 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can We Synthesize High-Quality Pretraining Data? A Systematic Study of Prompt Design, Generator Model, and Source Data
Apr 15, 2026Synthetic data is a standard component in training large language models, yet systematic comparisons across design dimensions, including rephrasing strategy, generator model, and source data, remain absent. We conduct extensive controlled experiments, generating over one trillion tokens, to identify critical factors in rephrasing web text into synthetic pretraining data. Our results reveal that structured output formats, such as tables, math problems, FAQs, and tutorials, consistently outperform both curated web baselines and prior synthetic methods. Notably, increasing the size of the generator model beyond 1B parameters provides no additional benefit. Our analysis also demonstrates that the selection of the original data used for mixing substantially influences performance. By applying our findings, we develop \textbf{\textsc{FinePhrase}}, a 486-billion-token open dataset of rephrased web text. We show that \textsc{FinePhrase} outperforms all existing synthetic data baselines while reducing generation costs by up to 30 times. We provide the dataset, all prompts, and the generation framework to the research community.
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025



Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
LEXam: Benchmarking Legal Reasoning on 340 Law Exams
May 19, 2025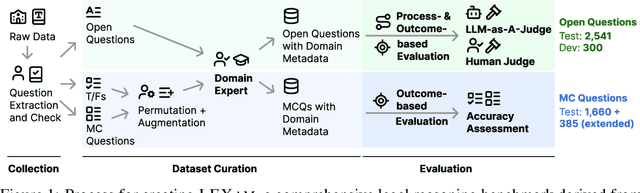
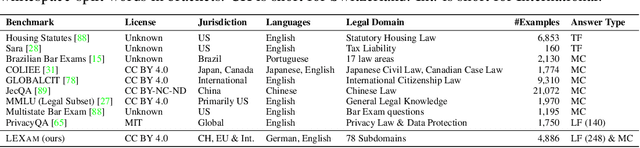
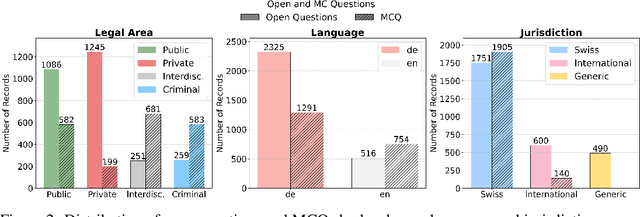
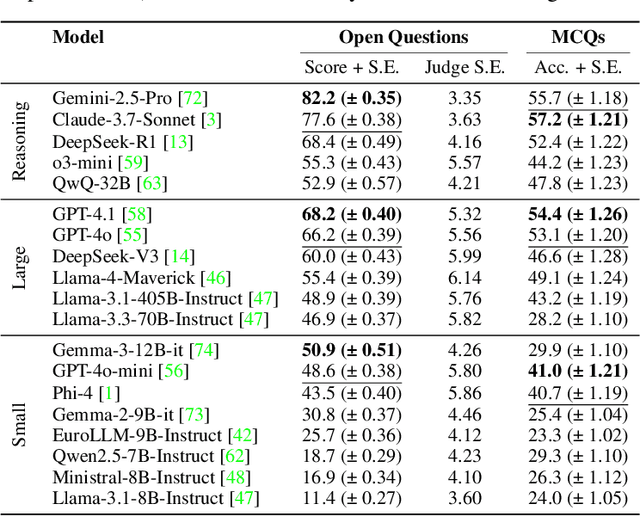
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
SwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Breaking the Manual Annotation Bottleneck: Creating a Comprehensive Legal Case Criticality Dataset through Semi-Automated Labeling
Oct 17, 2024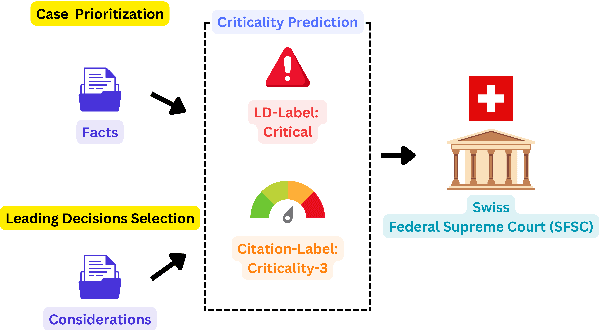

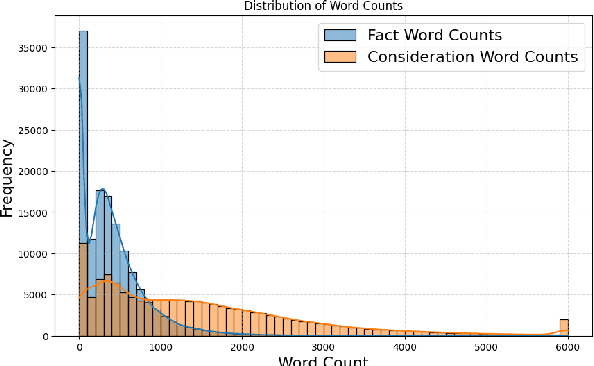
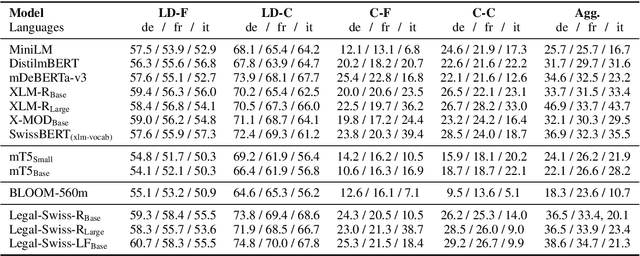
Predicting case criticality helps legal professionals in the court system manage large volumes of case law. This paper introduces the Criticality Prediction dataset, a new resource for evaluating the potential influence of Swiss Federal Supreme Court decisions on future jurisprudence. Unlike existing approaches that rely on resource-intensive manual annotations, we semi-automatically derive labels leading to a much larger dataset than otherwise possible. Our dataset features a two-tier labeling system: (1) the LD-Label, which identifies cases published as Leading Decisions (LD), and (2) the Citation-Label, which ranks cases by their citation frequency and recency. This allows for a more nuanced evaluation of case importance. We evaluate several multilingual models, including fine-tuned variants and large language models, and find that fine-tuned models consistently outperform zero-shot baselines, demonstrating the need for task-specific adaptation. Our contributions include the introduction of this task and the release of a multilingual dataset to the research community.
Unlocking Legal Knowledge: A Multilingual Dataset for Judicial Summarization in Switzerland
Oct 17, 2024



Legal research is a time-consuming task that most lawyers face on a daily basis. A large part of legal research entails looking up relevant caselaw and bringing it in relation to the case at hand. Lawyers heavily rely on summaries (also called headnotes) to find the right cases quickly. However, not all decisions are annotated with headnotes and writing them is time-consuming. Automated headnote creation has the potential to make hundreds of thousands of decisions more accessible for legal research in Switzerland alone. To kickstart this, we introduce the Swiss Leading Decision Summarization ( SLDS) dataset, a novel cross-lingual resource featuring 18K court rulings from the Swiss Federal Supreme Court (SFSC), in German, French, and Italian, along with German headnotes. We fine-tune and evaluate three mT5 variants, along with proprietary models. Our analysis highlights that while proprietary models perform well in zero-shot and one-shot settings, fine-tuned smaller models still provide a strong competitive edge. We publicly release the dataset to facilitate further research in multilingual legal summarization and the development of assistive technologies for legal professionals
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
Towards Explainability and Fairness in Swiss Judgement Prediction: Benchmarking on a Multilingual Dataset
Feb 26, 2024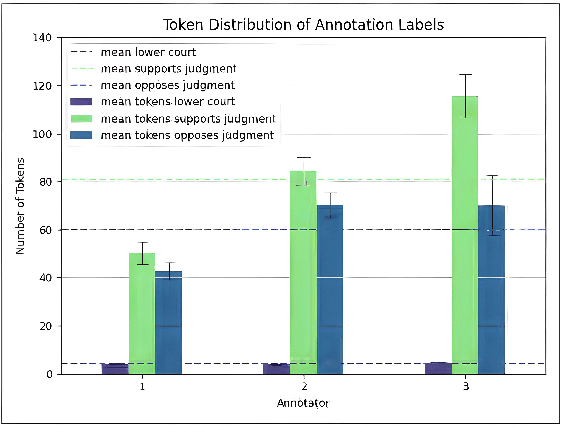
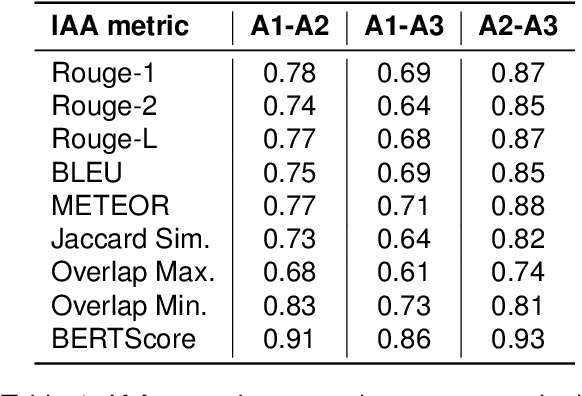
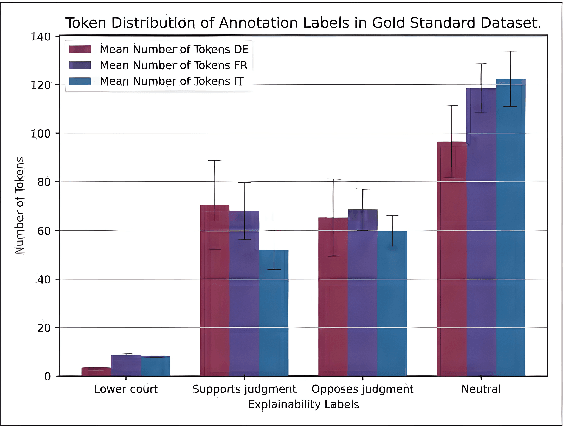
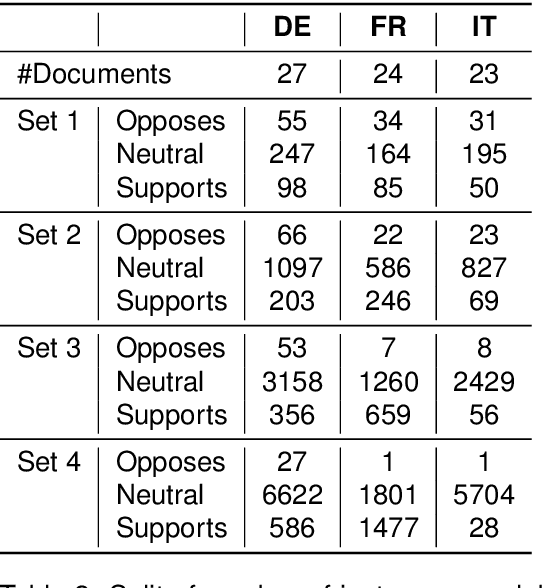
The assessment of explainability in Legal Judgement Prediction (LJP) systems is of paramount importance in building trustworthy and transparent systems, particularly considering the reliance of these systems on factors that may lack legal relevance or involve sensitive attributes. This study delves into the realm of explainability and fairness in LJP models, utilizing Swiss Judgement Prediction (SJP), the only available multilingual LJP dataset. We curate a comprehensive collection of rationales that `support' and `oppose' judgement from legal experts for 108 cases in German, French, and Italian. By employing an occlusion-based explainability approach, we evaluate the explainability performance of state-of-the-art monolingual and multilingual BERT-based LJP models, as well as models developed with techniques such as data augmentation and cross-lingual transfer, which demonstrated prediction performance improvement. Notably, our findings reveal that improved prediction performance does not necessarily correspond to enhanced explainability performance, underscoring the significance of evaluating models from an explainability perspective. Additionally, we introduce a novel evaluation framework, Lower Court Insertion (LCI), which allows us to quantify the influence of lower court information on model predictions, exposing current models' biases.
LegalLens: Leveraging LLMs for Legal Violation Identification in Unstructured Text
Feb 06, 2024In this study, we focus on two main tasks, the first for detecting legal violations within unstructured textual data, and the second for associating these violations with potentially affected individuals. We constructed two datasets using Large Language Models (LLMs) which were subsequently validated by domain expert annotators. Both tasks were designed specifically for the context of class-action cases. The experimental design incorporated fine-tuning models from the BERT family and open-source LLMs, and conducting few-shot experiments using closed-source LLMs. Our results, with an F1-score of 62.69\% (violation identification) and 81.02\% (associating victims), show that our datasets and setups can be used for both tasks. Finally, we publicly release the datasets and the code used for the experiments in order to advance further research in the area of legal natural language processing (NLP).