 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEXam: Benchmarking Legal Reasoning on 340 Law Exams
May 19, 2025
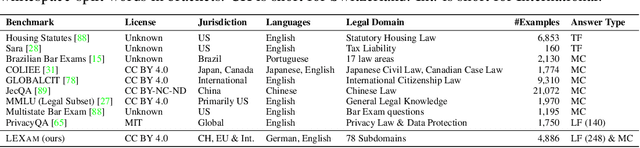
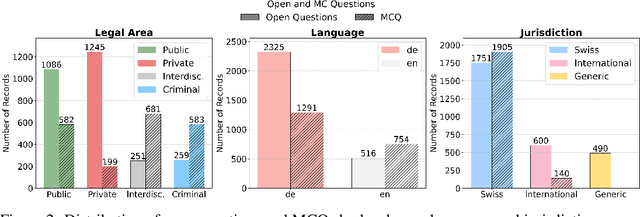
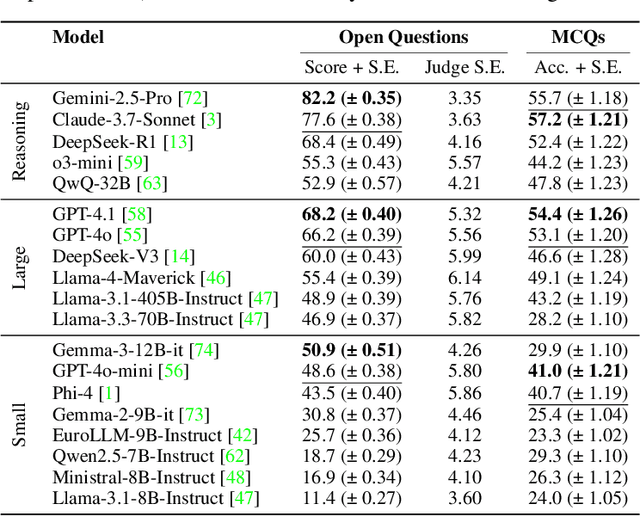
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
Limits of nonlinear and dispersive fiber propagation for photonic extreme learning
Mar 05, 2025We report a generalized nonlinear Schr\"odinger equation simulation model of an extreme learning machine based on optical fiber propagation. Using handwritten digit classification as a benchmark, we study how accuracy depends on propagation dynamics, as well as parameters governing spectral encoding, readout, and noise. Test accuracies of over 91% and 93% are found for propagation in the anomalous and normal dispersion regimes respectively. Our simulation results also suggest that quantum noise on the input pulses introduces an intrinsic penalty to ELM performance.
SwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
A spiking photonic neural network of 40.000 neurons, trained with rank-order coding for leveraging sparsity
Nov 28, 2024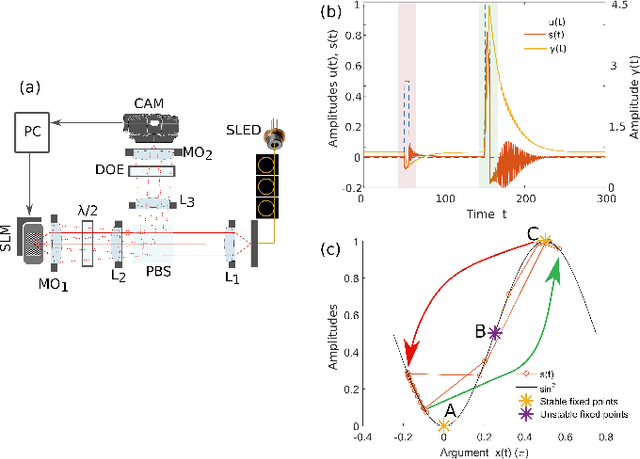
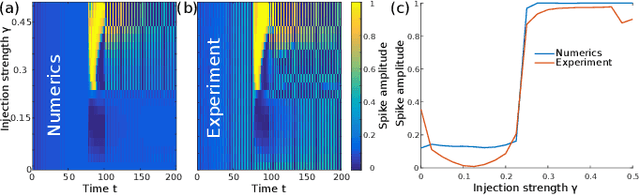
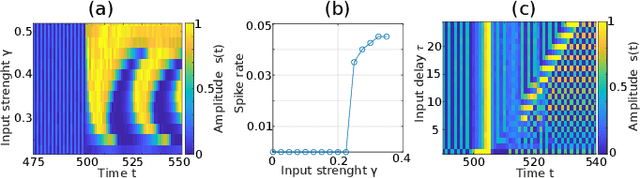
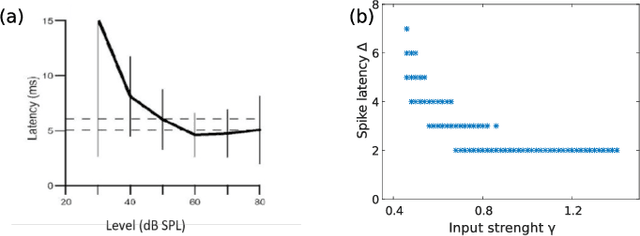
In recent years, the hardware implementation of neural networks, leveraging physical coupling and analog neurons has substantially increased in relevance. Such nonlinear and complex physical networks provide significant advantages in speed and energy efficiency, but are potentially susceptible to internal noise when compared to digital emulations of such networks. In this work, we consider how additive and multiplicative Gaussian white noise on the neuronal level can affect the accuracy of the network when applied for specific tasks and including a softmax function in the readout layer. We adapt several noise reduction techniques to the essential setting of classification tasks, which represent a large fraction of neural network computing. We find that these adjusted concepts are highly effective in mitigating the detrimental impact of noise.
Impact of white noise in artificial neural networks trained for classification: performance and noise mitigation strategies
Nov 07, 2024In recent years, the hardware implementation of neural networks, leveraging physical coupling and analog neurons has substantially increased in relevance. Such nonlinear and complex physical networks provide significant advantages in speed and energy efficiency, but are potentially susceptible to internal noise when compared to digital emulations of such networks. In this work, we consider how additive and multiplicative Gaussian white noise on the neuronal level can affect the accuracy of the network when applied for specific tasks and including a softmax function in the readout layer. We adapt several noise reduction techniques to the essential setting of classification tasks, which represent a large fraction of neural network computing. We find that these adjusted concepts are highly effective in mitigating the detrimental impact of noise.
Training of Physical Neural Networks
Jun 05, 2024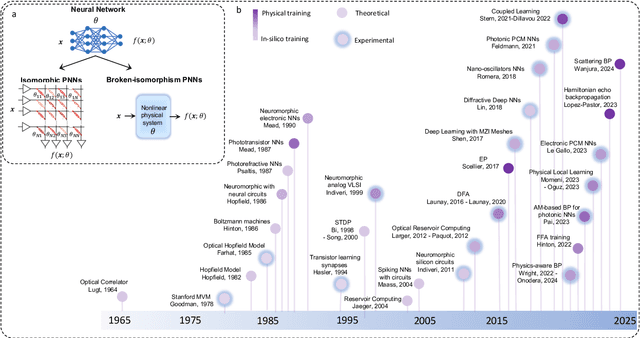
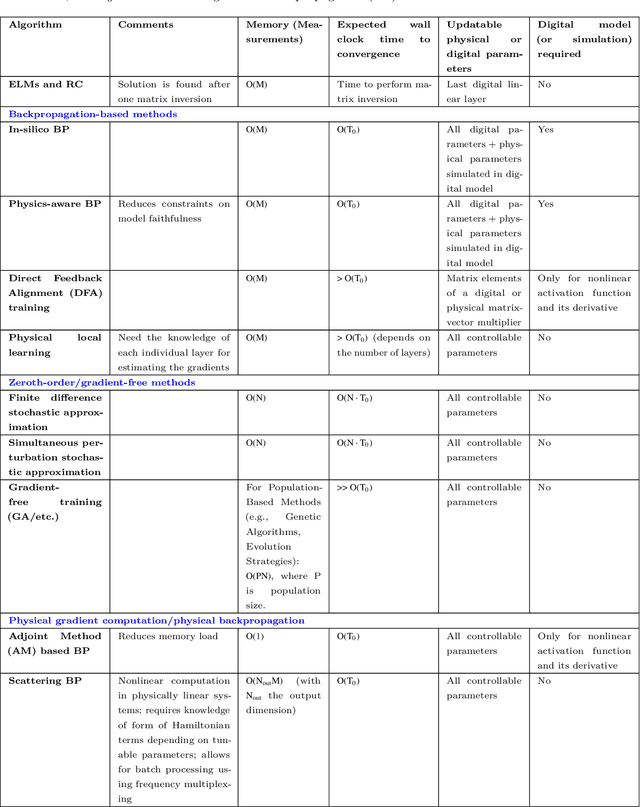
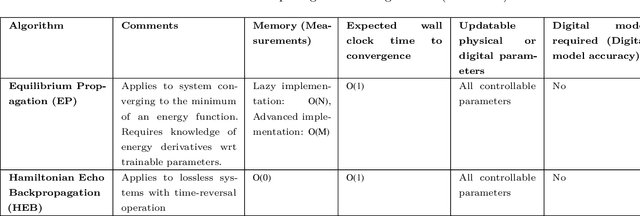
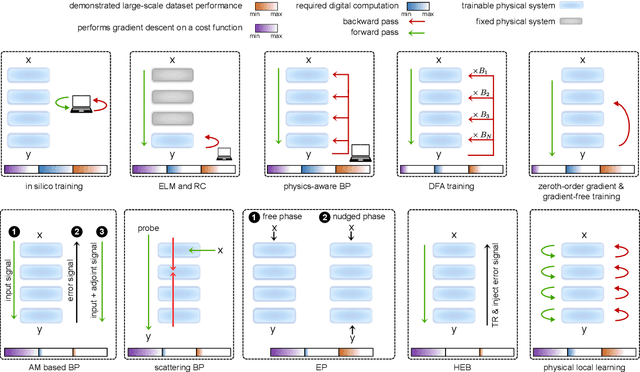
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Automatic Anonymization of Swiss Federal Supreme Court Rulings
Oct 07, 2023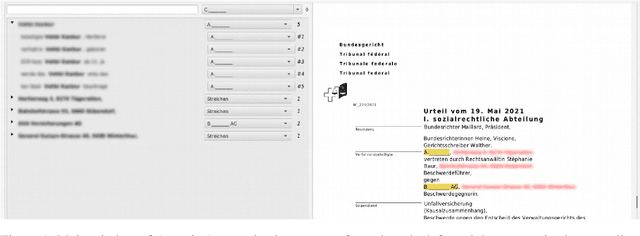
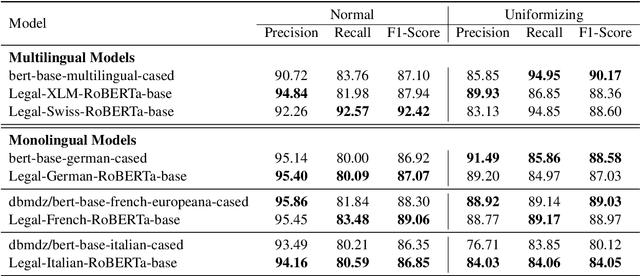
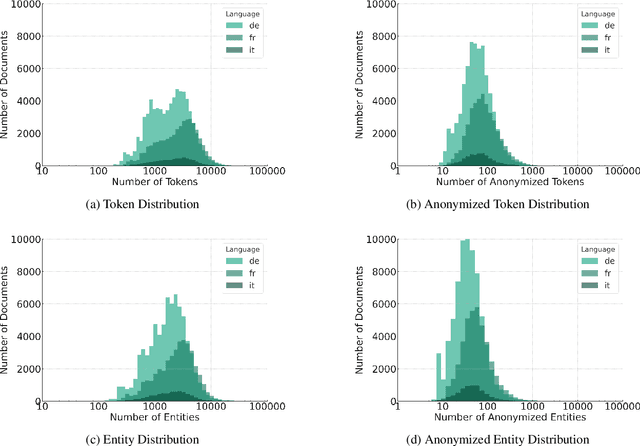
Releasing court decisions to the public relies on proper anonymization to protect all involved parties, where necessary. The Swiss Federal Supreme Court relies on an existing system that combines different traditional computational methods with human experts. In this work, we enhance the existing anonymization software using a large dataset annotated with entities to be anonymized. We compared BERT-based models with models pre-trained on in-domain data. Our results show that using in-domain data to pre-train the models further improves the F1-score by more than 5\% compared to existing models. Our work demonstrates that combining existing anonymization methods, such as regular expressions, with machine learning can further reduce manual labor and enhance automatic suggestions.
Convergence and scaling of Boolean-weight optimization for hardware reservoirs
May 13, 2023
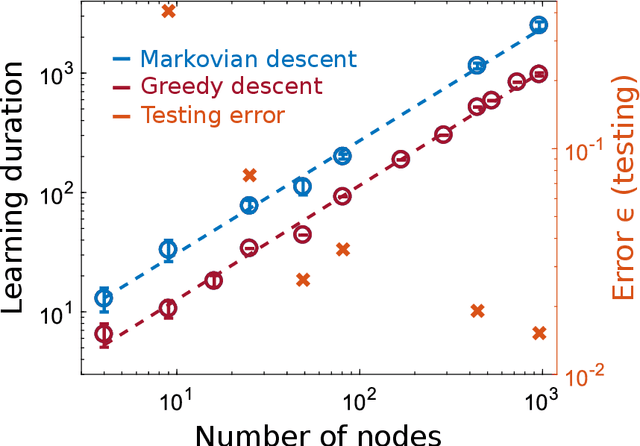
Hardware implementation of neural network are an essential step to implement next generation efficient and powerful artificial intelligence solutions. Besides the realization of a parallel, efficient and scalable hardware architecture, the optimization of the system's extremely large parameter space with sampling-efficient approaches is essential. Here, we analytically derive the scaling laws for highly efficient Coordinate Descent applied to optimizing the readout layer of a random recurrently connection neural network, a reservoir. We demonstrate that the convergence is exponential and scales linear with the network's number of neurons. Our results perfectly reproduce the convergence and scaling of a large-scale photonic reservoir implemented in a proof-of-concept experiment. Our work therefore provides a solid foundation for such optimization in hardware networks, and identifies future directions that are promising for optimizing convergence speed during learning leveraging measures of a neural network's amplitude statistics and the weight update rule.
Roadmap on Deep Learning for Microscopy
Mar 07, 2023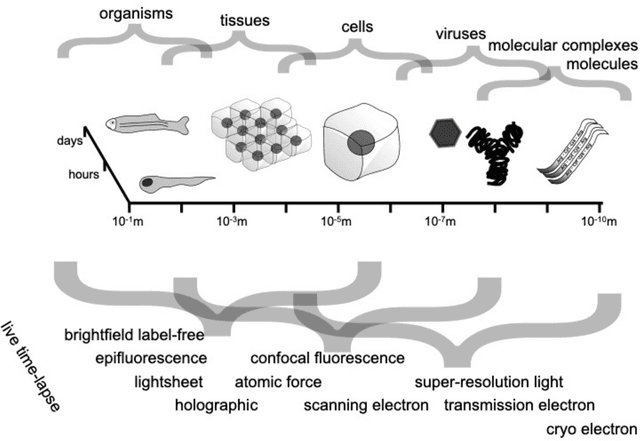
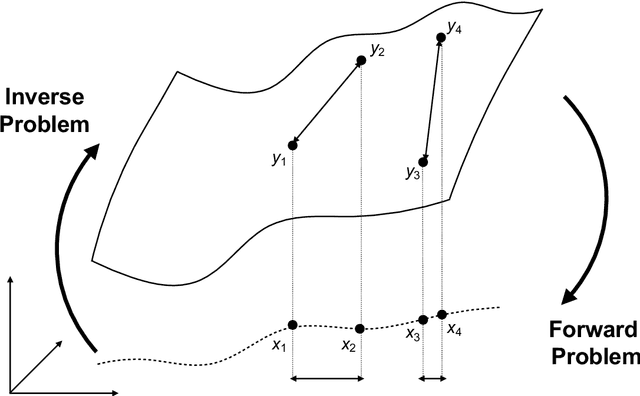
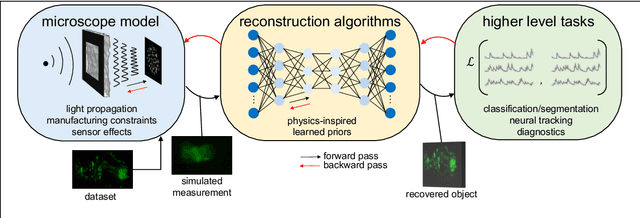
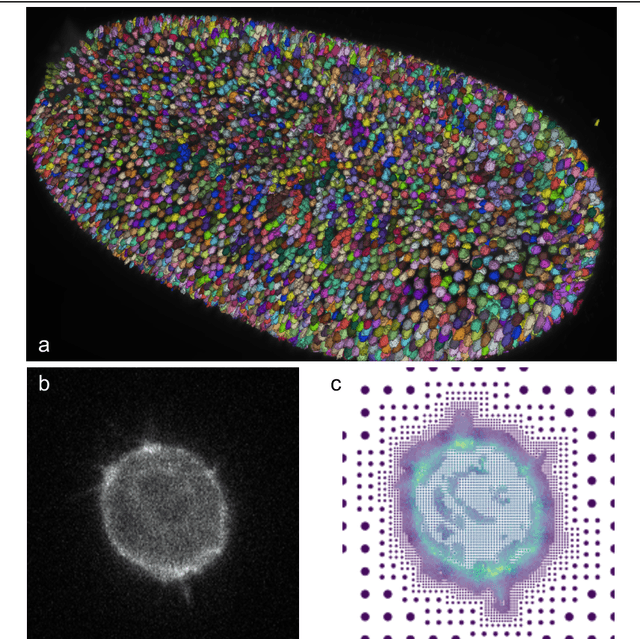
Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.
Noise mitigation strategies in physical feedforward neural networks
Apr 20, 2022
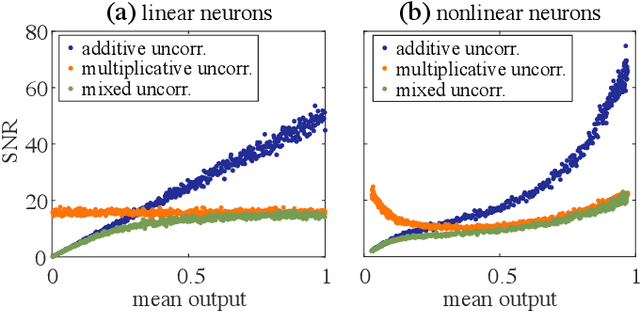
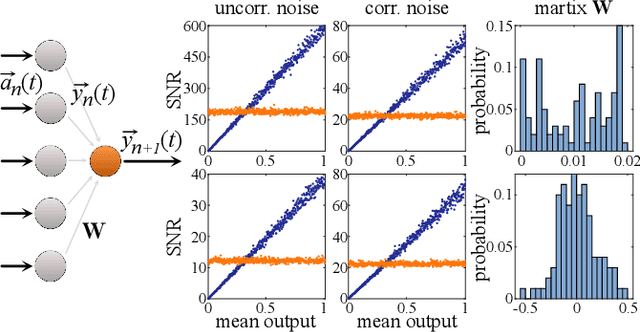
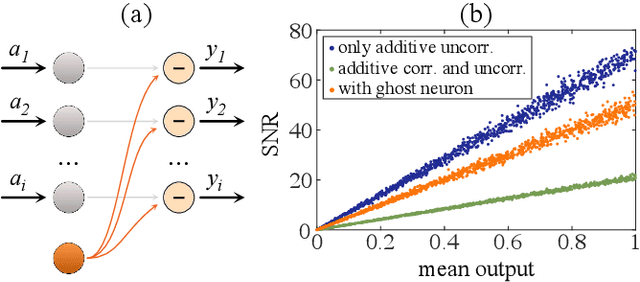
Physical neural networks are promising candidates for next generation artificial intelligence hardware. In such architectures, neurons and connections are physically realized and do not leverage digital, i.e. practically infinite signal-to-noise ratio digital concepts. They therefore are prone to noise, and base don analytical derivations we here introduce connectivity topologies, ghost neurons as well as pooling as noise mitigation strategies. Finally, we demonstrate the effectiveness of the combined methods based on a fully trained neural network classifying the MNIST handwritten digits.