 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025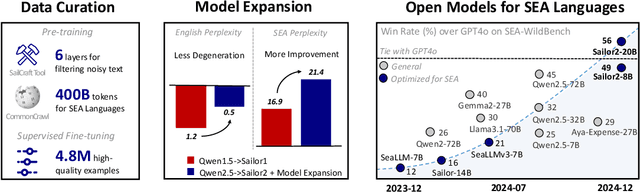

Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Feb 04, 2025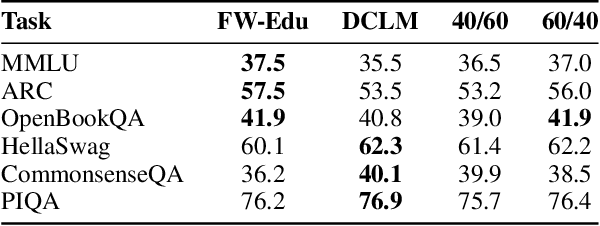
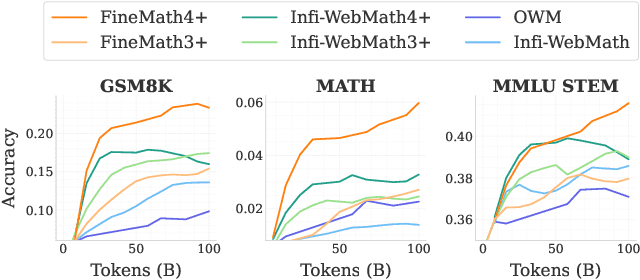
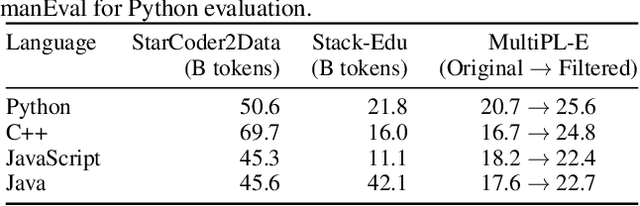
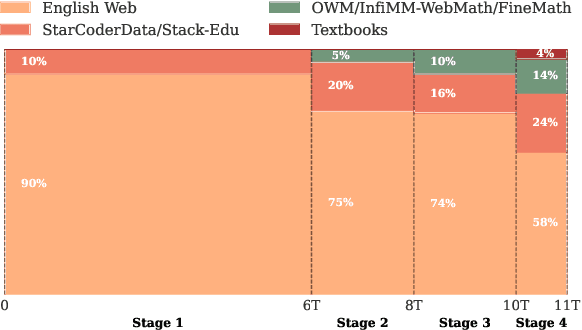
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Jun 25, 2024



The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama 3 and Mixtral are not publicly available and very little is known about how they were created. In this work, we introduce FineWeb, a 15-trillion token dataset derived from 96 Common Crawl snapshots that produces better-performing LLMs than other open pretraining datasets. To advance the understanding of how best to curate high-quality pretraining datasets, we carefully document and ablate all of the design choices used in FineWeb, including in-depth investigations of deduplication and filtering strategies. In addition, we introduce FineWeb-Edu, a 1.3-trillion token collection of educational text filtered from FineWeb. LLMs pretrained on FineWeb-Edu exhibit dramatically better performance on knowledge- and reasoning-intensive benchmarks like MMLU and ARC. Along with our datasets, we publicly release our data curation codebase and all of the models trained during our ablation experiments.
A Dataset and Strong Baselines for Classification of Czech News Texts
Jul 20, 2023



Pre-trained models for Czech Natural Language Processing are often evaluated on purely linguistic tasks (POS tagging, parsing, NER) and relatively simple classification tasks such as sentiment classification or article classification from a single news source. As an alternative, we present CZEch~NEws~Classification~dataset (CZE-NEC), one of the largest Czech classification datasets, composed of news articles from various sources spanning over twenty years, which allows a more rigorous evaluation of such models. We define four classification tasks: news source, news category, inferred author's gender, and day of the week. To verify the task difficulty, we conducted a human evaluation, which revealed that human performance lags behind strong machine-learning baselines built upon pre-trained transformer models. Furthermore, we show that language-specific pre-trained encoder analysis outperforms selected commercially available large-scale generative language models.