 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompt to Physical Action: Structured Backdoor Attacks on LLM-Mediated Robotic Control Systems
Apr 04, 2026The integration of large language models (LLMs) into robotic control pipelines enables natural language interfaces that translate user prompts into executable commands. However, this digital-to-physical interface introduces a critical and underexplored vulnerability: structured backdoor attacks embedded during fine-tuning. In this work, we experimentally investigate LoRA-based supply-chain backdoors in LLM-mediated ROS2 robotic control systems and evaluate their impact on physical robot execution. We construct two poisoned fine-tuning strategies targeting different stages of the command generation pipeline and reveal a key systems-level insight: back-doors embedded at the natural-language reasoning stage do not reliably propagate to executable control outputs, whereas backdoors aligned directly with structured JSON command formats successfully survive translation and trigger physical actions. In both simulation and real-world experiments, backdoored models achieve an average Attack Success Rate of 83% while maintaining over 93% Clean Performance Accuracy (CPA) and sub-second latency, demonstrating both reliability and stealth. We further implement an agentic verification defense using a secondary LLM for semantic consistency checking. Although this reduces the Attack Success Rate (ASR) to 20%, it increases end-to-end latency to 8-9 seconds, exposing a significant security-responsiveness trade-off in real-time robotic systems. These results highlight structural vulnerabilities in LLM-mediated robotic control architectures and underscore the need for robotics-aware defenses for embodied AI systems.
LaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
Can Hallucination Correction Improve Video-Language Alignment?
Feb 20, 2025Large Vision-Language Models often generate hallucinated content that is not grounded in its visual inputs. While prior work focuses on mitigating hallucinations, we instead explore leveraging hallucination correction as a training objective to improve video-language alignment. We introduce HACA, a self-training framework learning to correct hallucinations in descriptions that do not align with the video content. By identifying and correcting inconsistencies, HACA enhances the model's ability to align video and textual representations for spatio-temporal reasoning. Our experimental results show consistent gains in video-caption binding and text-to-video retrieval tasks, demonstrating that hallucination correction-inspired tasks serve as an effective strategy for improving vision and language alignment.
Flash-Split: 2D Reflection Removal with Flash Cues and Latent Diffusion Separation
Dec 31, 2024


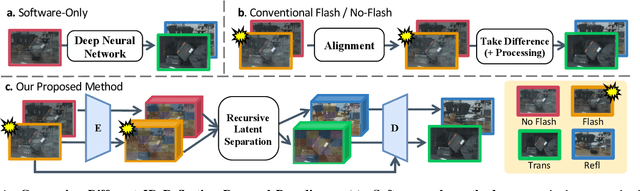
Transparent surfaces, such as glass, create complex reflections that obscure images and challenge downstream computer vision applications. We introduce Flash-Split, a robust framework for separating transmitted and reflected light using a single (potentially misaligned) pair of flash/no-flash images. Our core idea is to perform latent-space reflection separation while leveraging the flash cues. Specifically, Flash-Split consists of two stages. Stage 1 separates apart the reflection latent and transmission latent via a dual-branch diffusion model conditioned on an encoded flash/no-flash latent pair, effectively mitigating the flash/no-flash misalignment issue. Stage 2 restores high-resolution, faithful details to the separated latents, via a cross-latent decoding process conditioned on the original images before separation. By validating Flash-Split on challenging real-world scenes, we demonstrate state-of-the-art reflection separation performance and significantly outperform the baseline methods.
Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats
Oct 03, 2024We introduce a simple yet effective approach for separating transmitted and reflected light. Our key insight is that the powerful novel view synthesis capabilities provided by modern inverse rendering methods (e.g.,~3D Gaussian splatting) allow one to perform flash/no-flash reflection separation using unpaired measurements -- this relaxation dramatically simplifies image acquisition over conventional paired flash/no-flash reflection separation methods. Through extensive real-world experiments, we demonstrate our method, Flash-Splat, accurately reconstructs both transmitted and reflected scenes in 3D. Our method outperforms existing 3D reflection separation methods, which do not leverage illumination control, by a large margin. Our project webpage is at https://flash-splat.github.io/.
WaveMo: Learning Wavefront Modulations to See Through Scattering
Apr 11, 2024



Imaging through scattering media is a fundamental and pervasive challenge in fields ranging from medical diagnostics to astronomy. A promising strategy to overcome this challenge is wavefront modulation, which induces measurement diversity during image acquisition. Despite its importance, designing optimal wavefront modulations to image through scattering remains under-explored. This paper introduces a novel learning-based framework to address the gap. Our approach jointly optimizes wavefront modulations and a computationally lightweight feedforward "proxy" reconstruction network. This network is trained to recover scenes obscured by scattering, using measurements that are modified by these modulations. The learned modulations produced by our framework generalize effectively to unseen scattering scenarios and exhibit remarkable versatility. During deployment, the learned modulations can be decoupled from the proxy network to augment other more computationally expensive restoration algorithms. Through extensive experiments, we demonstrate our approach significantly advances the state of the art in imaging through scattering media. Our project webpage is at https://wavemo-2024.github.io/.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024



This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
ConVRT: Consistent Video Restoration Through Turbulence with Test-time Optimization of Neural Video Representations
Dec 07, 2023



tmospheric turbulence presents a significant challenge in long-range imaging. Current restoration algorithms often struggle with temporal inconsistency, as well as limited generalization ability across varying turbulence levels and scene content different than the training data. To tackle these issues, we introduce a self-supervised method, Consistent Video Restoration through Turbulence (ConVRT) a test-time optimization method featuring a neural video representation designed to enhance temporal consistency in restoration. A key innovation of ConVRT is the integration of a pretrained vision-language model (CLIP) for semantic-oriented supervision, which steers the restoration towards sharp, photorealistic images in the CLIP latent space. We further develop a principled selection strategy of text prompts, based on their statistical correlation with a perceptual metric. ConVRT's test-time optimization allows it to adapt to a wide range of real-world turbulence conditions, effectively leveraging the insights gained from pre-trained models on simulated data. ConVRT offers a comprehensive and effective solution for mitigating real-world turbulence in dynamic videos.
Snapshot High Dynamic Range Imaging with a Polarization Camera
Aug 16, 2023High dynamic range (HDR) images are important for a range of tasks, from navigation to consumer photography. Accordingly, a host of specialized HDR sensors have been developed, the most successful of which are based on capturing variable per-pixel exposures. In essence, these methods capture an entire exposure bracket sequence at once in a single shot. This paper presents a straightforward but highly effective approach for turning an off-the-shelf polarization camera into a high-performance HDR camera. By placing a linear polarizer in front of the polarization camera, we are able to simultaneously capture four images with varied exposures, which are determined by the orientation of the polarizer. We develop an outlier-robust and self-calibrating algorithm to reconstruct an HDR image (at a single polarity) from these measurements. Finally, we demonstrate the efficacy of our approach with extensive real-world experiments.
Roadmap on Deep Learning for Microscopy
Mar 07, 2023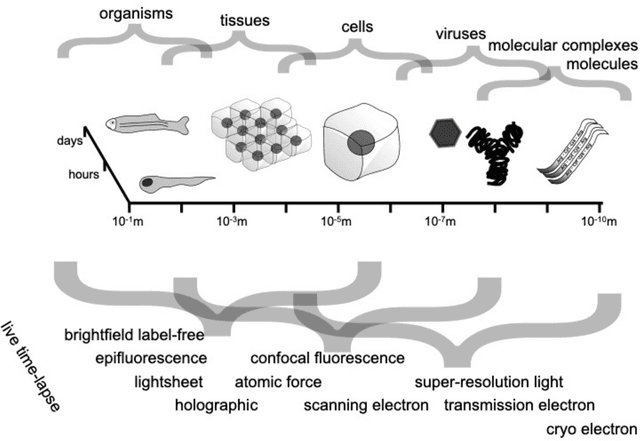
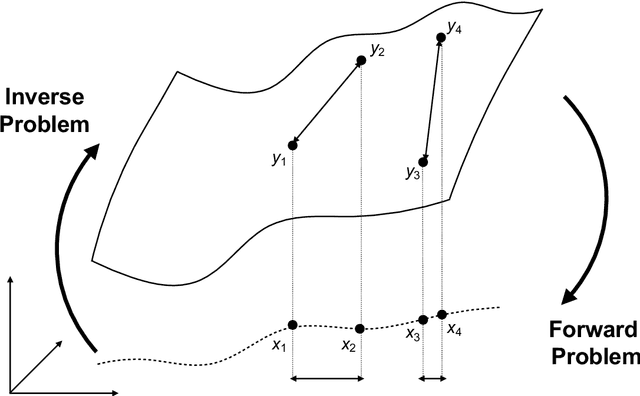
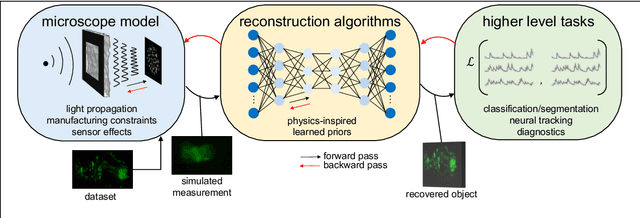
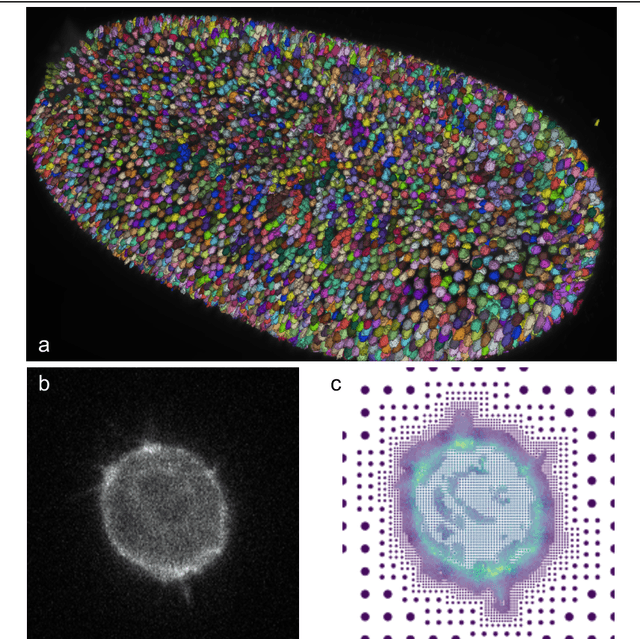
Through digital imaging, microscopy has evolved from primarily being a means for visual observation of life at the micro- and nano-scale, to a quantitative tool with ever-increasing resolution and throughput. Artificial intelligence, deep neural networks, and machine learning are all niche terms describing computational methods that have gained a pivotal role in microscopy-based research over the past decade. This Roadmap is written collectively by prominent researchers and encompasses selected aspects of how machine learning is applied to microscopy image data, with the aim of gaining scientific knowledge by improved image quality, automated detection, segmentation, classification and tracking of objects, and efficient merging of information from multiple imaging modalities. We aim to give the reader an overview of the key developments and an understanding of possibilities and limitations of machine learning for microscopy. It will be of interest to a wide cross-disciplinary audience in the physical sciences and life sciences.