 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Manual Annotation Bottleneck: Creating a Comprehensive Legal Case Criticality Dataset through Semi-Automated Labeling
Paper and Code
Oct 17, 2024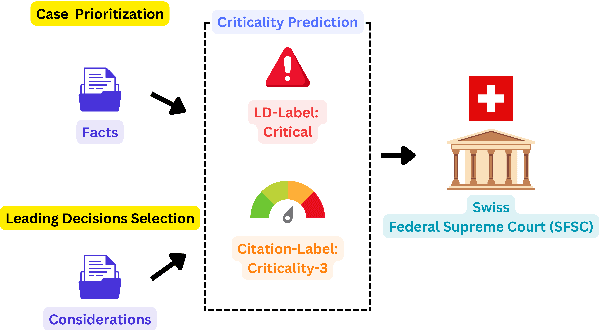

Predicting case criticality helps legal professionals in the court system manage large volumes of case law. This paper introduces the Criticality Prediction dataset, a new resource for evaluating the potential influence of Swiss Federal Supreme Court decisions on future jurisprudence. Unlike existing approaches that rely on resource-intensive manual annotations, we semi-automatically derive labels leading to a much larger dataset than otherwise possible. Our dataset features a two-tier labeling system: (1) the LD-Label, which identifies cases published as Leading Decisions (LD), and (2) the Citation-Label, which ranks cases by their citation frequency and recency. This allows for a more nuanced evaluation of case importance. We evaluate several multilingual models, including fine-tuned variants and large language models, and find that fine-tuned models consistently outperform zero-shot baselines, demonstrating the need for task-specific adaptation. Our contributions include the introduction of this task and the release of a multilingual dataset to the research community.