 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Alignment: A Critical Survey of LLM Development Initiatives through Value-setting and Data-centric Lens
Aug 23, 2025AI Alignment, primarily in the form of Reinforcement Learning from Human Feedback (RLHF), has been a cornerstone of the post-training phase in developing Large Language Models (LLMs). It has also been a popular research topic across various disciplines beyond Computer Science, including Philosophy and Law, among others, highlighting the socio-technical challenges involved. Nonetheless, except for the computational techniques related to alignment, there has been limited focus on the broader picture: the scope of these processes, which primarily rely on the selected objectives (values), and the data collected and used to imprint such objectives into the models. This work aims to reveal how alignment is understood and applied in practice from a value-setting and data-centric perspective. For this purpose, we investigate and survey (`audit') publicly available documentation released by 6 LLM development initiatives by 5 leading organizations shaping this technology, focusing on proprietary (OpenAI's GPT, Anthropic's Claude, Google's Gemini) and open-weight (Meta's Llama, Google's Gemma, and Alibaba's Qwen) initiatives, all published in the last 3 years. The findings are documented in detail per initiative, while there is also an overall summary concerning different aspects, mainly from a value-setting and data-centric perspective. On the basis of our findings, we discuss a series of broader related concerns.
Breaking the Manual Annotation Bottleneck: Creating a Comprehensive Legal Case Criticality Dataset through Semi-Automated Labeling
Oct 17, 2024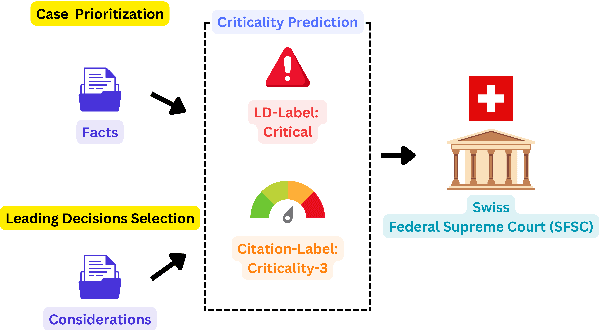

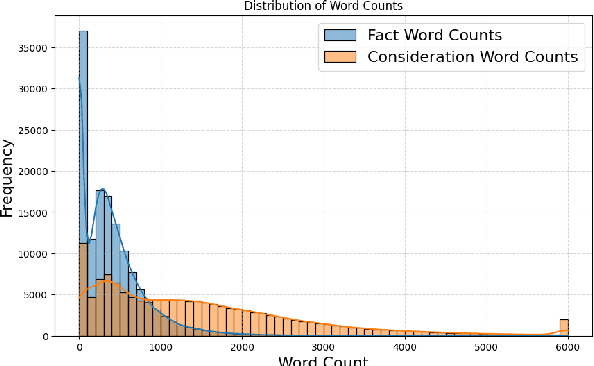
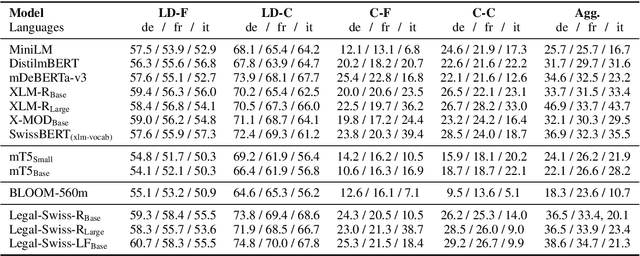
Predicting case criticality helps legal professionals in the court system manage large volumes of case law. This paper introduces the Criticality Prediction dataset, a new resource for evaluating the potential influence of Swiss Federal Supreme Court decisions on future jurisprudence. Unlike existing approaches that rely on resource-intensive manual annotations, we semi-automatically derive labels leading to a much larger dataset than otherwise possible. Our dataset features a two-tier labeling system: (1) the LD-Label, which identifies cases published as Leading Decisions (LD), and (2) the Citation-Label, which ranks cases by their citation frequency and recency. This allows for a more nuanced evaluation of case importance. We evaluate several multilingual models, including fine-tuned variants and large language models, and find that fine-tuned models consistently outperform zero-shot baselines, demonstrating the need for task-specific adaptation. Our contributions include the introduction of this task and the release of a multilingual dataset to the research community.
Investigating LLMs as Voting Assistants via Contextual Augmentation: A Case Study on the European Parliament Elections 2024
Jul 11, 2024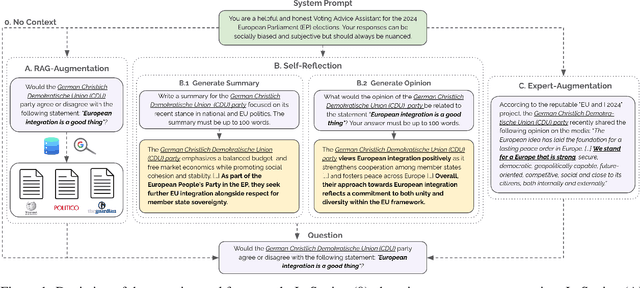
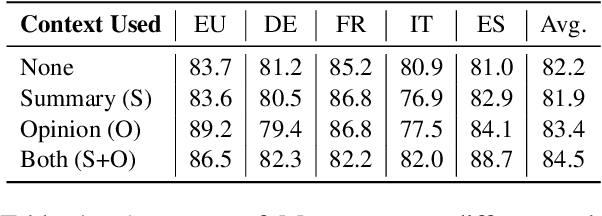

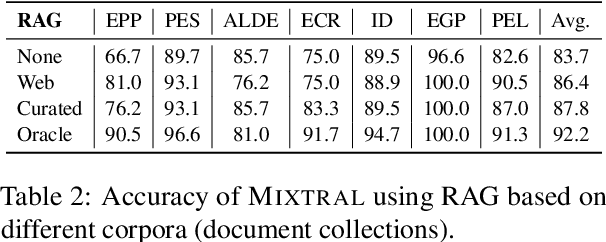
Instruction-finetuned Large Language Models exhibit unprecedented Natural Language Understanding capabilities. Recent work has been exploring political biases and political reasoning capabilities in LLMs, mainly scoped in the US context. In light of the recent 2024 European Parliament elections, we are investigating if LLMs can be used as Voting Advice Applications (VAAs). We audit MISTRAL and MIXTRAL models and evaluate their accuracy in predicting the stance of political parties based on the latest "EU and I" voting assistance questionnaire. Furthermore, we explore alternatives to improve models' performance by augmenting the input context via Retrieval-Augmented Generation (RAG) relying on web search, and Self-Reflection using staged conversations that aim to re-collect relevant content from the model's internal memory. We find that MIXTRAL is highly accurate with an 82% accuracy on average. Augmenting the input context with expert-curated information can lead to a significant boost of approx. 9%, which remains an open challenge for automated approaches.
Llama meets EU: Investigating the European Political Spectrum through the Lens of LLMs
Mar 22, 2024Instruction-finetuned Large Language Models inherit clear political leanings that have been shown to influence downstream task performance. We expand this line of research beyond the two-party system in the US and audit Llama Chat in the context of EU politics in various settings to analyze the model's political knowledge and its ability to reason in context. We adapt, i.e., further fine-tune, Llama Chat on speeches of individual euro-parties from debates in the European Parliament to reevaluate its political leaning based on the EUandI questionnaire. Llama Chat shows considerable knowledge of national parties' positions and is capable of reasoning in context. The adapted, party-specific, models are substantially re-aligned towards respective positions which we see as a starting point for using chat-based LLMs as data-driven conversational engines to assist research in political science.
On the Interplay between Fairness and Explainability
Oct 25, 2023



In order to build reliable and trustworthy NLP applications, models need to be both fair across different demographics and explainable. Usually these two objectives, fairness and explainability, are optimized and/or examined independently of each other. Instead, we argue that forthcoming, trustworthy NLP systems should consider both. In this work, we perform a first study to understand how they influence each other: do fair(er) models rely on more plausible rationales? and vice versa. To this end, we conduct experiments on two English multi-class text classification datasets, BIOS and ECtHR, that provide information on gender and nationality, respectively, as well as human-annotated rationales. We fine-tune pre-trained language models with several methods for (i) bias mitigation, which aims to improve fairness; (ii) rationale extraction, which aims to produce plausible explanations. We find that bias mitigation algorithms do not always lead to fairer models. Moreover, we discover that empirical fairness and explainability are orthogonal.
Rather a Nurse than a Physician -- Contrastive Explanations under Investigation
Oct 18, 2023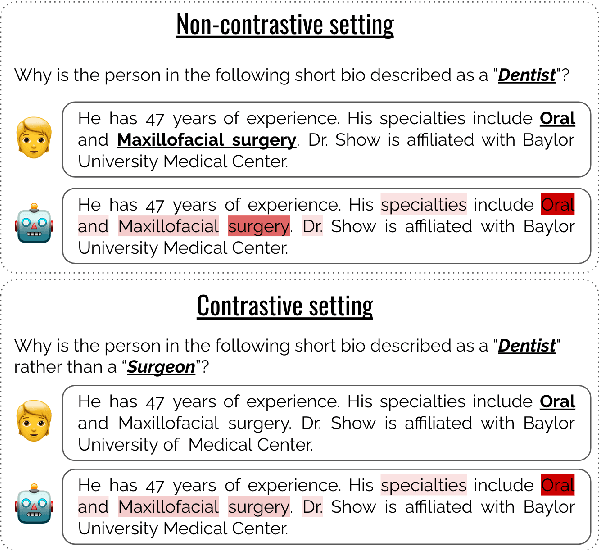
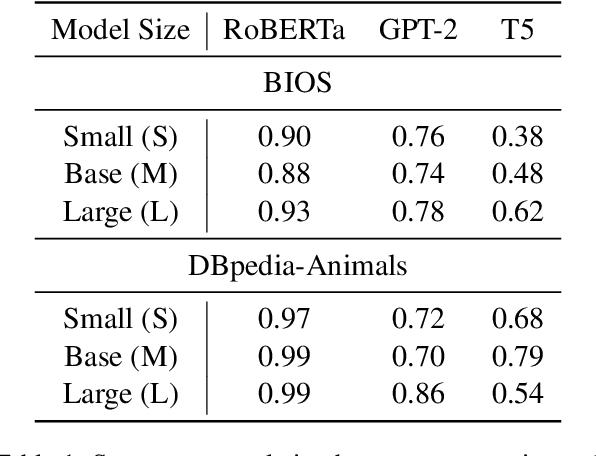

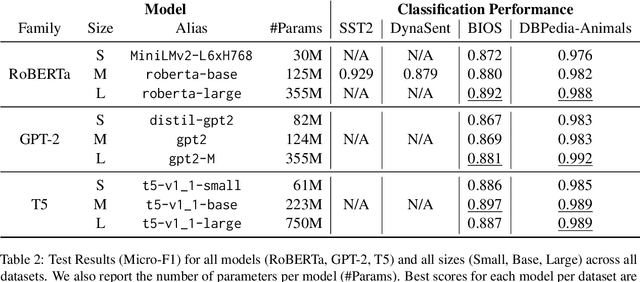
Contrastive explanations, where one decision is explained in contrast to another, are supposed to be closer to how humans explain a decision than non-contrastive explanations, where the decision is not necessarily referenced to an alternative. This claim has never been empirically validated. We analyze four English text-classification datasets (SST2, DynaSent, BIOS and DBpedia-Animals). We fine-tune and extract explanations from three different models (RoBERTa, GTP-2, and T5), each in three different sizes and apply three post-hoc explainability methods (LRP, GradientxInput, GradNorm). We furthermore collect and release human rationale annotations for a subset of 100 samples from the BIOS dataset for contrastive and non-contrastive settings. A cross-comparison between model-based rationales and human annotations, both in contrastive and non-contrastive settings, yields a high agreement between the two settings for models as well as for humans. Moreover, model-based explanations computed in both settings align equally well with human rationales. Thus, we empirically find that humans do not necessarily explain in a contrastive manner.9 pages, long paper at ACL 2022 proceedings.
Regulation and NLP (RegNLP): Taming Large Language Models
Oct 09, 2023
The scientific innovation in Natural Language Processing (NLP) and more broadly in artificial intelligence (AI) is at its fastest pace to date. As large language models (LLMs) unleash a new era of automation, important debates emerge regarding the benefits and risks of their development, deployment and use. Currently, these debates have been dominated by often polarized narratives mainly led by the AI Safety and AI Ethics movements. This polarization, often amplified by social media, is swaying political agendas on AI regulation and governance and posing issues of regulatory capture. Capture occurs when the regulator advances the interests of the industry it is supposed to regulate, or of special interest groups rather than pursuing the general public interest. Meanwhile in NLP research, attention has been increasingly paid to the discussion of regulating risks and harms. This often happens without systematic methodologies or sufficient rooting in the disciplines that inspire an extended scope of NLP research, jeopardizing the scientific integrity of these endeavors. Regulation studies are a rich source of knowledge on how to systematically deal with risk and uncertainty, as well as with scientific evidence, to evaluate and compare regulatory options. This resource has largely remained untapped so far. In this paper, we argue how NLP research on these topics can benefit from proximity to regulatory studies and adjacent fields. We do so by discussing basic tenets of regulation, and risk and uncertainty, and by highlighting the shortcomings of current NLP discussions dealing with risk assessment. Finally, we advocate for the development of a new multidisciplinary research space on regulation and NLP (RegNLP), focused on connecting scientific knowledge to regulatory processes based on systematic methodologies.
SCALE: Scaling up the Complexity for Advanced Language Model Evaluation
Jun 15, 2023



Recent strides in Large Language Models (LLMs) have saturated many NLP benchmarks (even professional domain-specific ones), emphasizing the need for novel, more challenging novel ones to properly assess LLM capabilities. In this paper, we introduce a novel NLP benchmark that poses challenges to current LLMs across four key dimensions: processing long documents (up to 50K tokens), utilizing domain specific knowledge (embodied in legal texts), multilingual understanding (covering five languages), and multitasking (comprising legal document to document Information Retrieval, Court View Generation, Leading Decision Summarization, Citation Extraction, and eight challenging Text Classification tasks). Our benchmark comprises diverse legal NLP datasets from the Swiss legal system, allowing for a comprehensive study of the underlying Non-English, inherently multilingual, federal legal system. Despite recent advances, efficiently processing long documents for intense review/analysis tasks remains an open challenge for language models. Also, comprehensive, domain-specific benchmarks requiring high expertise to develop are rare, as are multilingual benchmarks. This scarcity underscores our contribution's value, considering most public models are trained predominantly on English corpora, while other languages remain understudied, particularly for practical domain-specific NLP tasks. Our benchmark allows for testing and advancing the state-of-the-art LLMs. As part of our study, we evaluate several pre-trained multilingual language models on our benchmark to establish strong baselines as a point of reference. Despite the large size of our datasets (tens to hundreds of thousands of examples), existing publicly available models struggle with most tasks, even after in-domain pretraining. We publish all resources (benchmark suite, pre-trained models, code) under a fully permissive open CC BY-SA license.
MultiLegalPile: A 689GB Multilingual Legal Corpus
Jun 06, 2023



Large, high-quality datasets are crucial for training Large Language Models (LLMs). However, so far, there are few datasets available for specialized critical domains such as law and the available ones are often only for the English language. We curate and release MultiLegalPile, a 689GB corpus in 24 languages from 17 jurisdictions. The MultiLegalPile corpus, which includes diverse legal data sources with varying licenses, allows for pretraining NLP models under fair use, with more permissive licenses for the Eurlex Resources and Legal mC4 subsets. We pretrain two RoBERTa models and one Longformer multilingually, and 24 monolingual models on each of the language-specific subsets and evaluate them on LEXTREME. Additionally, we evaluate the English and multilingual models on LexGLUE. Our multilingual models set a new SotA on LEXTREME and our English models on LexGLUE. We release the dataset, the trained models, and all of the code under the most open possible licenses.
PokemonChat: Auditing ChatGPT for Pokémon Universe Knowledge
Jun 05, 2023The recently released ChatGPT model demonstrates unprecedented capabilities in zero-shot question-answering. In this work, we probe ChatGPT for its conversational understanding and introduce a conversational framework (protocol) that can be adopted in future studies. The Pok\'emon universe serves as an ideal testing ground for auditing ChatGPT's reasoning capabilities due to its closed world assumption. After bringing ChatGPT's background knowledge (on the Pok\'emon universe) to light, we test its reasoning process when using these concepts in battle scenarios. We then evaluate its ability to acquire new knowledge and include it in its reasoning process. Our ultimate goal is to assess ChatGPT's ability to generalize, combine features, and to acquire and reason over newly introduced knowledge from human feedback. We find that ChatGPT has prior knowledge of the Pokemon universe, which can reason upon in battle scenarios to a great extent, even when new information is introduced. The model performs better with collaborative feedback and if there is an initial phase of information retrieval, but also hallucinates occasionally and is susceptible to adversarial attacks.