 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe KL3M Data Project: Copyright-Clean Training Resources for Large Language Models
Apr 10, 2025Practically all large language models have been pre-trained on data that is subject to global uncertainty related to copyright infringement and breach of contract. This creates potential risk for users and developers due to this uncertain legal status. The KL3M Data Project directly confronts this critical issue by introducing the largest comprehensive training data pipeline that minimizes risks related to copyright or breach of contract. The foundation of this project is a corpus of over 132 million documents and trillions of tokens spanning 16 different sources that have been verified to meet the strict copyright and licensing protocol detailed herein. We are releasing the entire pipeline, including 1) the source code to acquire and process these documents, 2) the original document formats with associated provenance and metadata, 3) extracted content in a standardized format, 4) pre-tokenized representations of the documents, and 5) various mid- and post-train resources such as question-answer, summarization, conversion, drafting, classification, prediction, and conversational data. All of these resources are freely available to the public on S3, Hugging Face, and GitHub under CC-BY terms. We are committed to continuing this project in furtherance of a more ethical, legal, and sustainable approach to the development and use of AI models.
Precise Legal Sentence Boundary Detection for Retrieval at Scale: NUPunkt and CharBoundary
Apr 05, 2025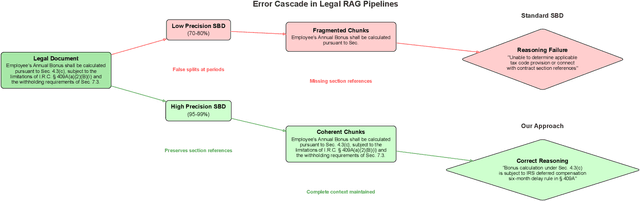
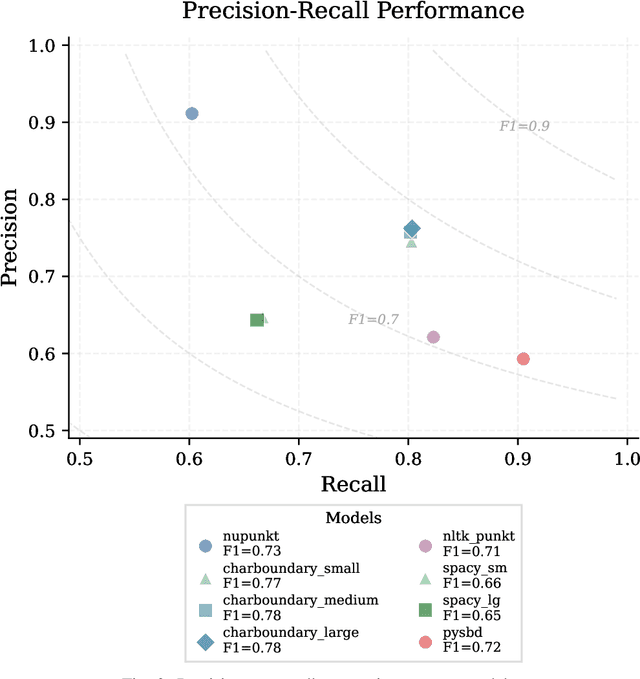
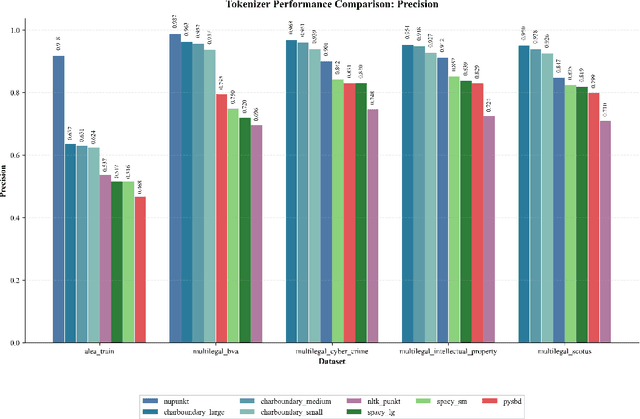
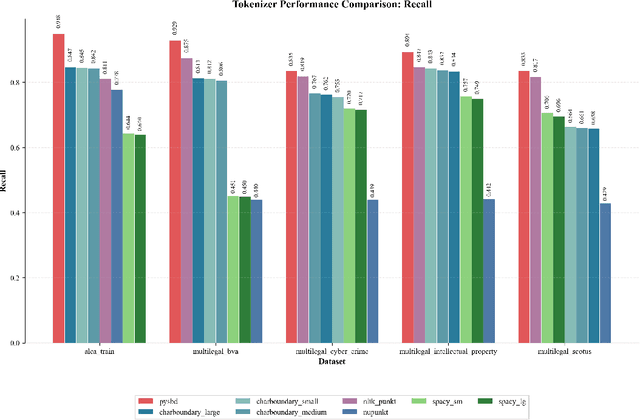
We present NUPunkt and CharBoundary, two sentence boundary detection libraries optimized for high-precision, high-throughput processing of legal text in large-scale applications such as due diligence, e-discovery, and legal research. These libraries address the critical challenges posed by legal documents containing specialized citations, abbreviations, and complex sentence structures that confound general-purpose sentence boundary detectors. Our experimental evaluation on five diverse legal datasets comprising over 25,000 documents and 197,000 annotated sentence boundaries demonstrates that NUPunkt achieves 91.1% precision while processing 10 million characters per second with modest memory requirements (432 MB). CharBoundary models offer balanced and adjustable precision-recall tradeoffs, with the large model achieving the highest F1 score (0.782) among all tested methods. Notably, NUPunkt provides a 29-32% precision improvement over general-purpose tools while maintaining exceptional throughput, processing multi-million document collections in minutes rather than hours. Both libraries run efficiently on standard CPU hardware without requiring specialized accelerators. NUPunkt is implemented in pure Python with zero external dependencies, while CharBoundary relies only on scikit-learn and optional ONNX runtime integration for optimized performance. Both libraries are available under the MIT license, can be installed via PyPI, and can be interactively tested at https://sentences.aleainstitute.ai/. These libraries address critical precision issues in retrieval-augmented generation systems by preserving coherent legal concepts across sentences, where each percentage improvement in precision yields exponentially greater reductions in context fragmentation, creating cascading benefits throughout retrieval pipelines and significantly enhancing downstream reasoning quality.
KL3M Tokenizers: A Family of Domain-Specific and Character-Level Tokenizers for Legal, Financial, and Preprocessing Applications
Mar 21, 2025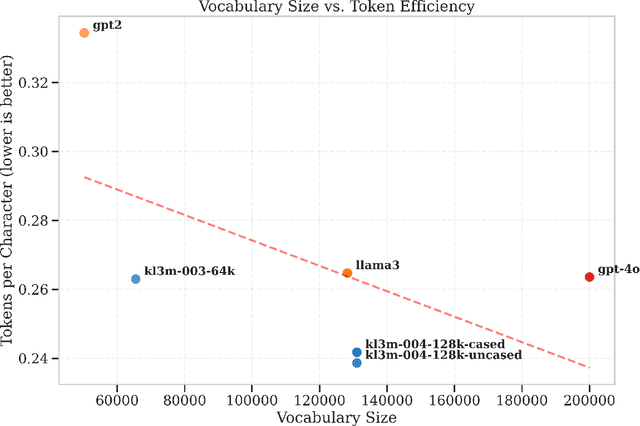
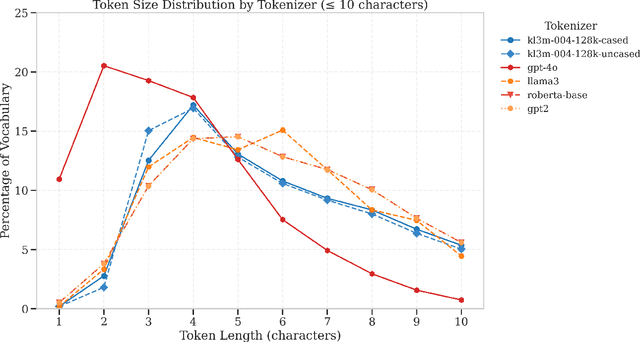
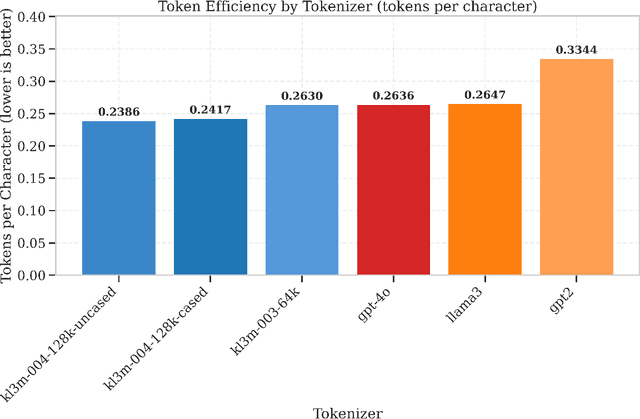

We present the KL3M tokenizers, a family of specialized tokenizers for legal, financial, and governmental text. Despite established work on tokenization, specialized tokenizers for professional domains remain understudied. Our paper offers two main contributions to this area. First, we introduce domain-specific BPE tokenizers for legal, financial, and governmental text. Our kl3m-004-128k-cased tokenizer uses 9-17% fewer tokens than GPT-4o and Llama3 for domain-specific documents, despite having a smaller vocabulary. For specialized terminology, our cased tokenizer is even more efficient, using up to 83% fewer tokens for legal terms and 39% fewer tokens for financial terms. Second, we develop character-level BPE tokenizers (4K, 8K, and 16K vocabulary sizes) for text correction tasks like OCR post-processing. These tokenizers keep consistent token boundaries between error-containing and correct text, making it easier for models to learn correction patterns. These tokenizers help professional applications by fitting more text in context windows, reducing computational needs, and preserving the meaning of domain-specific terms. Our analysis shows these efficiency gains directly benefit the processing of long legal and financial documents. We release all tokenizers and code through GitHub and Hugging Face to support further research in specialized tokenization.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
GPT as Knowledge Worker: A Zero-Shot Evaluation of CPA Capabilities
Jan 11, 2023The global economy is increasingly dependent on knowledge workers to meet the needs of public and private organizations. While there is no single definition of knowledge work, organizations and industry groups still attempt to measure individuals' capability to engage in it. The most comprehensive assessment of capability readiness for professional knowledge workers is the Uniform CPA Examination developed by the American Institute of Certified Public Accountants (AICPA). In this paper, we experimentally evaluate OpenAI's `text-davinci-003` and prior versions of GPT on both a sample Regulation (REG) exam and an assessment of over 200 multiple-choice questions based on the AICPA Blueprints for legal, financial, accounting, technology, and ethical tasks. First, we find that `text-davinci-003` achieves a correct rate of 14.4% on a sample REG exam section, significantly underperforming human capabilities on quantitative reasoning in zero-shot prompts. Second, `text-davinci-003` appears to be approaching human-level performance on the Remembering & Understanding and Application skill levels in the Exam absent calculation. For best prompt and parameters, the model answers 57.6% of questions correctly, significantly better than the 25% guessing rate, and its top two answers are correct 82.1% of the time, indicating strong non-entailment. Finally, we find that recent generations of GPT-3 demonstrate material improvements on this assessment, rising from 30% for `text-davinci-001` to 57% for `text-davinci-003`. These findings strongly suggest that large language models have the potential to transform the quality and efficiency of future knowledge work.