 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Legal Sentence Boundary Detection for Retrieval at Scale: NUPunkt and CharBoundary
Apr 05, 2025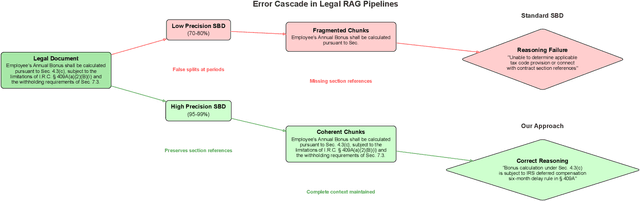
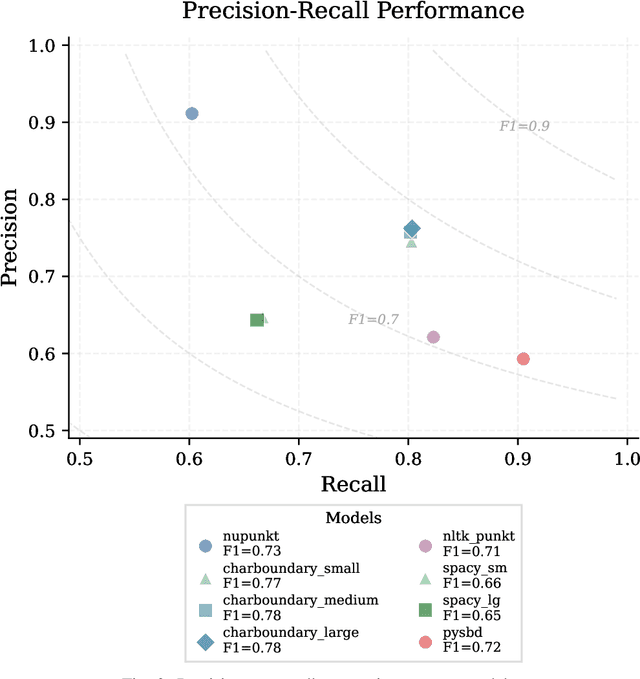
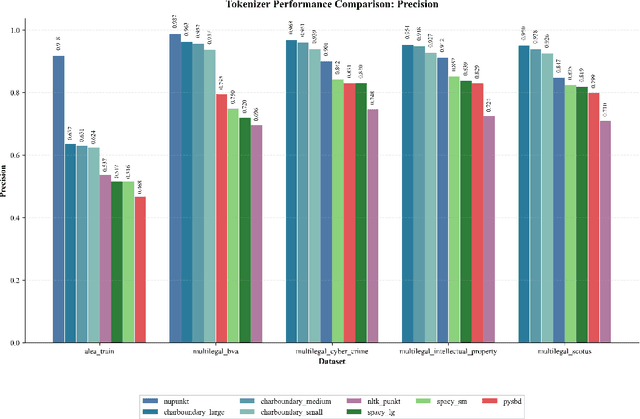
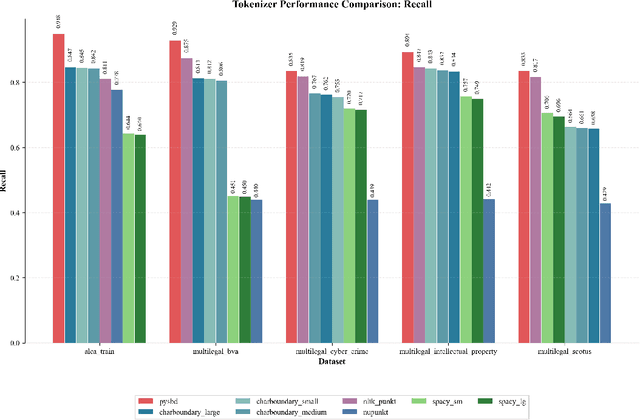
We present NUPunkt and CharBoundary, two sentence boundary detection libraries optimized for high-precision, high-throughput processing of legal text in large-scale applications such as due diligence, e-discovery, and legal research. These libraries address the critical challenges posed by legal documents containing specialized citations, abbreviations, and complex sentence structures that confound general-purpose sentence boundary detectors. Our experimental evaluation on five diverse legal datasets comprising over 25,000 documents and 197,000 annotated sentence boundaries demonstrates that NUPunkt achieves 91.1% precision while processing 10 million characters per second with modest memory requirements (432 MB). CharBoundary models offer balanced and adjustable precision-recall tradeoffs, with the large model achieving the highest F1 score (0.782) among all tested methods. Notably, NUPunkt provides a 29-32% precision improvement over general-purpose tools while maintaining exceptional throughput, processing multi-million document collections in minutes rather than hours. Both libraries run efficiently on standard CPU hardware without requiring specialized accelerators. NUPunkt is implemented in pure Python with zero external dependencies, while CharBoundary relies only on scikit-learn and optional ONNX runtime integration for optimized performance. Both libraries are available under the MIT license, can be installed via PyPI, and can be interactively tested at https://sentences.aleainstitute.ai/. These libraries address critical precision issues in retrieval-augmented generation systems by preserving coherent legal concepts across sentences, where each percentage improvement in precision yields exponentially greater reductions in context fragmentation, creating cascading benefits throughout retrieval pipelines and significantly enhancing downstream reasoning quality.
KL3M Tokenizers: A Family of Domain-Specific and Character-Level Tokenizers for Legal, Financial, and Preprocessing Applications
Mar 21, 2025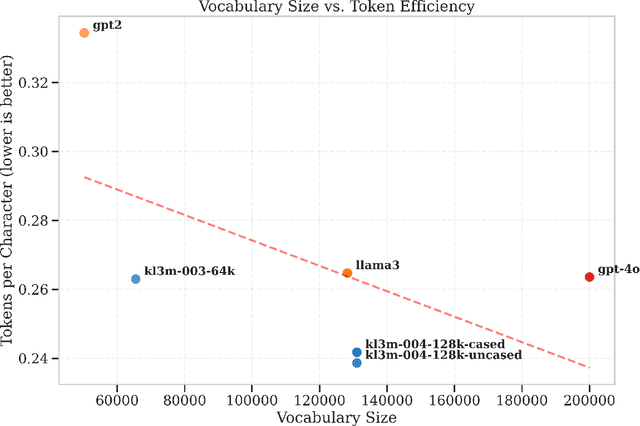
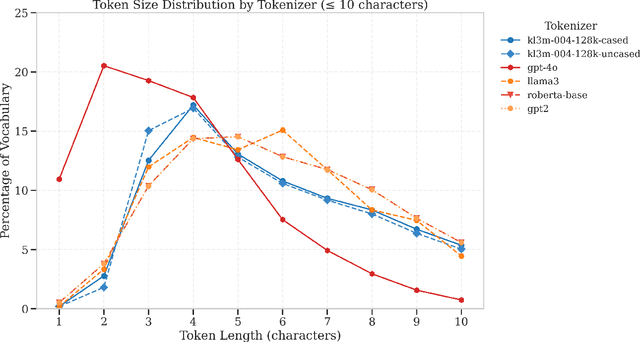
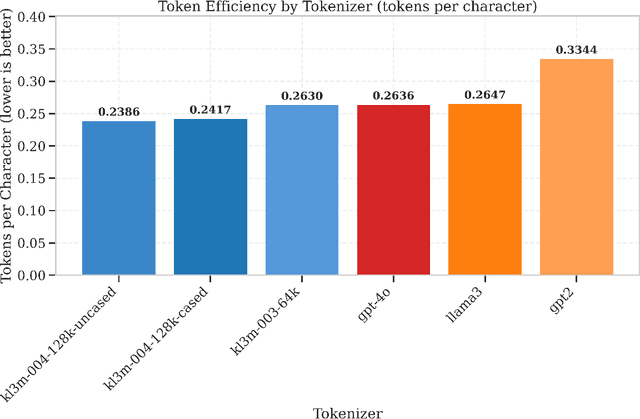

We present the KL3M tokenizers, a family of specialized tokenizers for legal, financial, and governmental text. Despite established work on tokenization, specialized tokenizers for professional domains remain understudied. Our paper offers two main contributions to this area. First, we introduce domain-specific BPE tokenizers for legal, financial, and governmental text. Our kl3m-004-128k-cased tokenizer uses 9-17% fewer tokens than GPT-4o and Llama3 for domain-specific documents, despite having a smaller vocabulary. For specialized terminology, our cased tokenizer is even more efficient, using up to 83% fewer tokens for legal terms and 39% fewer tokens for financial terms. Second, we develop character-level BPE tokenizers (4K, 8K, and 16K vocabulary sizes) for text correction tasks like OCR post-processing. These tokenizers keep consistent token boundaries between error-containing and correct text, making it easier for models to learn correction patterns. These tokenizers help professional applications by fitting more text in context windows, reducing computational needs, and preserving the meaning of domain-specific terms. Our analysis shows these efficiency gains directly benefit the processing of long legal and financial documents. We release all tokenizers and code through GitHub and Hugging Face to support further research in specialized tokenization.