 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-speed Imaging through Turbulence with Event-based Light Fields
Mar 14, 2026This work introduces and demonstrates the first system capable of imaging fast-moving extended non-rigid objects through strong atmospheric turbulence at high frame rate. Event cameras are a novel sensing architecture capable of estimating high-speed imagery at thousands of frames per second. However, on their own event cameras are unable to disambiguate scene motion from turbulence. In this work, we overcome this limitation using event-based light field cameras: By simultaneously capturing multiple views of a scene, event-based light field cameras and machine learning-based reconstruction algorithms are able to disambiguate motion-induced dynamics, which produce events that are strongly correlated across views, from turbulence-induced dynamics, which produce events that are weakly correlated across view. Tabletop experiments demonstrate event-based light field can overcome strong turbulence while imaging high-speed objects traveling at up to 16,000 pixels per second.
Guidestar-Free Adaptive Optics with Asymmetric Apertures
Feb 02, 2026This work introduces the first closed-loop adaptive optics (AO) system capable of optically correcting aberrations in real-time without a guidestar or a wavefront sensor. Nearly 40 years ago, Cederquist et al. demonstrated that asymmetric apertures enable phase retrieval (PR) algorithms to perform fully computational wavefront sensing, albeit at a high computational cost. More recently, Chimitt et al. extended this approach with machine learning and demonstrated real-time wavefront sensing using only a single (guidestar-based) point-spread-function (PSF) measurement. Inspired by these works, we introduce a guidestar-free AO framework built around asymmetric apertures and machine learning. Our approach combines three key elements: (1) an asymmetric aperture placed in the optical path that enables PR-based wavefront sensing, (2) a pair of machine learning algorithms that estimate the PSF from natural scene measurements and reconstruct phase aberrations, and (3) a spatial light modulator that performs optical correction. We experimentally validate this framework on dense natural scenes imaged through unknown obscurants. Our method outperforms state-of-the-art guidestar-free wavefront shaping methods, using an order of magnitude fewer measurements and three orders of magnitude less computation.
Single-Step Latent Diffusion for Underwater Image Restoration
Jul 10, 2025Underwater image restoration algorithms seek to restore the color, contrast, and appearance of a scene that is imaged underwater. They are a critical tool in applications ranging from marine ecology and aquaculture to underwater construction and archaeology. While existing pixel-domain diffusion-based image restoration approaches are effective at restoring simple scenes with limited depth variation, they are computationally intensive and often generate unrealistic artifacts when applied to scenes with complex geometry and significant depth variation. In this work we overcome these limitations by combining a novel network architecture (SLURPP) with an accurate synthetic data generation pipeline. SLURPP combines pretrained latent diffusion models -- which encode strong priors on the geometry and depth of scenes -- with an explicit scene decomposition -- which allows one to model and account for the effects of light attenuation and backscattering. To train SLURPP we design a physics-based underwater image synthesis pipeline that applies varied and realistic underwater degradation effects to existing terrestrial image datasets. This approach enables the generation of diverse training data with dense medium/degradation annotations. We evaluate our method extensively on both synthetic and real-world benchmarks and demonstrate state-of-the-art performance. Notably, SLURPP is over 200X faster than existing diffusion-based methods while offering ~ 3 dB improvement in PSNR on synthetic benchmarks. It also offers compelling qualitative improvements on real-world data. Project website https://tianfwang.github.io/slurpp/.
Multilook Coherent Imaging: Theoretical Guarantees and Algorithms
May 29, 2025Multilook coherent imaging is a widely used technique in applications such as digital holography, ultrasound imaging, and synthetic aperture radar. A central challenge in these systems is the presence of multiplicative noise, commonly known as speckle, which degrades image quality. Despite the widespread use of coherent imaging systems, their theoretical foundations remain relatively underexplored. In this paper, we study both the theoretical and algorithmic aspects of likelihood-based approaches for multilook coherent imaging, providing a rigorous framework for analysis and method development. Our theoretical contributions include establishing the first theoretical upper bound on the Mean Squared Error (MSE) of the maximum likelihood estimator under the deep image prior hypothesis. Our results capture the dependence of MSE on the number of parameters in the deep image prior, the number of looks, the signal dimension, and the number of measurements per look. On the algorithmic side, we employ projected gradient descent (PGD) as an efficient method for computing the maximum likelihood solution. Furthermore, we introduce two key ideas to enhance the practical performance of PGD. First, we incorporate the Newton-Schulz algorithm to compute matrix inverses within the PGD iterations, significantly reducing computational complexity. Second, we develop a bagging strategy to mitigate projection errors introduced during PGD updates. We demonstrate that combining these techniques with PGD yields state-of-the-art performance. Our code is available at https://github.com/Computational-Imaging-RU/Bagged-DIP-Speckle.
Acoustic Neural 3D Reconstruction Under Pose Drift
Mar 11, 2025We consider the problem of optimizing neural implicit surfaces for 3D reconstruction using acoustic images collected with drifting sensor poses. The accuracy of current state-of-the-art 3D acoustic modeling algorithms is highly dependent on accurate pose estimation; small errors in sensor pose can lead to severe reconstruction artifacts. In this paper, we propose an algorithm that jointly optimizes the neural scene representation and sonar poses. Our algorithm does so by parameterizing the 6DoF poses as learnable parameters and backpropagating gradients through the neural renderer and implicit representation. We validated our algorithm on both real and simulated datasets. It produces high-fidelity 3D reconstructions even under significant pose drift.
Flash-Split: 2D Reflection Removal with Flash Cues and Latent Diffusion Separation
Dec 31, 2024


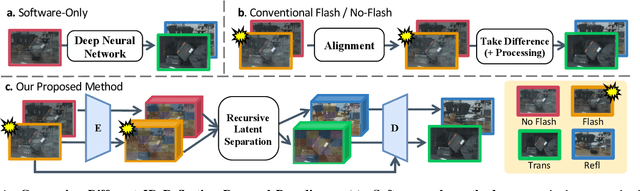
Transparent surfaces, such as glass, create complex reflections that obscure images and challenge downstream computer vision applications. We introduce Flash-Split, a robust framework for separating transmitted and reflected light using a single (potentially misaligned) pair of flash/no-flash images. Our core idea is to perform latent-space reflection separation while leveraging the flash cues. Specifically, Flash-Split consists of two stages. Stage 1 separates apart the reflection latent and transmission latent via a dual-branch diffusion model conditioned on an encoded flash/no-flash latent pair, effectively mitigating the flash/no-flash misalignment issue. Stage 2 restores high-resolution, faithful details to the separated latents, via a cross-latent decoding process conditioned on the original images before separation. By validating Flash-Split on challenging real-world scenes, we demonstrate state-of-the-art reflection separation performance and significantly outperform the baseline methods.
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Dec 10, 2024



Video Frame Interpolation aims to recover realistic missing frames between observed frames, generating a high-frame-rate video from a low-frame-rate video. However, without additional guidance, the large motion between frames makes this problem ill-posed. Event-based Video Frame Interpolation (EVFI) addresses this challenge by using sparse, high-temporal-resolution event measurements as motion guidance. This guidance allows EVFI methods to significantly outperform frame-only methods. However, to date, EVFI methods have relied on a limited set of paired event-frame training data, severely limiting their performance and generalization capabilities. In this work, we overcome the limited data challenge by adapting pre-trained video diffusion models trained on internet-scale datasets to EVFI. We experimentally validate our approach on real-world EVFI datasets, including a new one that we introduce. Our method outperforms existing methods and generalizes across cameras far better than existing approaches.
Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats
Oct 03, 2024We introduce a simple yet effective approach for separating transmitted and reflected light. Our key insight is that the powerful novel view synthesis capabilities provided by modern inverse rendering methods (e.g.,~3D Gaussian splatting) allow one to perform flash/no-flash reflection separation using unpaired measurements -- this relaxation dramatically simplifies image acquisition over conventional paired flash/no-flash reflection separation methods. Through extensive real-world experiments, we demonstrate our method, Flash-Splat, accurately reconstructs both transmitted and reflected scenes in 3D. Our method outperforms existing 3D reflection separation methods, which do not leverage illumination control, by a large margin. Our project webpage is at https://flash-splat.github.io/.
Event3DGS: Event-based 3D Gaussian Splatting for Fast Egomotion
Jun 05, 2024



The recent emergence of 3D Gaussian splatting (3DGS) leverages the advantage of explicit point-based representations, which significantly improves the rendering speed and quality of novel-view synthesis. However, 3D radiance field rendering in environments with high-dynamic motion or challenging illumination condition remains problematic in real-world robotic tasks. The reason is that fast egomotion is prevalent real-world robotic tasks, which induces motion blur, leading to inaccuracies and artifacts in the reconstructed structure. To alleviate this problem, we propose Event3DGS, the first method that learns Gaussian Splatting solely from raw event streams. By exploiting the high temporal resolution of event cameras and explicit point-based representation, Event3DGS can reconstruct high-fidelity 3D structures solely from the event streams under fast egomotion. Our sparsity-aware sampling and progressive training approaches allow for better reconstruction quality and consistency. To further enhance the fidelity of appearance, we explicitly incorporate the motion blur formation process into a differentiable rasterizer, which is used with a limited set of blurred RGB images to refine the appearance. Extensive experiments on multiple datasets validate the superior rendering quality of Event3DGS compared with existing approaches, with over 95% lower training time and faster rendering speed in orders of magnitude.
WaveMo: Learning Wavefront Modulations to See Through Scattering
Apr 11, 2024



Imaging through scattering media is a fundamental and pervasive challenge in fields ranging from medical diagnostics to astronomy. A promising strategy to overcome this challenge is wavefront modulation, which induces measurement diversity during image acquisition. Despite its importance, designing optimal wavefront modulations to image through scattering remains under-explored. This paper introduces a novel learning-based framework to address the gap. Our approach jointly optimizes wavefront modulations and a computationally lightweight feedforward "proxy" reconstruction network. This network is trained to recover scenes obscured by scattering, using measurements that are modified by these modulations. The learned modulations produced by our framework generalize effectively to unseen scattering scenarios and exhibit remarkable versatility. During deployment, the learned modulations can be decoupled from the proxy network to augment other more computationally expensive restoration algorithms. Through extensive experiments, we demonstrate our approach significantly advances the state of the art in imaging through scattering media. Our project webpage is at https://wavemo-2024.github.io/.