 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineInstructions: Scaling Synthetic Instructions to Pre-Training Scale
Jan 29, 2026Due to limited supervised training data, large language models (LLMs) are typically pre-trained via a self-supervised "predict the next word" objective on a vast amount of unstructured text data. To make the resulting model useful to users, it is further trained on a far smaller amount of "instruction-tuning" data comprised of supervised training examples of instructions and responses. To overcome the limited amount of supervised data, we propose a procedure that can transform the knowledge in internet-scale pre-training documents into billions of synthetic instruction and answer training pairs. The resulting dataset, called FineInstructions, uses ~18M instruction templates created from real user-written queries and prompts. These instruction templates are matched to and instantiated with human-written source documents from unstructured pre-training corpora. With "supervised" synthetic training data generated at this scale, an LLM can be pre-trained from scratch solely with the instruction-tuning objective, which is far more in-distribution with the expected downstream usage of LLMs (responding to user prompts). We conduct controlled token-for-token training experiments and find pre-training on FineInstructions outperforms standard pre-training and other proposed synthetic pre-training techniques on standard benchmarks measuring free-form response quality. Our resources can be found at https://huggingface.co/fineinstructions .
Efficiently Estimating Data Efficiency for Language Model Fine-tuning
Dec 31, 2025While large language models (LLMs) demonstrate reasonable zero-shot capability across many downstream tasks, fine-tuning is a common practice to improve their performance. However, a task's data efficiency--i.e., the number of fine-tuning examples needed to achieve a desired level of performance--is often unknown, resulting in costly cycles of incremental annotation and retraining. Indeed, we demonstrate across a curated set of 30 specialized tasks that performant LLMs may struggle zero-shot but can attain stronger performance after fine-tuning. This motivates the need for methods to predict a task's data efficiency without requiring incremental annotation. After introducing a concrete metric that quantifies a task's data efficiency, we propose using the gradient cosine similarity of low-confidence examples to predict data efficiency based on a small number of labeled samples. We validate our approach on a diverse set of tasks with varying data efficiencies, attaining 8.6% error in overall data efficiency prediction and typically eliminating hundreds of unnecessary annotations on each task. Our experiment results and implementation code are available on GitHub.
TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
The Butterfly Effect: Neural Network Training Trajectories Are Highly Sensitive to Initial Conditions
Jun 16, 2025Neural network training is inherently sensitive to initialization and the randomness induced by stochastic gradient descent. However, it is unclear to what extent such effects lead to meaningfully different networks, either in terms of the models' weights or the underlying functions that were learned. In this work, we show that during the initial "chaotic" phase of training, even extremely small perturbations reliably causes otherwise identical training trajectories to diverge-an effect that diminishes rapidly over training time. We quantify this divergence through (i) $L^2$ distance between parameters, (ii) the loss barrier when interpolating between networks, (iii) $L^2$ and barrier between parameters after permutation alignment, and (iv) representational similarity between intermediate activations; revealing how perturbations across different hyperparameter or fine-tuning settings drive training trajectories toward distinct loss minima. Our findings provide insights into neural network training stability, with practical implications for fine-tuning, model merging, and diversity of model ensembles.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Enhancing Training Data Attribution with Representational Optimization
May 24, 2025Training data attribution (TDA) methods aim to measure how training data impacts a model's predictions. While gradient-based attribution methods, such as influence functions, offer theoretical grounding, their computational costs make them impractical for large-scale applications. Representation-based approaches are far more scalable, but typically rely on heuristic embeddings that are not optimized for attribution, limiting their fidelity. To address these challenges, we propose AirRep, a scalable, representation-based approach that closes this gap by learning task-specific and model-aligned representations optimized explicitly for TDA. AirRep introduces two key innovations: a trainable encoder tuned for attribution quality, and an attention-based pooling mechanism that enables accurate estimation of group-wise influence. We train AirRep using a ranking objective over automatically constructed training subsets labeled by their empirical effect on target predictions. Experiments on instruction-tuned LLMs demonstrate that AirRep achieves performance on par with state-of-the-art gradient-based approaches while being nearly two orders of magnitude more efficient at inference time. Further analysis highlights its robustness and generalization across tasks and models. Our code is available at https://github.com/sunnweiwei/AirRep.
Position: The Most Expensive Part of an LLM should be its Training Data
Apr 16, 2025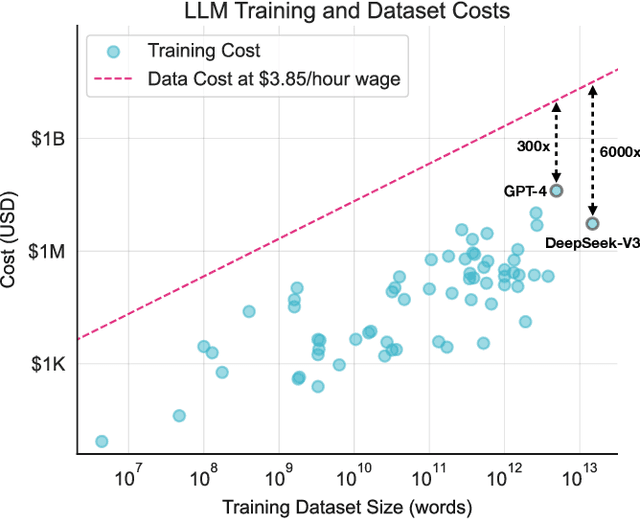
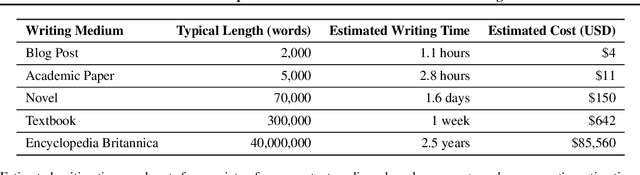
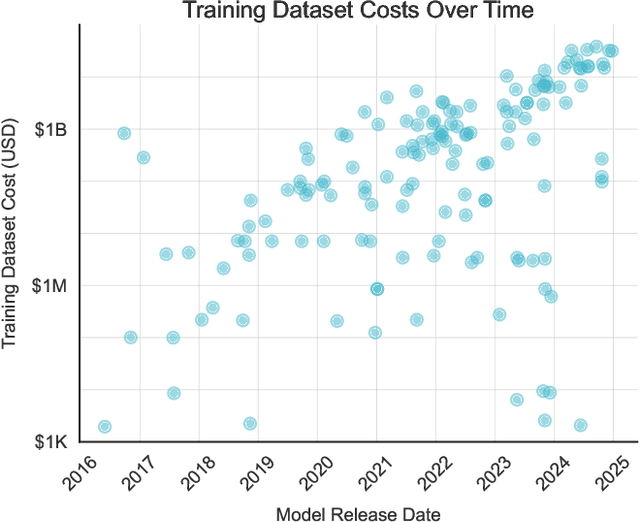
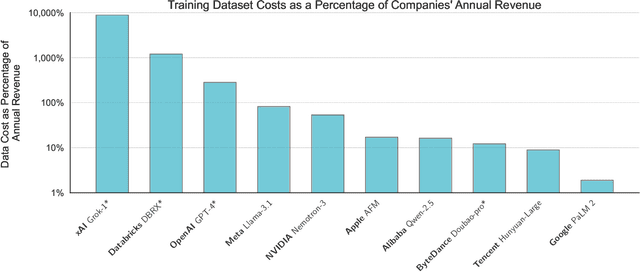
Training a state-of-the-art Large Language Model (LLM) is an increasingly expensive endeavor due to growing computational, hardware, energy, and engineering demands. Yet, an often-overlooked (and seldom paid) expense is the human labor behind these models' training data. Every LLM is built on an unfathomable amount of human effort: trillions of carefully written words sourced from books, academic papers, codebases, social media, and more. This position paper aims to assign a monetary value to this labor and argues that the most expensive part of producing an LLM should be the compensation provided to training data producers for their work. To support this position, we study 64 LLMs released between 2016 and 2024, estimating what it would cost to pay people to produce their training datasets from scratch. Even under highly conservative estimates of wage rates, the costs of these models' training datasets are 10-1000 times larger than the costs to train the models themselves, representing a significant financial liability for LLM providers. In the face of the massive gap between the value of training data and the lack of compensation for its creation, we highlight and discuss research directions that could enable fairer practices in the future.
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Feb 04, 2025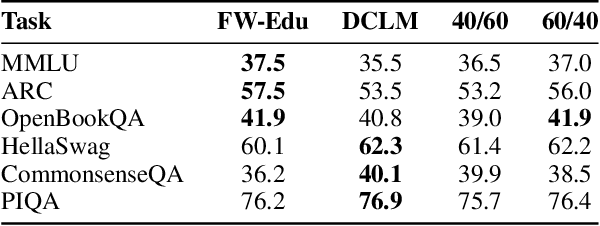
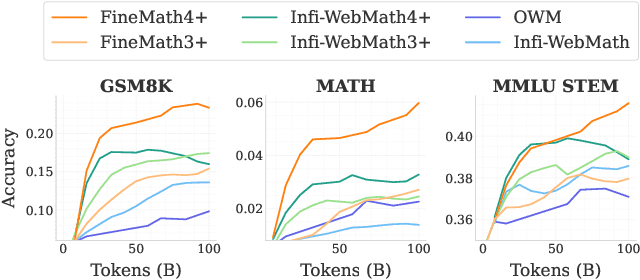
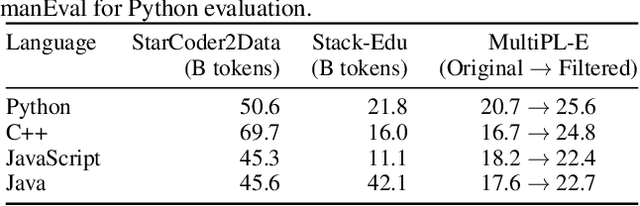
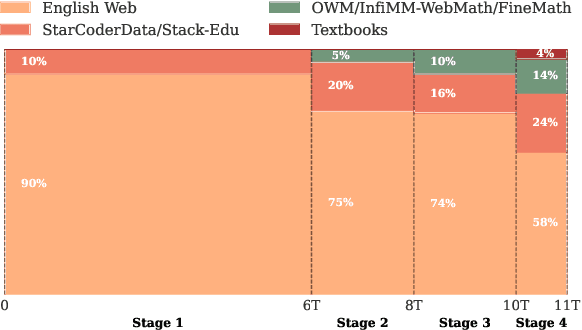
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
AttriBoT: A Bag of Tricks for Efficiently Approximating Leave-One-Out Context Attribution
Nov 22, 2024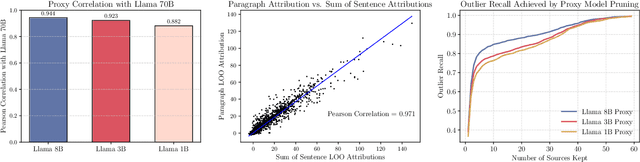



The influence of contextual input on the behavior of large language models (LLMs) has prompted the development of context attribution methods that aim to quantify each context span's effect on an LLM's generations. The leave-one-out (LOO) error, which measures the change in the likelihood of the LLM's response when a given span of the context is removed, provides a principled way to perform context attribution, but can be prohibitively expensive to compute for large models. In this work, we introduce AttriBoT, a series of novel techniques for efficiently computing an approximation of the LOO error for context attribution. Specifically, AttriBoT uses cached activations to avoid redundant operations, performs hierarchical attribution to reduce computation, and emulates the behavior of large target models with smaller proxy models. Taken together, AttriBoT can provide a >300x speedup while remaining more faithful to a target model's LOO error than prior context attribution methods. This stark increase in performance makes computing context attributions for a given response 30x faster than generating the response itself, empowering real-world applications that require computing attributions at scale. We release a user-friendly and efficient implementation of AttriBoT to enable efficient LLM interpretability as well as encourage future development of efficient context attribution methods.