 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceable by Design: An LLM Pipeline and Dashboard for EU Regulatory Consultation Analysis
May 29, 2026Public consultations generate large volumes of data in the form of stakeholder submissions that are practically unfeasible to analyse manually. We present an end-to-end LLM-based pipeline and interactive dashboard for structured topic extraction from regulatory consultation submissions, demonstrated on the European Commission's Digital Fairness Act (DFA) public call for evidence as a case study. The system processes raw PDF attachments and web-form responses, extracts topic annotations, and grounds every extraction in a verbatim quote from the source text. Applied to 4,322 DFA submissions, the pipeline produced 15,368 topic annotations supported by 20,951 verbatim evidence quotes. Three principles govern the proposed design: verbatim grounding, full traceability, and transparency by design. The dashboard exposes the full extraction dataset through five analytical views, from dataset-level topic overviews to individual paragraph drill-downs, with every result traceable to its source. Beyond the predefined DFA topic categories, the pipeline generated certain stakeholder concerns, such as Age Verification, Payment Processor Censorship, and Digital Ownership, that a fixed-taxonomy approach would have missed. The pipeline is domain-generic; adapting it to a new consultation requires only a prompt update and a new dataset. A live demo is available at https://dfa-dashboard.thalesbertaglia.com/. The code and processed data are publicly available at https://github.com/thalesbertaglia/dfa-dashboard.
Computational Studies in Influencer Marketing: A Systematic Literature Review
Jun 17, 2025Influencer marketing has become a crucial feature of digital marketing strategies. Despite its rapid growth and algorithmic relevance, the field of computational studies in influencer marketing remains fragmented, especially with limited systematic reviews covering the computational methodologies employed. This makes overarching scientific measurements in the influencer economy very scarce, to the detriment of interested stakeholders outside of platforms themselves, such as regulators, but also researchers from other fields. This paper aims to provide an overview of the state of the art of computational studies in influencer marketing by conducting a systematic literature review (SLR) based on the PRISMA model. The paper analyses 69 studies to identify key research themes, methodologies, and future directions in this research field. The review identifies four major research themes: Influencer identification and characterisation, Advertising strategies and engagement, Sponsored content analysis and discovery, and Fairness. Methodologically, the studies are categorised into machine learning-based techniques (e.g., classification, clustering) and non-machine-learning-based techniques (e.g., statistical analysis, network analysis). Key findings reveal a strong focus on optimising commercial outcomes, with limited attention to regulatory compliance and ethical considerations. The review highlights the need for more nuanced computational research that incorporates contextual factors such as language, platform, and industry type, as well as improved model explainability and dataset reproducibility. The paper concludes by proposing a multidisciplinary research agenda that emphasises the need for further links to regulation and compliance technology, finer granularity in analysis, and the development of standardised datasets.
The Monetisation of Toxicity: Analysing YouTube Content Creators and Controversy-Driven Engagement
Aug 01, 2024
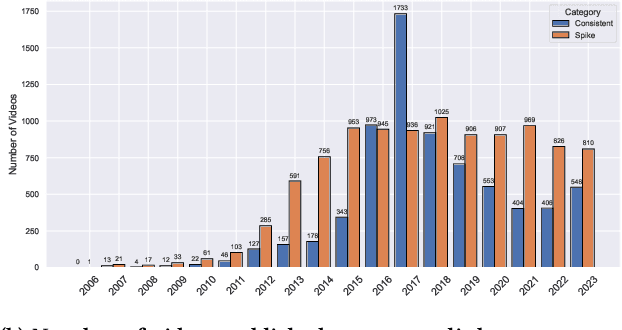
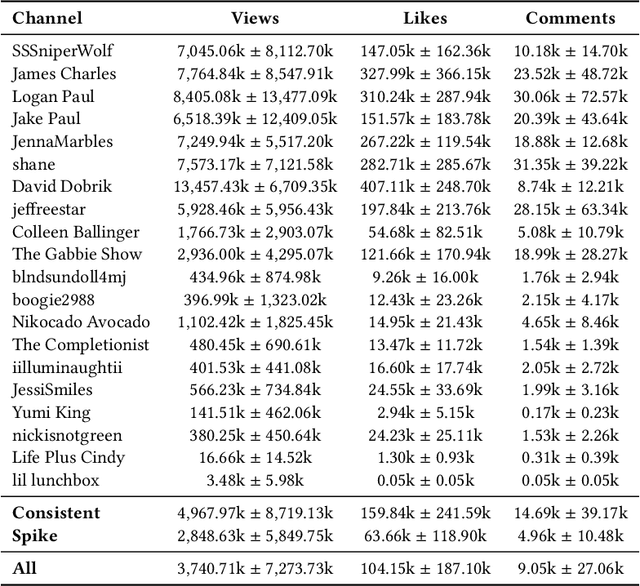
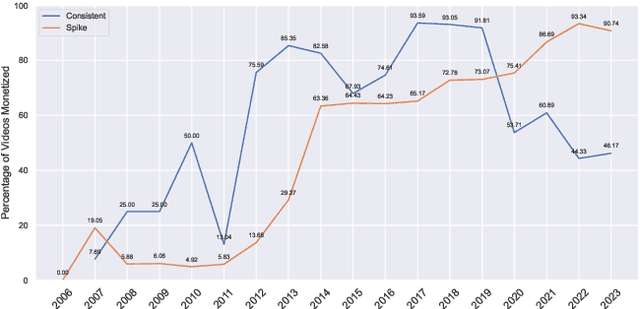
YouTube is a major social media platform that plays a significant role in digital culture, with content creators at its core. These creators often engage in controversial behaviour to drive engagement, which can foster toxicity. This paper presents a quantitative analysis of controversial content on YouTube, focusing on the relationship between controversy, toxicity, and monetisation. We introduce a curated dataset comprising 20 controversial YouTube channels extracted from Reddit discussions, including 16,349 videos and more than 105 million comments. We identify and categorise monetisation cues from video descriptions into various models, including affiliate marketing and direct selling, using lists of URLs and keywords. Additionally, we train a machine learning model to measure the toxicity of comments in these videos. Our findings reveal that while toxic comments correlate with higher engagement, they negatively impact monetisation, indicating that controversy-driven interaction does not necessarily lead to financial gain. We also observed significant variation in monetisation strategies, with some creators showing extensive monetisation despite high toxicity levels. Our study introduces a curated dataset, lists of URLs and keywords to categorise monetisation, a machine learning model to measure toxicity, and is a significant step towards understanding the complex relationship between controversy, engagement, and monetisation on YouTube. The lists used for detecting and categorising monetisation cues are available on https://github.com/thalesbertaglia/toxmon.
Across Platforms and Languages: Dutch Influencers and Legal Disclosures on Instagram, YouTube and TikTok
Jul 17, 2024

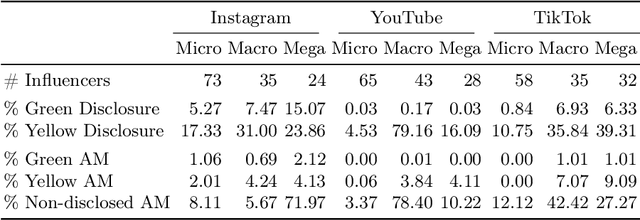
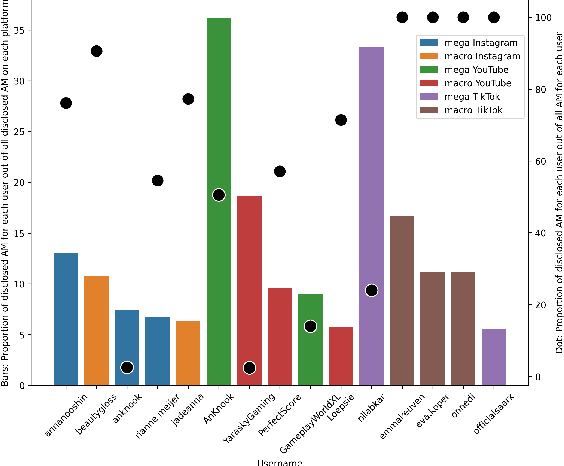
Content monetization on social media fuels a growing influencer economy. Influencer marketing remains largely undisclosed or inappropriately disclosed on social media. Non-disclosure issues have become a priority for national and supranational authorities worldwide, who are starting to impose increasingly harsher sanctions on them. This paper proposes a transparent methodology for measuring whether and how influencers comply with disclosures based on legal standards. We introduce a novel distinction between disclosures that are legally sufficient (green) and legally insufficient (yellow). We apply this methodology to an original dataset reflecting the content of 150 Dutch influencers publicly registered with the Dutch Media Authority based on recently introduced registration obligations. The dataset consists of 292,315 posts and is multi-language (English and Dutch) and cross-platform (Instagram, YouTube and TikTok). We find that influencer marketing remains generally underdisclosed on social media, and that bigger influencers are not necessarily more compliant with disclosure standards.
Regulation and NLP (RegNLP): Taming Large Language Models
Oct 09, 2023
The scientific innovation in Natural Language Processing (NLP) and more broadly in artificial intelligence (AI) is at its fastest pace to date. As large language models (LLMs) unleash a new era of automation, important debates emerge regarding the benefits and risks of their development, deployment and use. Currently, these debates have been dominated by often polarized narratives mainly led by the AI Safety and AI Ethics movements. This polarization, often amplified by social media, is swaying political agendas on AI regulation and governance and posing issues of regulatory capture. Capture occurs when the regulator advances the interests of the industry it is supposed to regulate, or of special interest groups rather than pursuing the general public interest. Meanwhile in NLP research, attention has been increasingly paid to the discussion of regulating risks and harms. This often happens without systematic methodologies or sufficient rooting in the disciplines that inspire an extended scope of NLP research, jeopardizing the scientific integrity of these endeavors. Regulation studies are a rich source of knowledge on how to systematically deal with risk and uncertainty, as well as with scientific evidence, to evaluate and compare regulatory options. This resource has largely remained untapped so far. In this paper, we argue how NLP research on these topics can benefit from proximity to regulatory studies and adjacent fields. We do so by discussing basic tenets of regulation, and risk and uncertainty, and by highlighting the shortcomings of current NLP discussions dealing with risk assessment. Finally, we advocate for the development of a new multidisciplinary research space on regulation and NLP (RegNLP), focused on connecting scientific knowledge to regulatory processes based on systematic methodologies.
A Multimodal Analysis of Influencer Content on Twitter
Sep 06, 2023



Influencer marketing involves a wide range of strategies in which brands collaborate with popular content creators (i.e., influencers) to leverage their reach, trust, and impact on their audience to promote and endorse products or services. Because followers of influencers are more likely to buy a product after receiving an authentic product endorsement rather than an explicit direct product promotion, the line between personal opinions and commercial content promotion is frequently blurred. This makes automatic detection of regulatory compliance breaches related to influencer advertising (e.g., misleading advertising or hidden sponsorships) particularly difficult. In this work, we (1) introduce a new Twitter (now X) dataset consisting of 15,998 influencer posts mapped into commercial and non-commercial categories for assisting in the automatic detection of commercial influencer content; (2) experiment with an extensive set of predictive models that combine text and visual information showing that our proposed cross-attention approach outperforms state-of-the-art multimodal models; and (3) conduct a thorough analysis of strengths and limitations of our models. We show that multimodal modeling is useful for identifying commercial posts, reducing the amount of false positives, and capturing relevant context that aids in the discovery of undisclosed commercial posts.
Closing the Loop: Testing ChatGPT to Generate Model Explanations to Improve Human Labelling of Sponsored Content on Social Media
Jun 08, 2023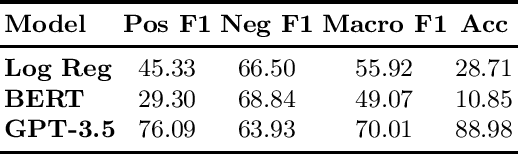
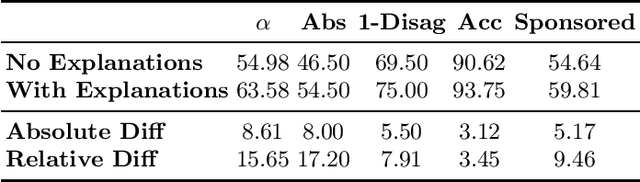
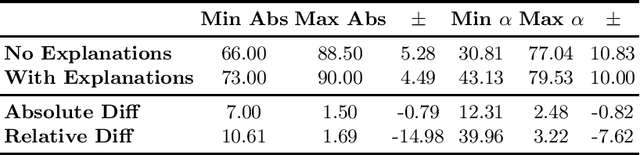
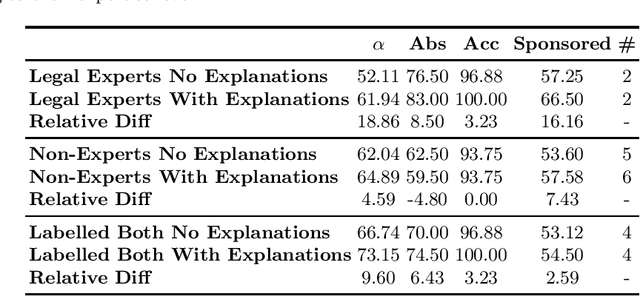
Regulatory bodies worldwide are intensifying their efforts to ensure transparency in influencer marketing on social media through instruments like the Unfair Commercial Practices Directive (UCPD) in the European Union, or Section 5 of the Federal Trade Commission Act. Yet enforcing these obligations has proven to be highly problematic due to the sheer scale of the influencer market. The task of automatically detecting sponsored content aims to enable the monitoring and enforcement of such regulations at scale. Current research in this field primarily frames this problem as a machine learning task, focusing on developing models that achieve high classification performance in detecting ads. These machine learning tasks rely on human data annotation to provide ground truth information. However, agreement between annotators is often low, leading to inconsistent labels that hinder the reliability of models. To improve annotation accuracy and, thus, the detection of sponsored content, we propose using chatGPT to augment the annotation process with phrases identified as relevant features and brief explanations. Our experiments show that this approach consistently improves inter-annotator agreement and annotation accuracy. Additionally, our survey of user experience in the annotation task indicates that the explanations improve the annotators' confidence and streamline the process. Our proposed methods can ultimately lead to more transparency and alignment with regulatory requirements in sponsored content detection.
LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development
May 22, 2023



In this work, we conduct a detailed analysis on the performance of legal-oriented pre-trained language models (PLMs). We examine the interplay between their original objective, acquired knowledge, and legal language understanding capacities which we define as the upstream, probing, and downstream performance, respectively. We consider not only the models' size but also the pre-training corpora used as important dimensions in our study. To this end, we release a multinational English legal corpus (LeXFiles) and a legal knowledge probing benchmark (LegalLAMA) to facilitate training and detailed analysis of legal-oriented PLMs. We release two new legal PLMs trained on LeXFiles and evaluate them alongside others on LegalLAMA and LexGLUE. We find that probing performance strongly correlates with upstream performance in related legal topics. On the other hand, downstream performance is mainly driven by the model's size and prior legal knowledge which can be estimated by upstream and probing performance. Based on these findings, we can conclude that both dimensions are important for those seeking the development of domain-specific PLMs.
The Case for a Legal Compliance API for the Enforcement of the EU's Digital Services Act on Social Media Platforms
May 13, 2022In the course of under a year, the European Commission has launched some of the most important regulatory proposals to date on platform governance. The Commission's goals behind cross-sectoral regulation of this sort include the protection of markets and democracies alike. While all these acts propose sophisticated rules for setting up new enforcement institutions and procedures, one aspect remains highly unclear: how digital enforcement will actually take place in practice. Focusing on the Digital Services Act (DSA), this discussion paper critically addresses issues around social media data access for the purpose of digital enforcement and proposes the use of a legal compliance application programming interface (API) as a means to facilitate compliance with the DSA and complementary European and national regulation. To contextualize this discussion, the paper pursues two scenarios that exemplify the harms arising out of content monetization affecting a particularly vulnerable category of social media users: children. The two scenarios are used to further reflect upon essential issues surrounding data access and legal compliance with the DSA and further applicable legal standards in the field of labour and consumer law.