 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen ASR Leaderboard: Towards Reproducible and Transparent Multilingual and Long-Form Speech Recognition Evaluation
Oct 08, 2025Despite rapid progress, ASR evaluation remains saturated with short-form English, and efficiency is rarely reported. We present the Open ASR Leaderboard, a fully reproducible benchmark and interactive leaderboard comparing 60+ open-source and proprietary systems across 11 datasets, including dedicated multilingual and long-form tracks. We standardize text normalization and report both word error rate (WER) and inverse real-time factor (RTFx), enabling fair accuracy-efficiency comparisons. For English transcription, Conformer encoders paired with LLM decoders achieve the best average WER but are slower, while CTC and TDT decoders deliver much better RTFx, making them attractive for long-form and offline use. Whisper-derived encoders fine-tuned for English improve accuracy but often trade off multilingual coverage. All code and dataset loaders are open-sourced to support transparent, extensible evaluation.
SmolVLM: Redefining small and efficient multimodal models
Apr 07, 2025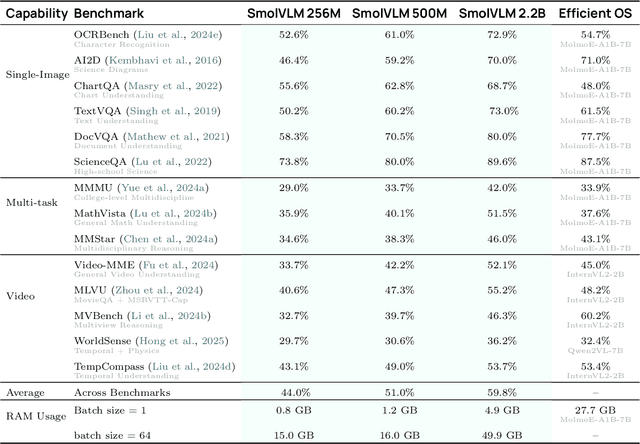
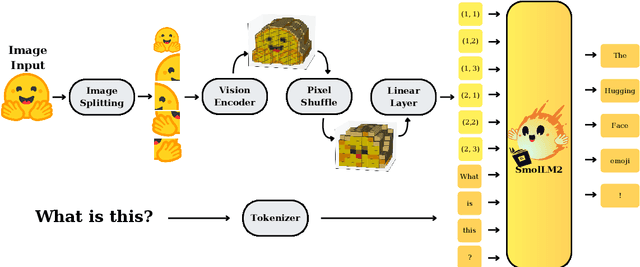
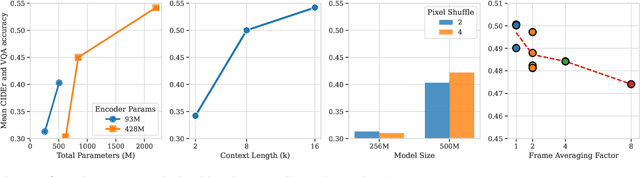

Large Vision-Language Models (VLMs) deliver exceptional performance but require significant computational resources, limiting their deployment on mobile and edge devices. Smaller VLMs typically mirror design choices of larger models, such as extensive image tokenization, leading to inefficient GPU memory usage and constrained practicality for on-device applications. We introduce SmolVLM, a series of compact multimodal models specifically engineered for resource-efficient inference. We systematically explore architectural configurations, tokenization strategies, and data curation optimized for low computational overhead. Through this, we identify key design choices that yield substantial performance gains on image and video tasks with minimal memory footprints. Our smallest model, SmolVLM-256M, uses less than 1GB GPU memory during inference and outperforms the 300-times larger Idefics-80B model, despite an 18-month development gap. Our largest model, at 2.2B parameters, rivals state-of-the-art VLMs consuming twice the GPU memory. SmolVLM models extend beyond static images, demonstrating robust video comprehension capabilities. Our results emphasize that strategic architectural optimizations, aggressive yet efficient tokenization, and carefully curated training data significantly enhance multimodal performance, facilitating practical, energy-efficient deployments at significantly smaller scales.
ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
Mar 11, 2025



Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Feb 04, 2025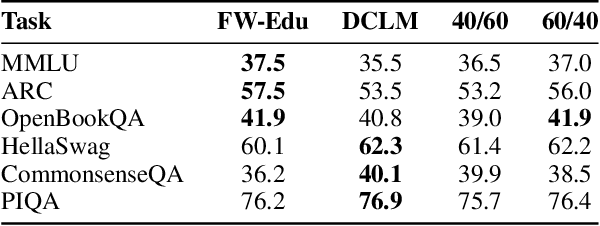
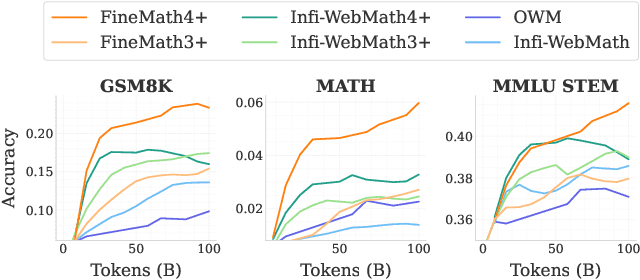
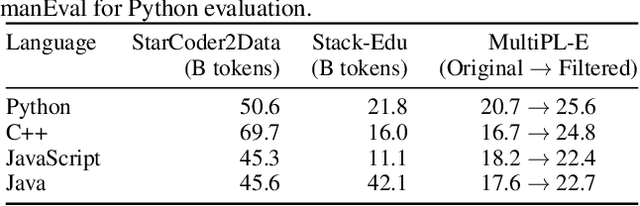
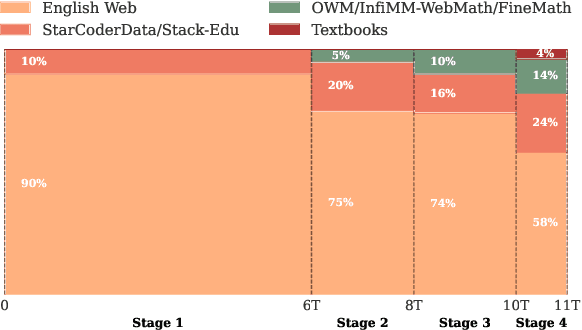
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
Lina-Speech: Gated Linear Attention is a Fast and Parameter-Efficient Learner for text-to-speech synthesis
Oct 30, 2024



Neural codec language models have achieved state-of-the-art performance in text-to-speech (TTS) synthesis, leveraging scalable architectures like autoregressive transformers and large-scale speech datasets. By framing voice cloning as a prompt continuation task, these models excel at cloning voices from short audio samples. However, this approach is limited in its ability to handle numerous or lengthy speech excerpts, since the concatenation of source and target speech must fall within the maximum context length which is determined during training. In this work, we introduce Lina-Speech, a model that replaces traditional self-attention mechanisms with emerging recurrent architectures like Gated Linear Attention (GLA). Building on the success of initial-state tuning on RWKV, we extend this technique to voice cloning, enabling the use of multiple speech samples and full utilization of the context window in synthesis. This approach is fast, easy to deploy, and achieves performance comparable to fine-tuned baselines when the dataset size ranges from 3 to 15 minutes. Notably, Lina-Speech matches or outperforms state-of-the-art baseline models, including some with a parameter count up to four times higher or trained in an end-to-end style. We release our code and checkpoints. Audio samples are available at https://theodorblackbird.github.io/blog/demo_lina/.
ESPnet-EZ: Python-only ESPnet for Easy Fine-tuning and Integration
Sep 14, 2024We introduce ESPnet-EZ, an extension of the open-source speech processing toolkit ESPnet, aimed at quick and easy development of speech models. ESPnet-EZ focuses on two major aspects: (i) easy fine-tuning and inference of existing ESPnet models on various tasks and (ii) easy integration with popular deep neural network frameworks such as PyTorch-Lightning, Hugging Face transformers and datasets, and Lhotse. By replacing ESPnet design choices inherited from Kaldi with a Python-only, Bash-free interface, we dramatically reduce the effort required to build, debug, and use a new model. For example, to fine-tune a speech foundation model, ESPnet-EZ, compared to ESPnet, reduces the number of newly written code by 2.7x and the amount of dependent code by 6.7x while dramatically reducing the Bash script dependencies. The codebase of ESPnet-EZ is publicly available.
Embarrassingly Simple Performance Prediction for Abductive Natural Language Inference
Apr 08, 2022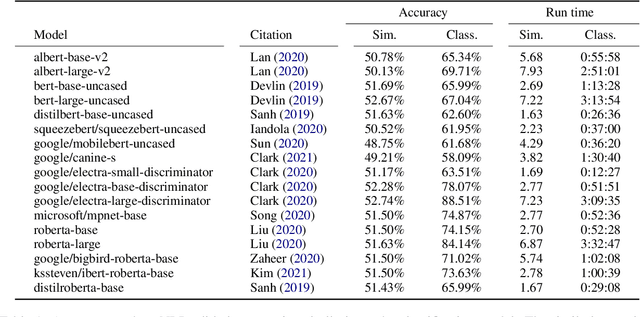
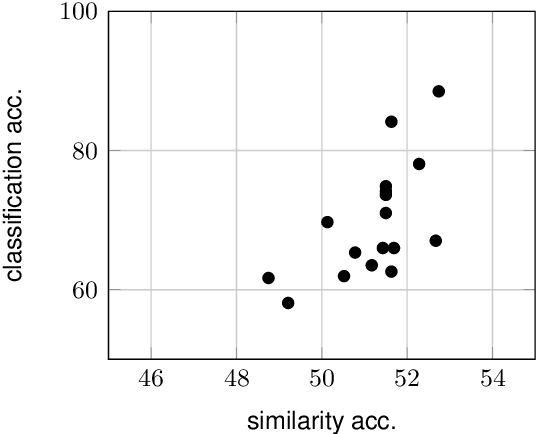
The task of abductive natural language inference (\alpha{}nli), to decide which hypothesis is the more likely explanation for a set of observations, is a particularly difficult type of NLI. Instead of just determining a causal relationship, it requires common sense to also evaluate how reasonable an explanation is. All recent competitive systems build on top of contextualized representations and make use of transformer architectures for learning an NLI model. When somebody is faced with a particular NLI task, they need to select the best model that is available. This is a time-consuming and resource-intense endeavour. To solve this practical problem, we propose a simple method for predicting the performance without actually fine-tuning the model. We do this by testing how well the pre-trained models perform on the \alpha{}nli task when just comparing sentence embeddings with cosine similarity to what the performance that is achieved when training a classifier on top of these embeddings. We show that the accuracy of the cosine similarity approach correlates strongly with the accuracy of the classification approach with a Pearson correlation coefficient of 0.65. Since the similarity computation is orders of magnitude faster to compute on a given dataset (less than a minute vs. hours), our method can lead to significant time savings in the process of model selection.