 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI, Take the Wheel: What Drives Delegation and Trust in Human-Computer Cooperative Question Answering?
May 27, 2026AI systems are fallible, and humans can make mistakes in deciding whether to trust AI over their own judgment. Thus, improving human-AI collaboration requires understanding when, why, and how humans decide to rely on AI. We study two distinct reliance decisions: the delegation choice -- deciding when to let AI act autonomously without knowing its output, and the adoption choice -- evaluating AI suggestions and deciding how to use them. Both of these decoupled reliance patterns shape collaboration, but prior work rarely studies them together in realistic settings with the same users. We address this gap by studying collaborative human--AI teams competing in a question-answering game in which humans can choose when and how to work with AI agents to win. Our 24 matches pair 23 expert humans with 16 AI agents, capturing 387 delegation and 1440 adoption decisions. While human--AI collaboration performs better than either AI or humans alone, humans make suboptimal collaboration decisions, both under-relying on correct AI suggestions (3.9% of opportunities missed) and over-relying when AI misleads them (1.7%). Both parties contribute wrong answers: reported model confidence is near chance when humans and AI disagree, while confirmation bias drives higher under-reliance (64.5%) when an AI suggestion agrees with humans' initial incorrect answer. To close this gap, we recommend calibrated confidence, evidence-grounded explanations, and mechanisms that help users refine trust.
Do great minds think alike? Investigating Human-AI Complementarity in Question Answering with CAIMIRA
Oct 09, 2024



Recent advancements of large language models (LLMs) have led to claims of AI surpassing humans in natural language processing (NLP) tasks such as textual understanding and reasoning. This work investigates these assertions by introducing CAIMIRA, a novel framework rooted in item response theory (IRT) that enables quantitative assessment and comparison of problem-solving abilities of question-answering (QA) agents: humans and AI systems. Through analysis of over 300,000 responses from ~70 AI systems and 155 humans across thousands of quiz questions, CAIMIRA uncovers distinct proficiency patterns in knowledge domains and reasoning skills. Humans outperform AI systems in knowledge-grounded abductive and conceptual reasoning, while state-of-the-art LLMs like GPT-4 and LLaMA show superior performance on targeted information retrieval and fact-based reasoning, particularly when information gaps are well-defined and addressable through pattern matching or data retrieval. These findings highlight the need for future QA tasks to focus on questions that challenge not only higher-order reasoning and scientific thinking, but also demand nuanced linguistic interpretation and cross-contextual knowledge application, helping advance AI developments that better emulate or complement human cognitive abilities in real-world problem-solving.
MetaDIP: Accelerating Deep Image Prior with Meta Learning
Sep 18, 2022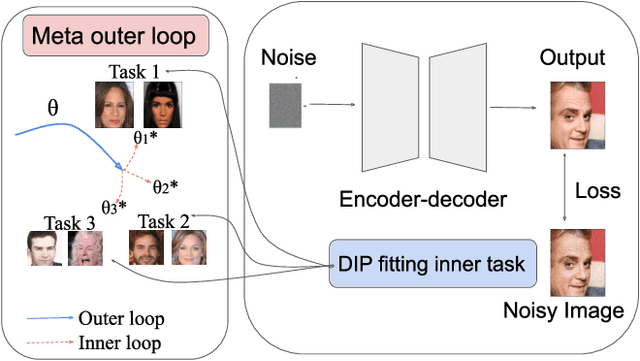
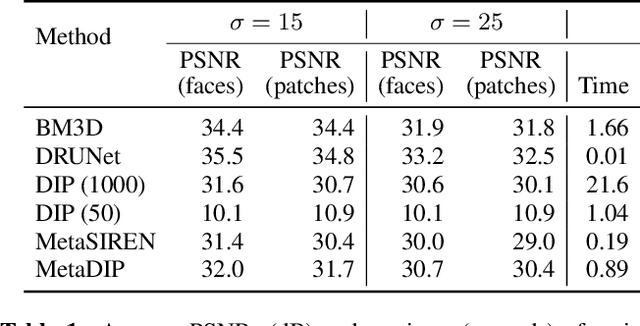
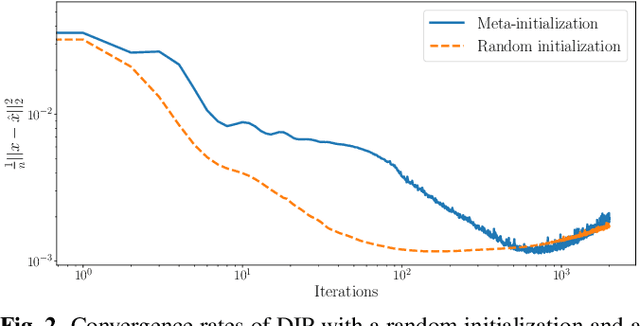
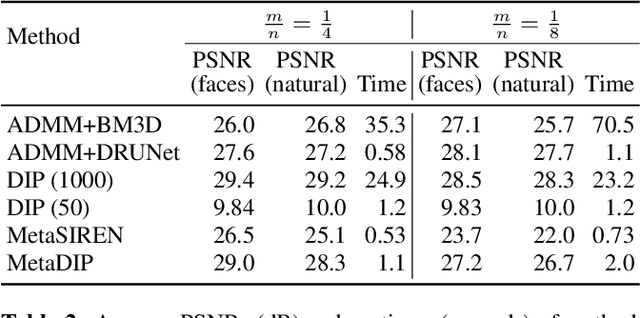
Deep image prior (DIP) is a recently proposed technique for solving imaging inverse problems by fitting the reconstructed images to the output of an untrained convolutional neural network. Unlike pretrained feedforward neural networks, the same DIP can generalize to arbitrary inverse problems, from denoising to phase retrieval, while offering competitive performance at each task. The central disadvantage of DIP is that, while feedforward neural networks can reconstruct an image in a single pass, DIP must gradually update its weights over hundreds to thousands of iterations, at a significant computational cost. In this work we use meta-learning to massively accelerate DIP-based reconstructions. By learning a proper initialization for the DIP weights, we demonstrate a 10x improvement in runtimes across a range of inverse imaging tasks. Moreover, we demonstrate that a network trained to quickly reconstruct faces also generalizes to reconstructing natural image patches.
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022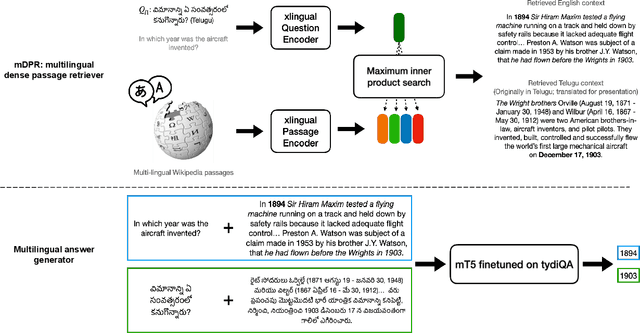

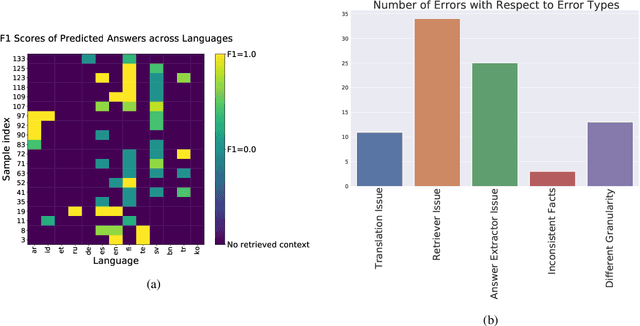
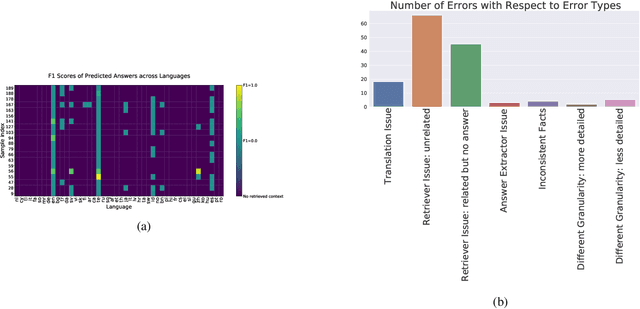
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.
MATE: Multi-view Attention for Table Transformer Efficiency
Sep 09, 2021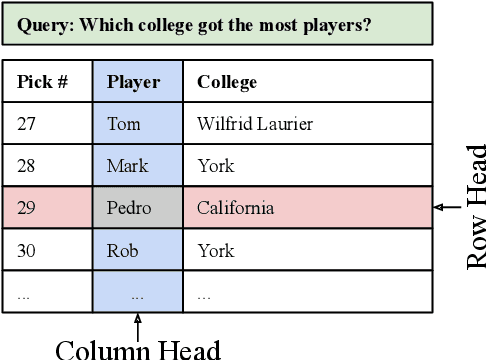
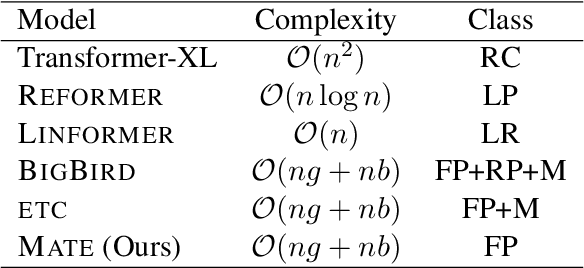
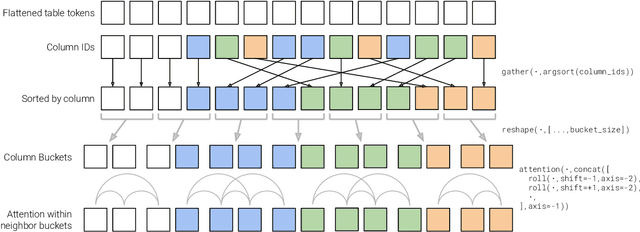
This work presents a sparse-attention Transformer architecture for modeling documents that contain large tables. Tables are ubiquitous on the web, and are rich in information. However, more than 20% of relational tables on the web have 20 or more rows (Cafarella et al., 2008), and these large tables present a challenge for current Transformer models, which are typically limited to 512 tokens. Here we propose MATE, a novel Transformer architecture designed to model the structure of web tables. MATE uses sparse attention in a way that allows heads to efficiently attend to either rows or columns in a table. This architecture scales linearly with respect to speed and memory, and can handle documents containing more than 8000 tokens with current accelerators. MATE also has a more appropriate inductive bias for tabular data, and sets a new state-of-the-art for three table reasoning datasets. For HybridQA (Chen et al., 2020b), a dataset that involves large documents containing tables, we improve the best prior result by 19 points.
Towards Deconfounding the Influence of Subject's Demographic Characteristics in Question Answering
Apr 15, 2021
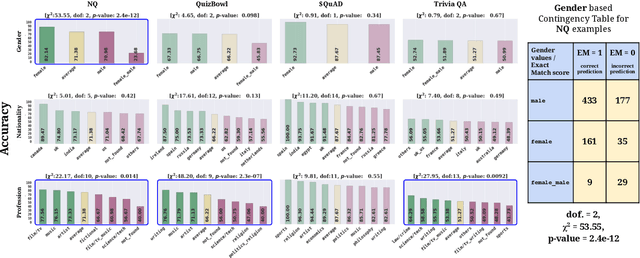
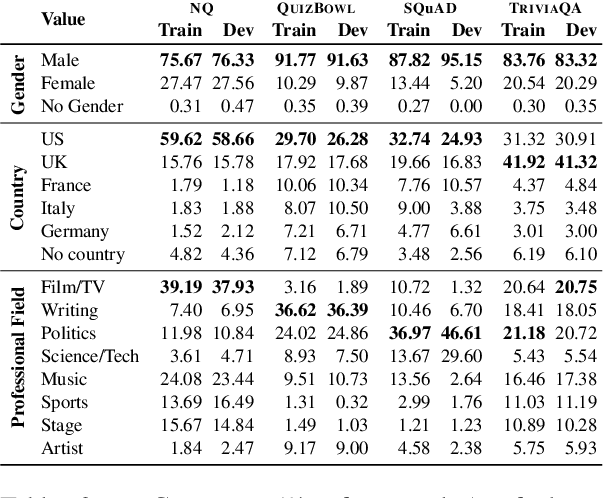
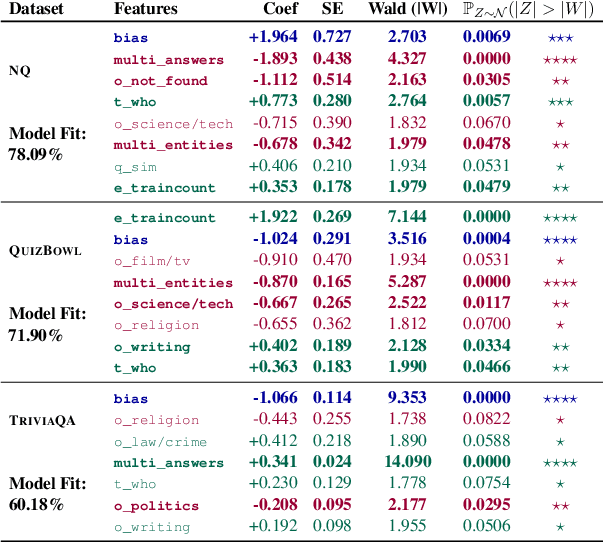
Question Answering (QA) tasks are used as benchmarks of general machine intelligence. Therefore, robust QA evaluation is critical, and metrics should indicate how models will answer any question. However, major QA datasets have skewed distributions over gender, profession, and nationality. Despite that skew, models generalize -- we find little evidence that accuracy is lower for people based on gender or nationality. Instead, there is more variation in question topic and question ambiguity. Adequately accessing the generalization of QA systems requires more representative datasets.
GAN-Tree: An Incrementally Learned Hierarchical Generative Framework for Multi-Modal Data Distributions
Sep 16, 2019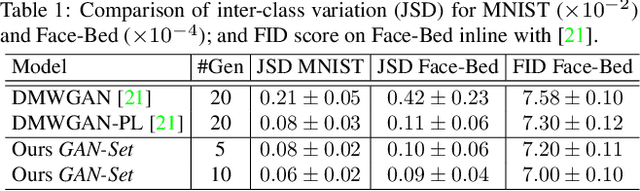

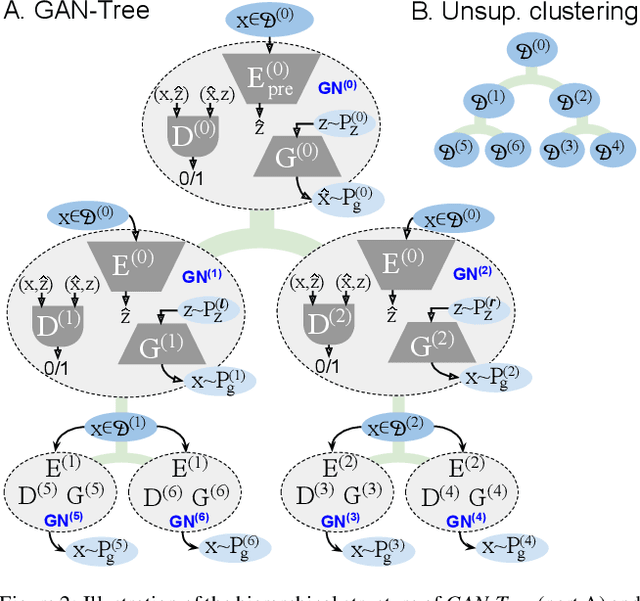
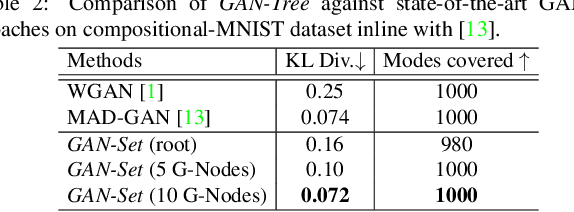
Despite the remarkable success of generative adversarial networks, their performance seems less impressive for diverse training sets, requiring learning of discontinuous mapping functions. Though multi-mode prior or multi-generator models have been proposed to alleviate this problem, such approaches may fail depending on the empirically chosen initial mode components. In contrast to such bottom-up approaches, we present GAN-Tree, which follows a hierarchical divisive strategy to address such discontinuous multi-modal data. Devoid of any assumption on the number of modes, GAN-Tree utilizes a novel mode-splitting algorithm to effectively split the parent mode to semantically cohesive children modes, facilitating unsupervised clustering. Further, it also enables incremental addition of new data modes to an already trained GAN-Tree, by updating only a single branch of the tree structure. As compared to prior approaches, the proposed framework offers a higher degree of flexibility in choosing a large variety of mutually exclusive and exhaustive tree nodes called GAN-Set. Extensive experiments on synthetic and natural image datasets including ImageNet demonstrate the superiority of GAN-Tree against the prior state-of-the-arts.
Unsupervised Feature Learning of Human Actions as Trajectories in Pose Embedding Manifold
Dec 06, 2018
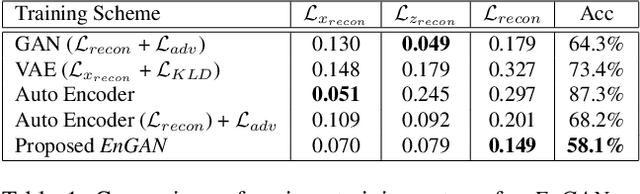

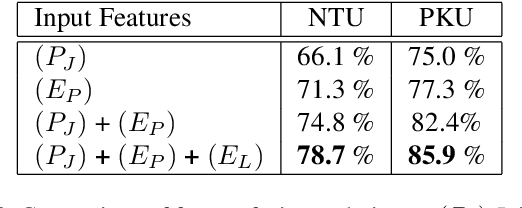
An unsupervised human action modeling framework can provide useful pose-sequence representation, which can be utilized in a variety of pose analysis applications. In this work we propose a novel temporal pose-sequence modeling framework, which can embed the dynamics of 3D human-skeleton joints to a continuous latent space in an efficient manner. In contrast to end-to-end framework explored by previous works, we disentangle the task of individual pose representation learning from the task of learning actions as a trajectory in pose embedding space. In order to realize a continuous pose embedding manifold with improved reconstructions, we propose an unsupervised, manifold learning procedure named Encoder GAN, (or EnGAN). Further, we use the pose embeddings generated by EnGAN to model human actions using a bidirectional RNN auto-encoder architecture, PoseRNN. We introduce first-order gradient loss to explicitly enforce temporal regularity in the predicted motion sequence. A hierarchical feature fusion technique is also investigated for simultaneous modeling of local skeleton joints along with global pose variations. We demonstrate state-of-the-art transfer-ability of the learned representation against other supervisedly and unsupervisedly learned motion embeddings for the task of fine-grained action recognition on SBU interaction dataset. Further, we show the qualitative strengths of the proposed framework by visualizing skeleton pose reconstructions and interpolations in pose-embedding space, and low dimensional principal component projections of the reconstructed pose trajectories.
BiHMP-GAN: Bidirectional 3D Human Motion Prediction GAN
Dec 06, 2018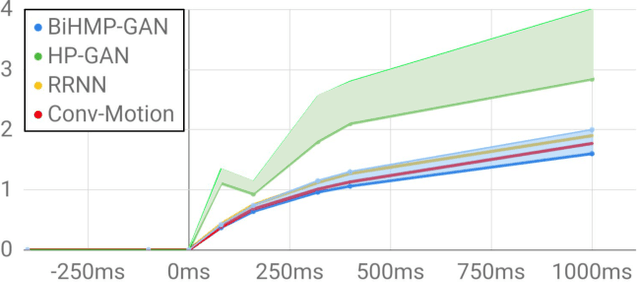

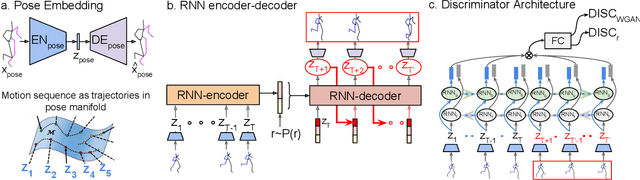

Human motion prediction model has applications in various fields of computer vision. Without taking into account the inherent stochasticity in the prediction of future pose dynamics, such methods often converges to a deterministic undesired mean of multiple probable outcomes. Devoid of this, we propose a novel probabilistic generative approach called Bidirectional Human motion prediction GAN, or BiHMP-GAN. To be able to generate multiple probable human-pose sequences, conditioned on a given starting sequence, we introduce a random extrinsic factor r, drawn from a predefined prior distribution. Furthermore, to enforce a direct content loss on the predicted motion sequence and also to avoid mode-collapse, a novel bidirectional framework is incorporated by modifying the usual discriminator architecture. The discriminator is trained also to regress this extrinsic factor r, which is used alongside with the intrinsic factor (encoded starting pose sequence) to generate a particular pose sequence. To further regularize the training, we introduce a novel recursive prediction strategy. In spite of being in a probabilistic framework, the enhanced discriminator architecture allows predictions of an intermediate part of pose sequence to be used as a conditioning for prediction of the latter part of the sequence. The bidirectional setup also provides a new direction to evaluate the prediction quality against a given test sequence. For a fair assessment of BiHMP-GAN, we report performance of the generated motion sequence using (i) a critic model trained to discriminate between real and fake motion sequence, and (ii) an action classifier trained on real human motion dynamics. Outcomes of both qualitative and quantitative evaluations, on the probabilistic generations of the model, demonstrate the superiority of BiHMP-GAN over previously available methods.