 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAPH-GRPO-LEX: Contract Graph Modeling and Reinforcement Learning with Group Relative Policy Optimization
Nov 10, 2025Contracts are complex documents featuring detailed formal structures, explicit and implicit dependencies and rich semantic content. Given these document properties, contract drafting and manual examination of contracts have proven to be both arduous and susceptible to errors. This work aims to simplify and automate the task of contract review and analysis using a novel framework for transforming legal contracts into structured semantic graphs, enabling computational analysis and data-driven insights. We introduce a detailed ontology mapping core legal contract elements to their graph-theoretic equivalents of nodes and edges. We then present a reinforcement learning based Large Language Model (LLM) framework for segmentation and extraction of entities and relationships from contracts. Our method, GRAPH-GRPO-LEX, incorporates both LLMs and reinforcement learning with group relative policy optimization (GRPO). By applying a carefully drafted reward function of graph metrics, we demonstrate the ability to automatically identify direct relationships between clauses, and even uncover hidden dependencies. Our introduction of the gated GRPO approach shows a strong learning signal and can move contract analysis from a linear, manual reading process to an easily visualized graph. This allows for a more dynamic analysis, including building the groundwork for contract linting similar to what is now practiced in software engineering.
The KL3M Data Project: Copyright-Clean Training Resources for Large Language Models
Apr 10, 2025Practically all large language models have been pre-trained on data that is subject to global uncertainty related to copyright infringement and breach of contract. This creates potential risk for users and developers due to this uncertain legal status. The KL3M Data Project directly confronts this critical issue by introducing the largest comprehensive training data pipeline that minimizes risks related to copyright or breach of contract. The foundation of this project is a corpus of over 132 million documents and trillions of tokens spanning 16 different sources that have been verified to meet the strict copyright and licensing protocol detailed herein. We are releasing the entire pipeline, including 1) the source code to acquire and process these documents, 2) the original document formats with associated provenance and metadata, 3) extracted content in a standardized format, 4) pre-tokenized representations of the documents, and 5) various mid- and post-train resources such as question-answer, summarization, conversion, drafting, classification, prediction, and conversational data. All of these resources are freely available to the public on S3, Hugging Face, and GitHub under CC-BY terms. We are committed to continuing this project in furtherance of a more ethical, legal, and sustainable approach to the development and use of AI models.
Precise Legal Sentence Boundary Detection for Retrieval at Scale: NUPunkt and CharBoundary
Apr 05, 2025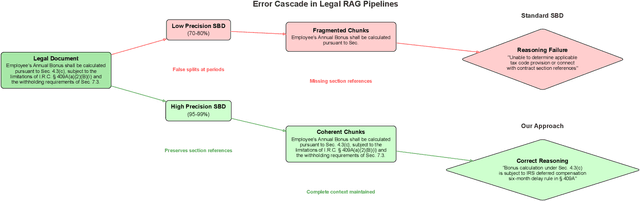
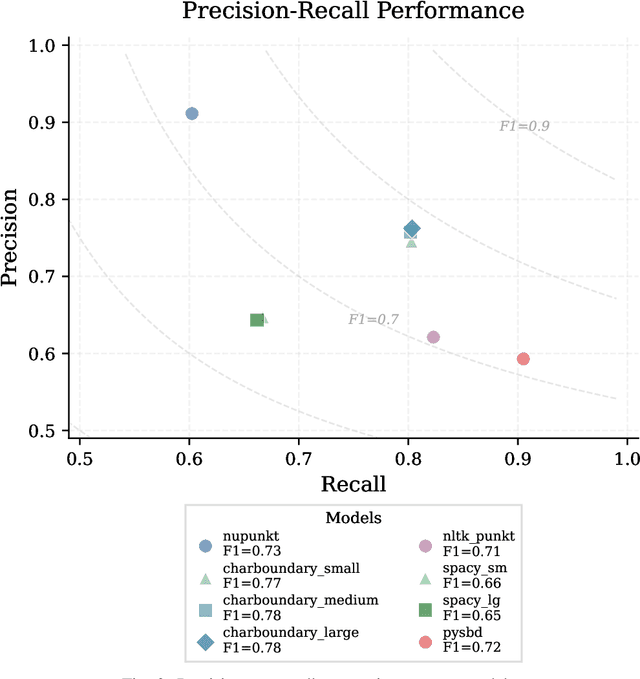
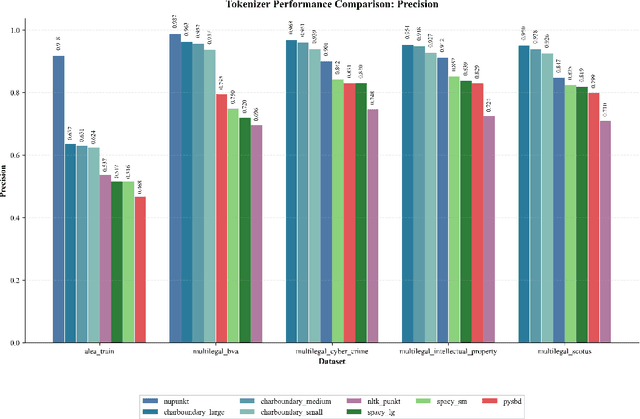
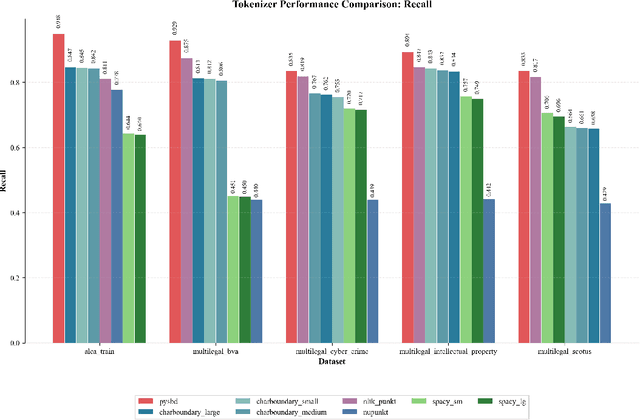
We present NUPunkt and CharBoundary, two sentence boundary detection libraries optimized for high-precision, high-throughput processing of legal text in large-scale applications such as due diligence, e-discovery, and legal research. These libraries address the critical challenges posed by legal documents containing specialized citations, abbreviations, and complex sentence structures that confound general-purpose sentence boundary detectors. Our experimental evaluation on five diverse legal datasets comprising over 25,000 documents and 197,000 annotated sentence boundaries demonstrates that NUPunkt achieves 91.1% precision while processing 10 million characters per second with modest memory requirements (432 MB). CharBoundary models offer balanced and adjustable precision-recall tradeoffs, with the large model achieving the highest F1 score (0.782) among all tested methods. Notably, NUPunkt provides a 29-32% precision improvement over general-purpose tools while maintaining exceptional throughput, processing multi-million document collections in minutes rather than hours. Both libraries run efficiently on standard CPU hardware without requiring specialized accelerators. NUPunkt is implemented in pure Python with zero external dependencies, while CharBoundary relies only on scikit-learn and optional ONNX runtime integration for optimized performance. Both libraries are available under the MIT license, can be installed via PyPI, and can be interactively tested at https://sentences.aleainstitute.ai/. These libraries address critical precision issues in retrieval-augmented generation systems by preserving coherent legal concepts across sentences, where each percentage improvement in precision yields exponentially greater reductions in context fragmentation, creating cascading benefits throughout retrieval pipelines and significantly enhancing downstream reasoning quality.
KL3M Tokenizers: A Family of Domain-Specific and Character-Level Tokenizers for Legal, Financial, and Preprocessing Applications
Mar 21, 2025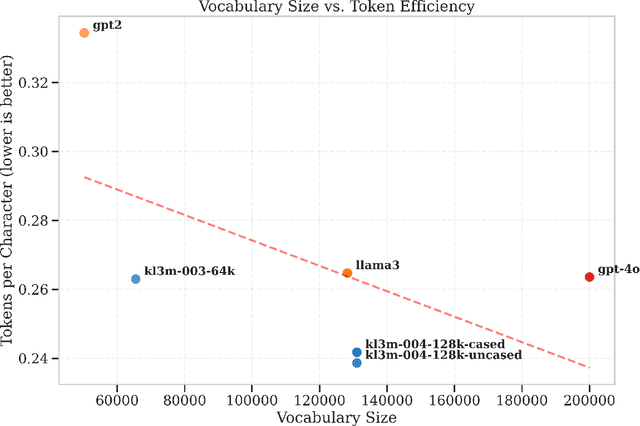
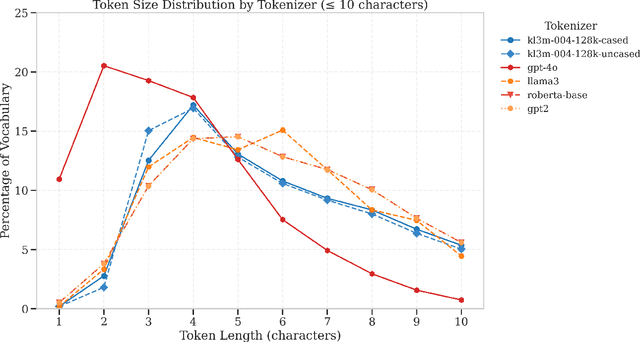
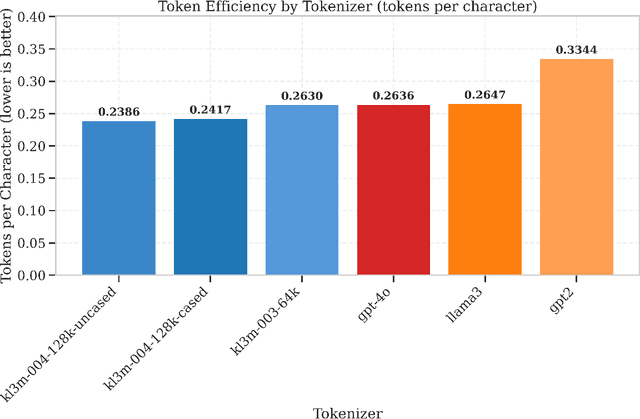

We present the KL3M tokenizers, a family of specialized tokenizers for legal, financial, and governmental text. Despite established work on tokenization, specialized tokenizers for professional domains remain understudied. Our paper offers two main contributions to this area. First, we introduce domain-specific BPE tokenizers for legal, financial, and governmental text. Our kl3m-004-128k-cased tokenizer uses 9-17% fewer tokens than GPT-4o and Llama3 for domain-specific documents, despite having a smaller vocabulary. For specialized terminology, our cased tokenizer is even more efficient, using up to 83% fewer tokens for legal terms and 39% fewer tokens for financial terms. Second, we develop character-level BPE tokenizers (4K, 8K, and 16K vocabulary sizes) for text correction tasks like OCR post-processing. These tokenizers keep consistent token boundaries between error-containing and correct text, making it easier for models to learn correction patterns. These tokenizers help professional applications by fitting more text in context windows, reducing computational needs, and preserving the meaning of domain-specific terms. Our analysis shows these efficiency gains directly benefit the processing of long legal and financial documents. We release all tokenizers and code through GitHub and Hugging Face to support further research in specialized tokenization.
LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development
May 22, 2023



In this work, we conduct a detailed analysis on the performance of legal-oriented pre-trained language models (PLMs). We examine the interplay between their original objective, acquired knowledge, and legal language understanding capacities which we define as the upstream, probing, and downstream performance, respectively. We consider not only the models' size but also the pre-training corpora used as important dimensions in our study. To this end, we release a multinational English legal corpus (LeXFiles) and a legal knowledge probing benchmark (LegalLAMA) to facilitate training and detailed analysis of legal-oriented PLMs. We release two new legal PLMs trained on LeXFiles and evaluate them alongside others on LegalLAMA and LexGLUE. We find that probing performance strongly correlates with upstream performance in related legal topics. On the other hand, downstream performance is mainly driven by the model's size and prior legal knowledge which can be estimated by upstream and probing performance. Based on these findings, we can conclude that both dimensions are important for those seeking the development of domain-specific PLMs.
Natural Language Processing in the Legal Domain
Feb 23, 2023



In this paper, we summarize the current state of the field of NLP & Law with a specific focus on recent technical and substantive developments. To support our analysis, we construct and analyze a nearly complete corpus of more than six hundred NLP & Law related papers published over the past decade. Our analysis highlights several major trends. Namely, we document an increasing number of papers written, tasks undertaken, and languages covered over the course of the past decade. We observe an increase in the sophistication of the methods which researchers deployed in this applied context. Slowly but surely, Legal NLP is beginning to match not only the methodological sophistication of general NLP but also the professional standards of data availability and code reproducibility observed within the broader scientific community. We believe all of these trends bode well for the future of the field, but many questions in both the academic and commercial sphere still remain open.
GPT as Knowledge Worker: A Zero-Shot Evaluation of CPA Capabilities
Jan 11, 2023The global economy is increasingly dependent on knowledge workers to meet the needs of public and private organizations. While there is no single definition of knowledge work, organizations and industry groups still attempt to measure individuals' capability to engage in it. The most comprehensive assessment of capability readiness for professional knowledge workers is the Uniform CPA Examination developed by the American Institute of Certified Public Accountants (AICPA). In this paper, we experimentally evaluate OpenAI's `text-davinci-003` and prior versions of GPT on both a sample Regulation (REG) exam and an assessment of over 200 multiple-choice questions based on the AICPA Blueprints for legal, financial, accounting, technology, and ethical tasks. First, we find that `text-davinci-003` achieves a correct rate of 14.4% on a sample REG exam section, significantly underperforming human capabilities on quantitative reasoning in zero-shot prompts. Second, `text-davinci-003` appears to be approaching human-level performance on the Remembering & Understanding and Application skill levels in the Exam absent calculation. For best prompt and parameters, the model answers 57.6% of questions correctly, significantly better than the 25% guessing rate, and its top two answers are correct 82.1% of the time, indicating strong non-entailment. Finally, we find that recent generations of GPT-3 demonstrate material improvements on this assessment, rising from 30% for `text-davinci-001` to 57% for `text-davinci-003`. These findings strongly suggest that large language models have the potential to transform the quality and efficiency of future knowledge work.
GPT Takes the Bar Exam
Dec 29, 2022



Nearly all jurisdictions in the United States require a professional license exam, commonly referred to as "the Bar Exam," as a precondition for law practice. To even sit for the exam, most jurisdictions require that an applicant completes at least seven years of post-secondary education, including three years at an accredited law school. In addition, most test-takers also undergo weeks to months of further, exam-specific preparation. Despite this significant investment of time and capital, approximately one in five test-takers still score under the rate required to pass the exam on their first try. In the face of a complex task that requires such depth of knowledge, what, then, should we expect of the state of the art in "AI?" In this research, we document our experimental evaluation of the performance of OpenAI's `text-davinci-003` model, often-referred to as GPT-3.5, on the multistate multiple choice (MBE) section of the exam. While we find no benefit in fine-tuning over GPT-3.5's zero-shot performance at the scale of our training data, we do find that hyperparameter optimization and prompt engineering positively impacted GPT-3.5's zero-shot performance. For best prompt and parameters, GPT-3.5 achieves a headline correct rate of 50.3% on a complete NCBE MBE practice exam, significantly in excess of the 25% baseline guessing rate, and performs at a passing rate for both Evidence and Torts. GPT-3.5's ranking of responses is also highly-correlated with correctness; its top two and top three choices are correct 71% and 88% of the time, respectively, indicating very strong non-entailment performance. While our ability to interpret these results is limited by nascent scientific understanding of LLMs and the proprietary nature of GPT, we believe that these results strongly suggest that an LLM will pass the MBE component of the Bar Exam in the near future.
Law Smells: Defining and Detecting Problematic Patterns in Legal Drafting
Oct 15, 2021Building on the computer science concept of code smells, we initiate the study of law smells, i.e., patterns in legal texts that pose threats to the comprehensibility and maintainability of the law. With five intuitive law smells as running examples - namely, duplicated phrase, long element, large reference tree, ambiguous syntax, and natural language obsession -, we develop a comprehensive law smell taxonomy. This taxonomy classifies law smells by when they can be detected, which aspects of law they relate to, and how they can be discovered. We introduce text-based and graph-based methods to identify instances of law smells, confirming their utility in practice using the United States Code as a test case. Our work demonstrates how ideas from software engineering can be leveraged to assess and improve the quality of legal code, thus drawing attention to an understudied area in the intersection of law and computer science and highlighting the potential of computational legal drafting.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
Oct 13, 2021
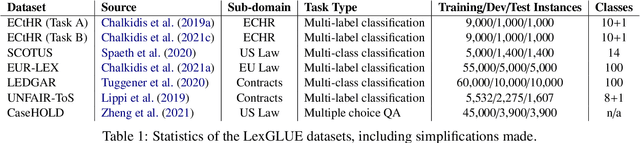

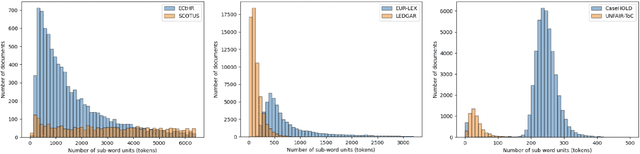
Law, interpretations of law, legal arguments, agreements, etc. are typically expressed in writing, leading to the production of vast corpora of legal text. Their analysis, which is at the center of legal practice, becomes increasingly elaborate as these collections grow in size. Natural language understanding (NLU) technologies can be a valuable tool to support legal practitioners in these endeavors. Their usefulness, however, largely depends on whether current state-of-the-art models can generalize across various tasks in the legal domain. To answer this currently open question, we introduce the Legal General Language Understanding Evaluation (LexGLUE) benchmark, a collection of datasets for evaluating model performance across a diverse set of legal NLU tasks in a standardized way. We also provide an evaluation and analysis of several generic and legal-oriented models demonstrating that the latter consistently offer performance improvements across multiple tasks.