 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Diffusion: Estimating Epistemic and Aleatoric Uncertainty with a Single Model
Feb 05, 2024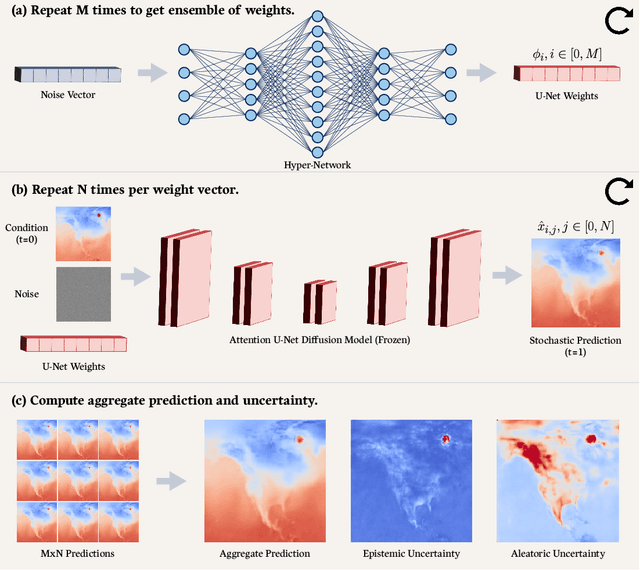

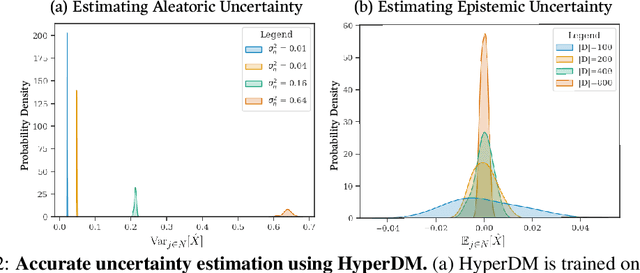

Estimating and disentangling epistemic uncertainty (uncertainty that can be reduced with more training data) and aleatoric uncertainty (uncertainty that is inherent to the task at hand) is critically important when applying machine learning (ML) to high-stakes applications such as medical imaging and weather forecasting. Conditional diffusion models' breakthrough ability to accurately and efficiently sample from the posterior distribution of a dataset now makes uncertainty estimation conceptually straightforward: One need only train and sample from a large ensemble of diffusion models. Unfortunately, training such an ensemble becomes computationally intractable as the complexity of the model architecture grows. In this work we introduce a new approach to ensembling, hyper-diffusion, which allows one to accurately estimate epistemic and aleatoric uncertainty with a single model. Unlike existing Monte Carlo dropout based single-model ensembling methods, hyper-diffusion offers the same prediction accuracy as multi-model ensembles. We validate our approach on two distinct tasks: x-ray computed tomography (CT) reconstruction and weather temperature forecasting.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
SUD$^2$: Supervision by Denoising Diffusion Models for Image Reconstruction
Apr 03, 2023



Many imaging inverse problems$\unicode{x2014}$such as image-dependent in-painting and dehazing$\unicode{x2014}$are challenging because their forward models are unknown or depend on unknown latent parameters. While one can solve such problems by training a neural network with vast quantities of paired training data, such paired training data is often unavailable. In this paper, we propose a generalized framework for training image reconstruction networks when paired training data is scarce. In particular, we demonstrate the ability of image denoising algorithms and, by extension, denoising diffusion models to supervise network training in the absence of paired training data.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
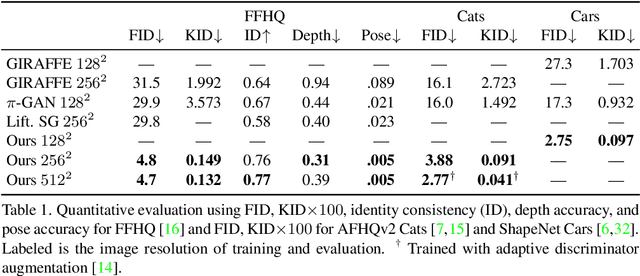
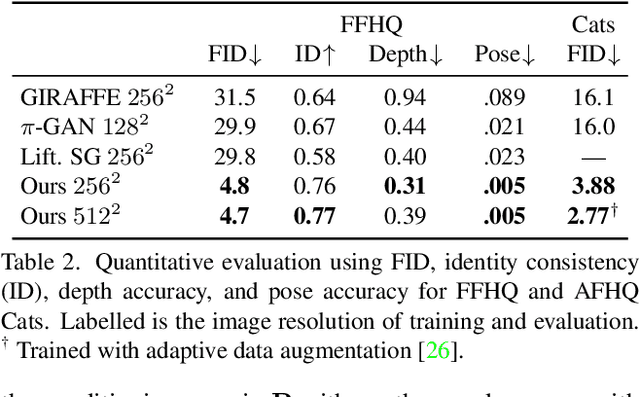
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.