 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the low-shot transferability of -Mamba
Paper and Code
Mar 15, 2024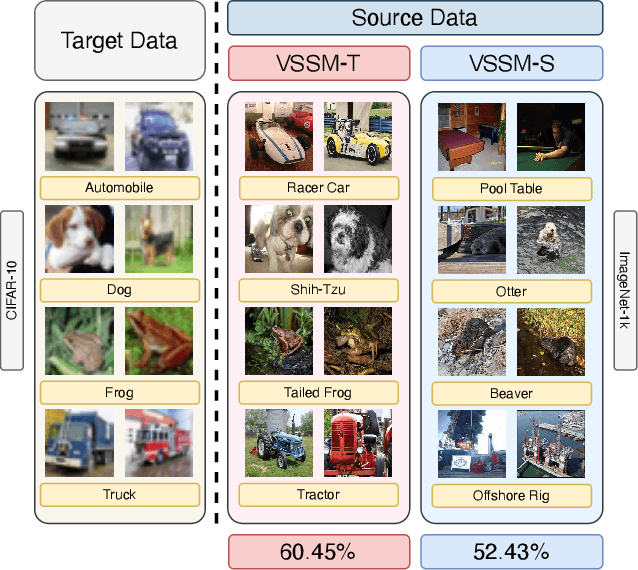
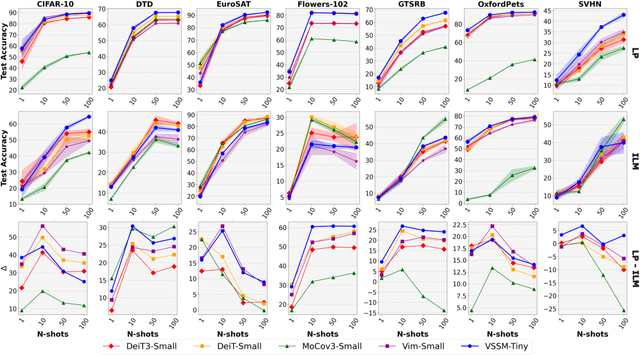
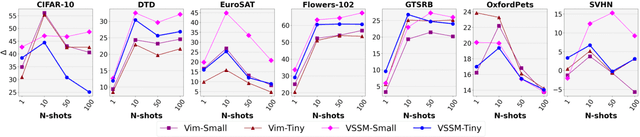
The strength of modern large-scale neural networks lies in their ability to efficiently adapt to new tasks with few examples. Although extensive research has investigated the transferability of Vision Transformers (ViTs) to various downstream tasks under diverse constraints, this study shifts focus to explore the transfer learning potential of [V]-Mamba. We compare its performance with ViTs across different few-shot data budgets and efficient transfer methods. Our analysis yields three key insights into [V]-Mamba's few-shot transfer performance: (a) [V]-Mamba demonstrates superior or equivalent few-shot learning capabilities compared to ViTs when utilizing linear probing (LP) for transfer, (b) Conversely, [V]-Mamba exhibits weaker or similar few-shot learning performance compared to ViTs when employing visual prompting (VP) as the transfer method, and (c) We observe a weak positive correlation between the performance gap in transfer via LP and VP and the scale of the [V]-Mamba model. This preliminary analysis lays the foundation for more comprehensive studies aimed at furthering our understanding of the capabilities of [V]-Mamba variants and their distinctions from ViTs.