 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSQ: Learning from Important Tokens Leads to Better Quantized LLMs
Mar 03, 2025Layer-wise quantization is a key technique for efficiently compressing large models without expensive retraining. Previous methods typically quantize the weights of each layer by "uniformly" optimizing the layer reconstruction loss across all output tokens. However, in this paper, we demonstrate that better-quantized models can be obtained by prioritizing learning from important tokens (e.g. which have large attention scores). Building on this finding, we propose RSQ (Rotate, Scale, then Quantize), which (1) applies rotations (orthogonal transformation) to the model to mitigate outliers (those with exceptionally large magnitude), (2) scales the token feature based on its importance, and (3) quantizes the model using the GPTQ framework with the second-order statistics computed by scaled tokens. To compute token importance, we explore both heuristic and dynamic strategies. Based on a thorough analysis of all approaches, we adopt attention concentration, which uses attention scores of each token as its importance, as the best approach. We demonstrate that RSQ consistently outperforms baseline methods across multiple downstream tasks and three model families: LLaMA3, Mistral, and Qwen2.5. Additionally, models quantized with RSQ achieve superior performance on long-context tasks, further highlighting its effectiveness. Lastly, RSQ demonstrates generalizability across various setups, including different model sizes, calibration datasets, bit precisions, and quantization methods.
Glider: Global and Local Instruction-Driven Expert Router
Oct 09, 2024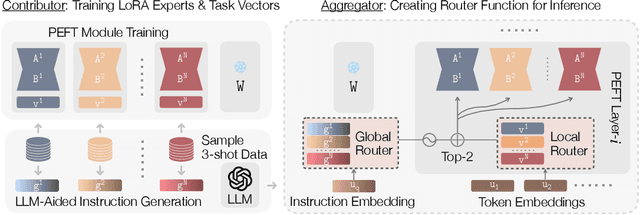
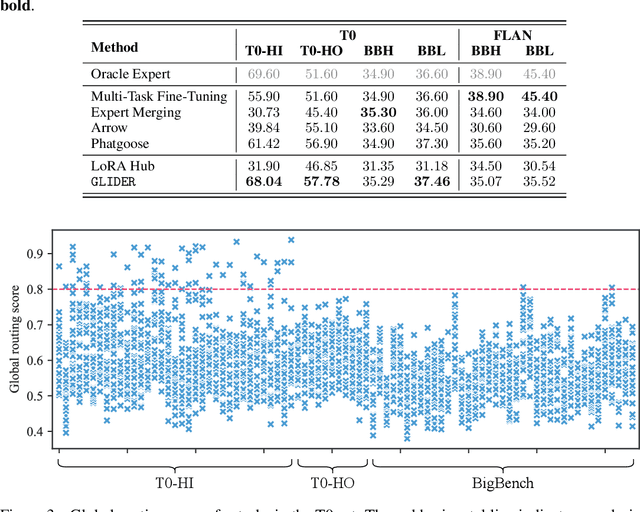
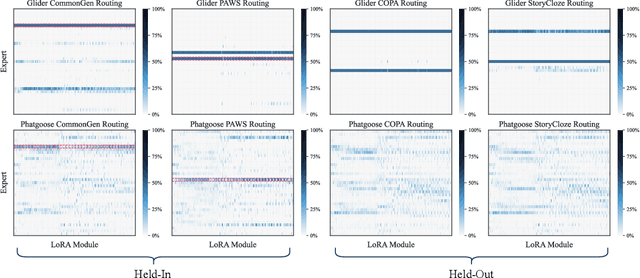
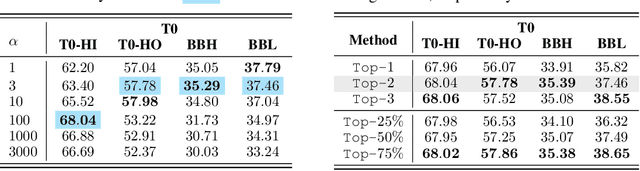
The availability of performant pre-trained models has led to a proliferation of fine-tuned expert models that are specialized to particular domains. This has enabled the creation of powerful and adaptive routing-based "Model MoErging" methods with the goal of using expert modules to create an aggregate system with improved performance or generalization. However, existing MoErging methods often prioritize generalization to unseen tasks at the expense of performance on held-in tasks, which limits its practical applicability in real-world deployment scenarios. We observe that current token-level routing mechanisms neglect the global semantic context of the input task. This token-wise independence hinders effective expert selection for held-in tasks, as routing decisions fail to incorporate the semantic properties of the task. To address this, we propose, Global and Local Instruction Driven Expert Router (GLIDER) that integrates a multi-scale routing mechanism, encompassing a semantic global router and a learned local router. The global router leverages LLM's advanced reasoning capabilities for semantic-related contexts to enhance expert selection. Given the input query and LLM, the router generates semantic task instructions that guide the retrieval of the most relevant experts across all layers. This global guidance is complemented by a local router that facilitates token-level routing decisions within each module, enabling finer control and enhanced performance on unseen tasks. Our experiments using T5-based models for T0 and FLAN tasks demonstrate that GLIDER achieves substantially improved held-in performance while maintaining strong generalization on held-out tasks. We also perform ablations experiments to dive deeper into the components of GLIDER. Our experiments highlight the importance of our multi-scale routing that leverages LLM-driven semantic reasoning for MoErging methods.
What Matters for Model Merging at Scale?
Oct 04, 2024



Model merging aims to combine multiple expert models into a more capable single model, offering benefits such as reduced storage and serving costs, improved generalization, and support for decentralized model development. Despite its promise, previous studies have primarily focused on merging a few small models. This leaves many unanswered questions about the effect of scaling model size and how it interplays with other key factors -- like the base model quality and number of expert models -- , to affect the merged model's performance. This work systematically evaluates the utility of model merging at scale, examining the impact of these different factors. We experiment with merging fully fine-tuned models using 4 popular merging methods -- Averaging, Task~Arithmetic, Dare, and TIES -- across model sizes ranging from 1B-64B parameters and merging up to 8 different expert models. We evaluate the merged models on both held-in tasks, i.e., the expert's training tasks, and zero-shot generalization to unseen held-out tasks. Our experiments provide several new insights about model merging at scale and the interplay between different factors. First, we find that merging is more effective when experts are created from strong base models, i.e., models with good zero-shot performance. Second, larger models facilitate easier merging. Third merging consistently improves generalization capabilities. Notably, when merging 8 large expert models, the merged models often generalize better compared to the multitask trained models. Fourth, we can better merge more expert models when working with larger models. Fifth, different merging methods behave very similarly at larger scales. Overall, our findings shed light on some interesting properties of model merging while also highlighting some limitations. We hope that this study will serve as a reference point on large-scale merging for upcoming research.
A Survey on Model MoErging: Recycling and Routing Among Specialized Experts for Collaborative Learning
Aug 13, 2024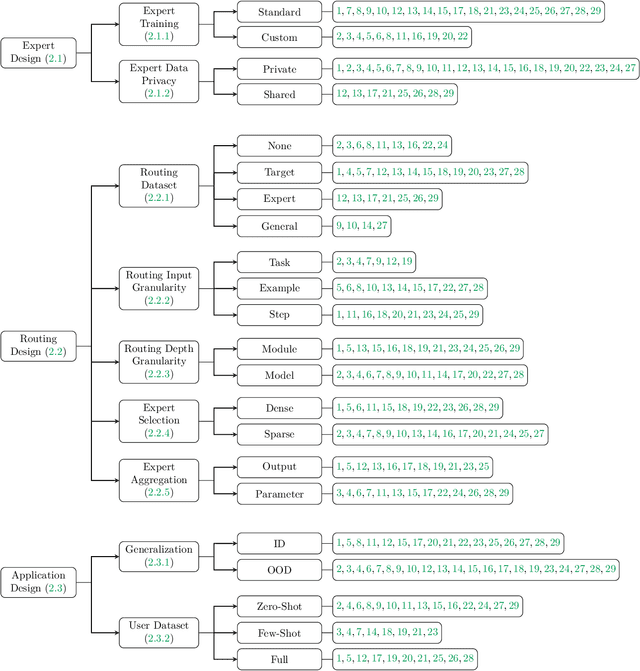
The availability of performant pre-trained models has led to a proliferation of fine-tuned expert models that are specialized to a particular domain or task. Model MoErging methods aim to recycle expert models to create an aggregate system with improved performance or generalization. A key component of MoErging methods is the creation of a router that decides which expert model(s) to use for a particular input or application. The promise, effectiveness, and large design space of MoErging has spurred the development of many new methods over the past few years. This rapid pace of development has made it challenging to compare different MoErging methods, which are rarely compared to one another and are often validated in different experimental setups. To remedy such gaps, we present a comprehensive survey of MoErging methods that includes a novel taxonomy for cataloging key design choices and clarifying suitable applications for each method. Apart from surveying MoErging research, we inventory software tools and applications that make use of MoErging. We additionally discuss related fields of study such as model merging, multitask learning, and mixture-of-experts models. Taken as a whole, our survey provides a unified overview of existing MoErging methods and creates a solid foundation for future work in this burgeoning field.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024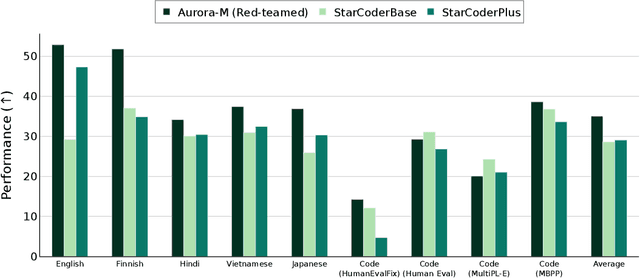

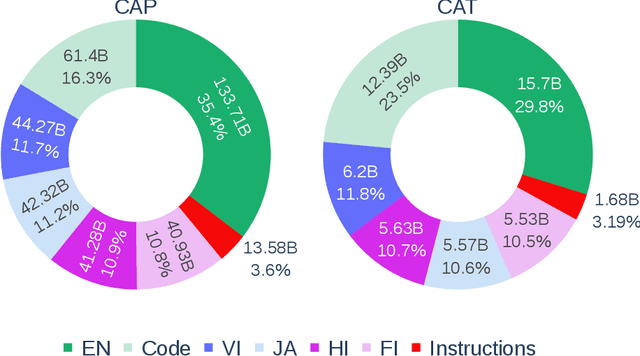
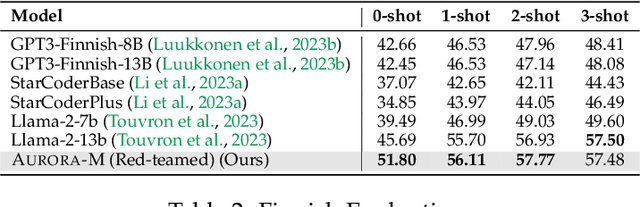
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
ComPEFT: Compression for Communicating Parameter Efficient Updates via Sparsification and Quantization
Nov 22, 2023Parameter-efficient fine-tuning (PEFT) techniques make it possible to efficiently adapt a language model to create "expert" models that specialize to new tasks or domains. Recent techniques in model merging and compositional generalization leverage these expert models by dynamically composing modules to improve zero/few-shot generalization. Despite the efficiency of PEFT methods, the size of expert models can make it onerous to retrieve expert models per query over high-latency networks like the Internet or serve multiple experts on a single GPU. To address these issues, we present ComPEFT, a novel method for compressing fine-tuning residuals (task vectors) of PEFT based models. ComPEFT employs sparsification and ternary quantization to reduce the size of the PEFT module without performing any additional retraining while preserving or enhancing model performance. In extensive evaluation across T5, T0, and LLaMA-based models with 200M - 65B parameters, ComPEFT achieves compression ratios of 8x - 50x. In particular, we show that ComPEFT improves with scale - stronger models exhibit higher compressibility and better performance. For example, we show that ComPEFT applied to LLaMA outperforms QLoRA by 4.16% on MMLU with a storage size reduction of up to 26x. In addition, we show that the compressed experts produced by ComPEFT maintain few-shot compositional generalization capabilities, facilitate efficient communication and computation, and exhibit enhanced performance when merged. Lastly, we provide an analysis of different method components, compare it with other PEFT methods, and test ComPEFT's efficacy for compressing the residual of full-finetuning. Our code is available at https://github.com/prateeky2806/compeft.
D2 Pruning: Message Passing for Balancing Diversity and Difficulty in Data Pruning
Oct 11, 2023Analytical theories suggest that higher-quality data can lead to lower test errors in models trained on a fixed data budget. Moreover, a model can be trained on a lower compute budget without compromising performance if a dataset can be stripped of its redundancies. Coreset selection (or data pruning) seeks to select a subset of the training data so as to maximize the performance of models trained on this subset, also referred to as coreset. There are two dominant approaches: (1) geometry-based data selection for maximizing data diversity in the coreset, and (2) functions that assign difficulty scores to samples based on training dynamics. Optimizing for data diversity leads to a coreset that is biased towards easier samples, whereas, selection by difficulty ranking omits easy samples that are necessary for the training of deep learning models. This demonstrates that data diversity and importance scores are two complementary factors that need to be jointly considered during coreset selection. We represent a dataset as an undirected graph and propose a novel pruning algorithm, D2 Pruning, that uses forward and reverse message passing over this dataset graph for coreset selection. D2 Pruning updates the difficulty scores of each example by incorporating the difficulty of its neighboring examples in the dataset graph. Then, these updated difficulty scores direct a graph-based sampling method to select a coreset that encapsulates both diverse and difficult regions of the dataset space. We evaluate supervised and self-supervised versions of our method on various vision and language datasets. Results show that D2 Pruning improves coreset selection over previous state-of-the-art methods for up to 70% pruning rates. Additionally, we find that using D2 Pruning for filtering large multimodal datasets leads to increased diversity in the dataset and improved generalization of pretrained models.
Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy
Oct 02, 2023



Sparsely activated Mixture-of-Experts (SMoE) has shown promise to scale up the learning capacity of neural networks, however, they have issues like (a) High Memory Usage, due to duplication of the network layers into multiple copies as experts; and (b) Redundancy in Experts, as common learning-based routing policies suffer from representational collapse. Therefore, vanilla SMoE models are memory inefficient and non-scalable, especially for resource-constrained downstream scenarios. In this paper, we ask: Can we craft a compact SMoE model by consolidating expert information? What is the best recipe to merge multiple experts into fewer but more knowledgeable experts? Our pilot investigation reveals that conventional model merging methods fail to be effective in such expert merging for SMoE. The potential reasons are: (1) redundant information overshadows critical experts; (2) appropriate neuron permutation for each expert is missing to bring all of them in alignment. To address this, we propose M-SMoE, which leverages routing statistics to guide expert merging. Specifically, it starts with neuron permutation alignment for experts; then, dominant experts and their "group members" are formed; lastly, every expert group is merged into a single expert by utilizing each expert's activation frequency as their weight for merging, thus diminishing the impact of insignificant experts. Moreover, we observed that our proposed merging promotes a low dimensionality in the merged expert's weight space, naturally paving the way for additional compression. Hence, our final method, MC-SMoE (i.e., Merge, then Compress SMoE), further decomposes the merged experts into low-rank and structural sparse alternatives. Extensive experiments across 8 benchmarks validate the effectiveness of MC-SMoE. For instance, our MC-SMoE achieves up to 80% memory and a 20% FLOPs reduction, with virtually no loss in performance.
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf