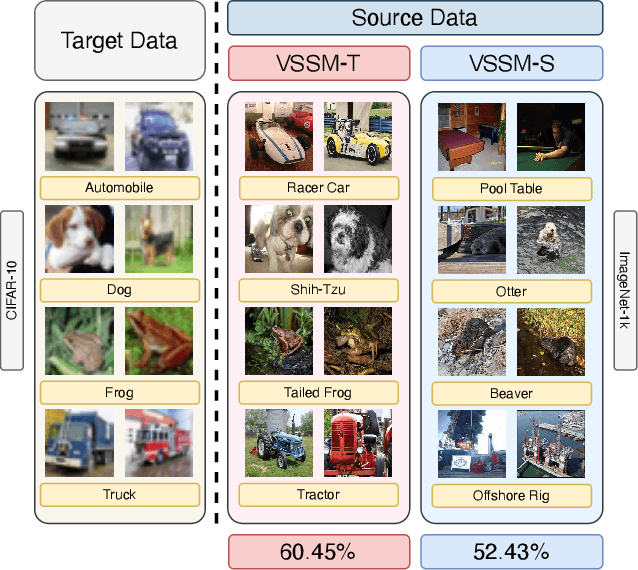
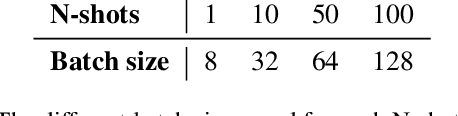
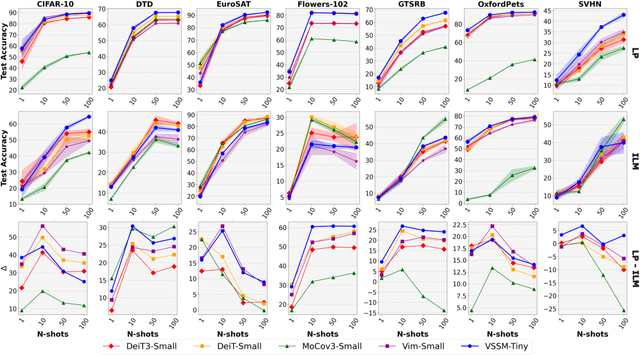
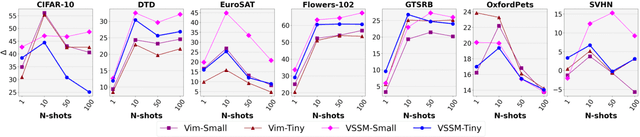
The strength of modern large-scale neural networks lies in their ability to efficiently adapt to new tasks with few examples. Although extensive research has investigated the transferability of Vision Transformers (ViTs) to various downstream tasks under diverse constraints, this study shifts focus to explore the transfer learning potential of [V]-Mamba. We compare its performance with ViTs across different few-shot data budgets and efficient transfer methods. Our analysis yields three key insights into [V]-Mamba's few-shot transfer performance: (a) [V]-Mamba demonstrates superior or equivalent few-shot learning capabilities compared to ViTs when utilizing linear probing (LP) for transfer, (b) Conversely, [V]-Mamba exhibits weaker or similar few-shot learning performance compared to ViTs when employing visual prompting (VP) as the transfer method, and (c) We observe a weak positive correlation between the performance gap in transfer via LP and VP and the scale of the [V]-Mamba model. This preliminary analysis lays the foundation for more comprehensive studies aimed at furthering our understanding of the capabilities of [V]-Mamba variants and their distinctions from ViTs.