 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Model MoErging: Recycling and Routing Among Specialized Experts for Collaborative Learning
Aug 13, 2024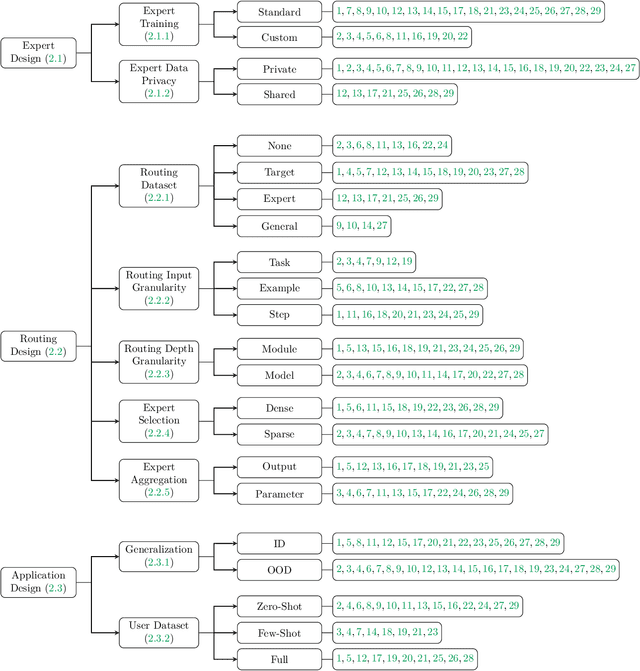
The availability of performant pre-trained models has led to a proliferation of fine-tuned expert models that are specialized to a particular domain or task. Model MoErging methods aim to recycle expert models to create an aggregate system with improved performance or generalization. A key component of MoErging methods is the creation of a router that decides which expert model(s) to use for a particular input or application. The promise, effectiveness, and large design space of MoErging has spurred the development of many new methods over the past few years. This rapid pace of development has made it challenging to compare different MoErging methods, which are rarely compared to one another and are often validated in different experimental setups. To remedy such gaps, we present a comprehensive survey of MoErging methods that includes a novel taxonomy for cataloging key design choices and clarifying suitable applications for each method. Apart from surveying MoErging research, we inventory software tools and applications that make use of MoErging. We additionally discuss related fields of study such as model merging, multitask learning, and mixture-of-experts models. Taken as a whole, our survey provides a unified overview of existing MoErging methods and creates a solid foundation for future work in this burgeoning field.
Learning to Route Among Specialized Experts for Zero-Shot Generalization
Feb 08, 2024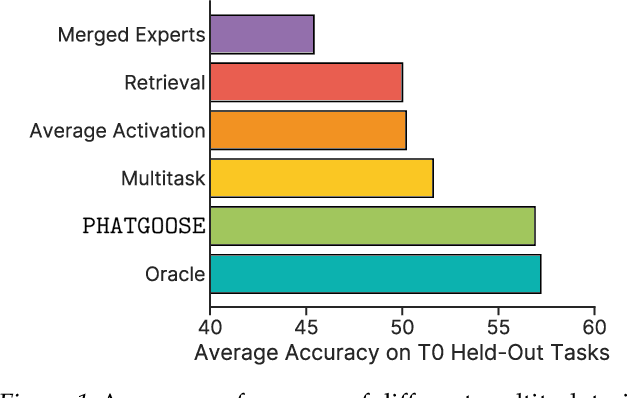

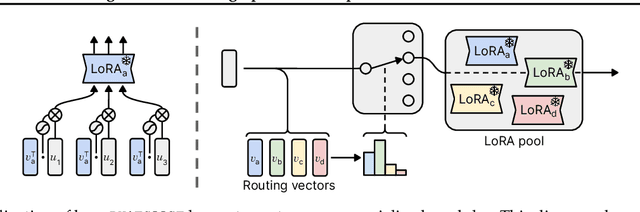

Recently, there has been a widespread proliferation of "expert" language models that are specialized to a specific task or domain through parameter-efficient fine-tuning. How can we recycle large collections of expert language models to improve zero-shot generalization to unseen tasks? In this work, we propose Post-Hoc Adaptive Tokenwise Gating Over an Ocean of Specialized Experts (PHATGOOSE), which learns to route among specialized modules that were produced through parameter-efficient fine-tuning. Unlike past methods that learn to route among specialized models, PHATGOOSE explores the possibility that zero-shot generalization will be improved if different experts can be adaptively chosen for each token and at each layer in the model. Crucially, our method is post-hoc - it does not require simultaneous access to the datasets used to create the specialized models and only requires a modest amount of additional compute after each expert model is trained. In experiments covering a range of specialized model collections and zero-shot generalization benchmarks, we find that PHATGOOSE outperforms past methods for post-hoc routing and, in some cases, outperforms explicit multitask training (which requires simultaneous data access). To better understand the routing strategy learned by PHATGOOSE, we perform qualitative experiments to validate that PHATGOOSE's performance stems from its ability to make adaptive per-token and per-module expert choices. We release all of our code to support future work on improving zero-shot generalization by recycling specialized experts.
Git-Theta: A Git Extension for Collaborative Development of Machine Learning Models
Jun 07, 2023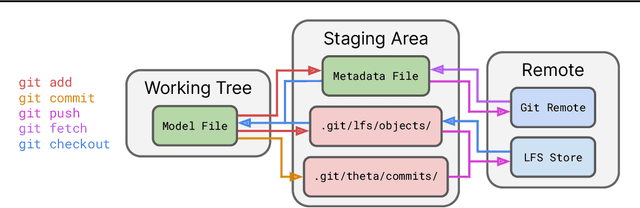
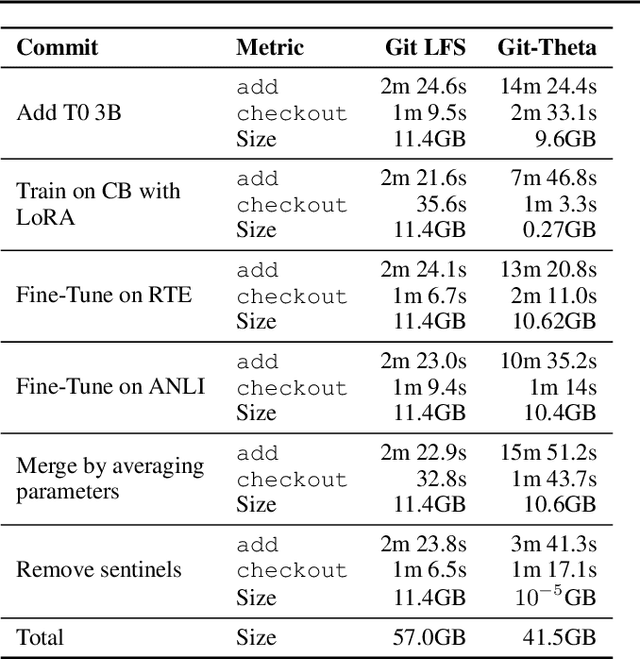
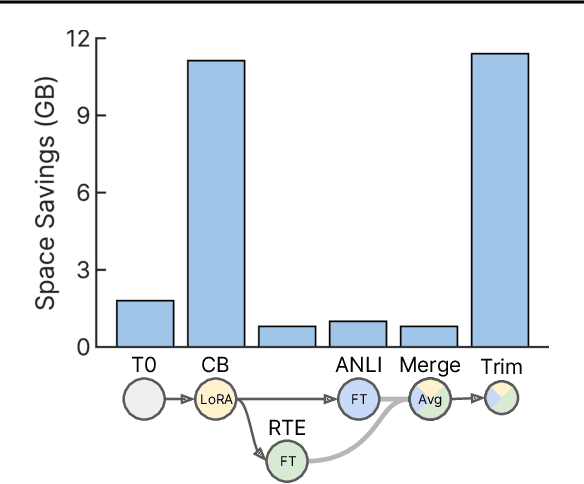
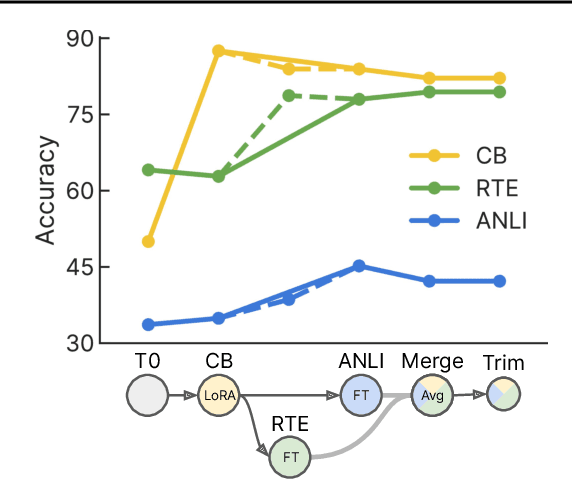
Currently, most machine learning models are trained by centralized teams and are rarely updated. In contrast, open-source software development involves the iterative development of a shared artifact through distributed collaboration using a version control system. In the interest of enabling collaborative and continual improvement of machine learning models, we introduce Git-Theta, a version control system for machine learning models. Git-Theta is an extension to Git, the most widely used version control software, that allows fine-grained tracking of changes to model parameters alongside code and other artifacts. Unlike existing version control systems that treat a model checkpoint as a blob of data, Git-Theta leverages the structure of checkpoints to support communication-efficient updates, automatic model merges, and meaningful reporting about the difference between two versions of a model. In addition, Git-Theta includes a plug-in system that enables users to easily add support for new functionality. In this paper, we introduce Git-Theta's design and features and include an example use-case of Git-Theta where a pre-trained model is continually adapted and modified. We publicly release Git-Theta in hopes of kickstarting a new era of collaborative model development.
Soft Merging of Experts with Adaptive Routing
Jun 06, 2023



Sparsely activated neural networks with conditional computation learn to route their inputs through different "expert" subnetworks, providing a form of modularity that densely activated models lack. Despite their possible benefits, models with learned routing often underperform their parameter-matched densely activated counterparts as well as models that use non-learned heuristic routing strategies. In this paper, we hypothesize that these shortcomings stem from the gradient estimation techniques used to train sparsely activated models that use non-differentiable discrete routing decisions. To address this issue, we introduce Soft Merging of Experts with Adaptive Routing (SMEAR), which avoids discrete routing by using a single "merged" expert constructed via a weighted average of all of the experts' parameters. By routing activations through a single merged expert, SMEAR does not incur a significant increase in computational costs and enables standard gradient-based training. We empirically validate that models using SMEAR outperform models that route based on metadata or learn sparse routing through gradient estimation. Furthermore, we provide qualitative analysis demonstrating that the experts learned via SMEAR exhibit a significant amount of specialization. All of the code used in our experiments is publicly available.
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
May 11, 2022
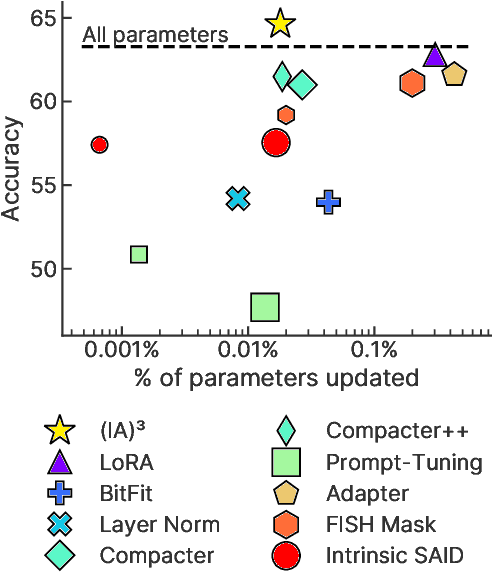
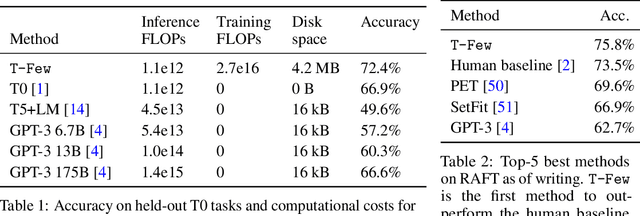
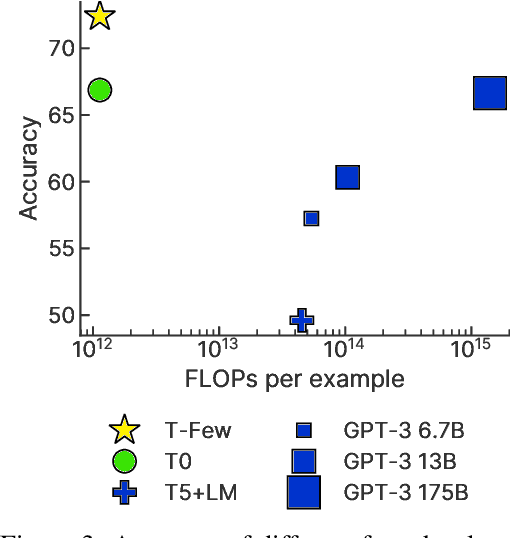
Few-shot in-context learning (ICL) enables pre-trained language models to perform a previously-unseen task without any gradient-based training by feeding a small number of training examples as part of the input. ICL incurs substantial computational, memory, and storage costs because it involves processing all of the training examples every time a prediction is made. Parameter-efficient fine-tuning (e.g. adapter modules, prompt tuning, sparse update methods, etc.) offers an alternative paradigm where a small set of parameters are trained to enable a model to perform the new task. In this paper, we rigorously compare few-shot ICL and parameter-efficient fine-tuning and demonstrate that the latter offers better accuracy as well as dramatically lower computational costs. Along the way, we introduce a new parameter-efficient fine-tuning method called (IA)$^3$ that scales activations by learned vectors, attaining stronger performance while only introducing a relatively tiny amount of new parameters. We also propose a simple recipe based on the T0 model called T-Few that can be applied to new tasks without task-specific tuning or modifications. We validate the effectiveness of T-Few on completely unseen tasks by applying it to the RAFT benchmark, attaining super-human performance for the first time and outperforming the state-of-the-art by 6% absolute. All of the code used in our experiments is publicly available.