 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstant Continual Learning of Neural Radiance Fields
Sep 06, 2023



Neural radiance fields (NeRFs) have emerged as an effective method for novel-view synthesis and 3D scene reconstruction. However, conventional training methods require access to all training views during scene optimization. This assumption may be prohibitive in continual learning scenarios, where new data is acquired in a sequential manner and a continuous update of the NeRF is desired, as in automotive or remote sensing applications. When naively trained in such a continual setting, traditional scene representation frameworks suffer from catastrophic forgetting, where previously learned knowledge is corrupted after training on new data. Prior works in alleviating forgetting with NeRFs suffer from low reconstruction quality and high latency, making them impractical for real-world application. We propose a continual learning framework for training NeRFs that leverages replay-based methods combined with a hybrid explicit--implicit scene representation. Our method outperforms previous methods in reconstruction quality when trained in a continual setting, while having the additional benefit of being an order of magnitude faster.
Efficient 3D Articulated Human Generation with Layered Surface Volumes
Jul 11, 2023



Access to high-quality and diverse 3D articulated digital human assets is crucial in various applications, ranging from virtual reality to social platforms. Generative approaches, such as 3D generative adversarial networks (GANs), are rapidly replacing laborious manual content creation tools. However, existing 3D GAN frameworks typically rely on scene representations that leverage either template meshes, which are fast but offer limited quality, or volumes, which offer high capacity but are slow to render, thereby limiting the 3D fidelity in GAN settings. In this work, we introduce layered surface volumes (LSVs) as a new 3D object representation for articulated digital humans. LSVs represent a human body using multiple textured mesh layers around a conventional template. These layers are rendered using alpha compositing with fast differentiable rasterization, and they can be interpreted as a volumetric representation that allocates its capacity to a manifold of finite thickness around the template. Unlike conventional single-layer templates that struggle with representing fine off-surface details like hair or accessories, our surface volumes naturally capture such details. LSVs can be articulated, and they exhibit exceptional efficiency in GAN settings, where a 2D generator learns to synthesize the RGBA textures for the individual layers. Trained on unstructured, single-view 2D image datasets, our LSV-GAN generates high-quality and view-consistent 3D articulated digital humans without the need for view-inconsistent 2D upsampling networks.
Articulated 3D Head Avatar Generation using Text-to-Image Diffusion Models
Jul 10, 2023



The ability to generate diverse 3D articulated head avatars is vital to a plethora of applications, including augmented reality, cinematography, and education. Recent work on text-guided 3D object generation has shown great promise in addressing these needs. These methods directly leverage pre-trained 2D text-to-image diffusion models to generate 3D-multi-view-consistent radiance fields of generic objects. However, due to the lack of geometry and texture priors, these methods have limited control over the generated 3D objects, making it difficult to operate inside a specific domain, e.g., human heads. In this work, we develop a new approach to text-guided 3D head avatar generation to address this limitation. Our framework directly operates on the geometry and texture of an articulable 3D morphable model (3DMM) of a head, and introduces novel optimization procedures to update the geometry and texture while keeping the 2D and 3D facial features aligned. The result is a 3D head avatar that is consistent with the text description and can be readily articulated using the deformation model of the 3DMM. We show that our diffusion-based articulated head avatars outperform state-of-the-art approaches for this task. The latter are typically based on CLIP, which is known to provide limited diversity of generation and accuracy for 3D object generation.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023



We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition
Mar 07, 2023



Images are indispensable for the automation of high-level tasks, such as text recognition. Low-light conditions pose a challenge for these high-level perception stacks, which are often optimized on well-lit, artifact-free images. Reconstruction methods for low-light images can produce well-lit counterparts, but typically at the cost of high-frequency details critical for downstream tasks. We propose Diffusion in the Dark (DiD), a diffusion model for low-light image reconstruction that provides qualitatively competitive reconstructions with that of SOTA, while preserving high-frequency details even in extremely noisy, dark conditions. We demonstrate that DiD, without any task-specific optimization, can outperform SOTA low-light methods in low-light text recognition on real images, bolstering the potential of diffusion models for ill-posed inverse problems.
Generative Neural Articulated Radiance Fields
Jun 28, 2022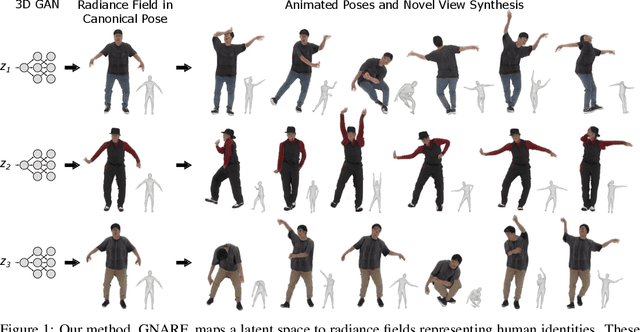
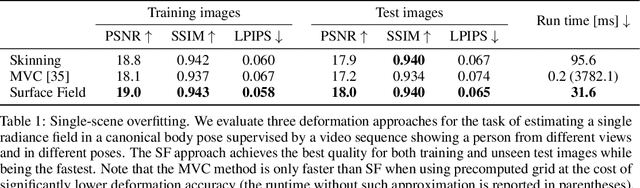
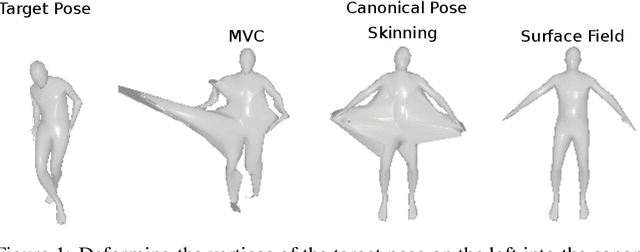
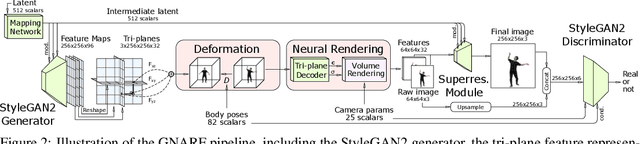
Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations.
Fast Training of Neural Lumigraph Representations using Meta Learning
Jun 28, 2021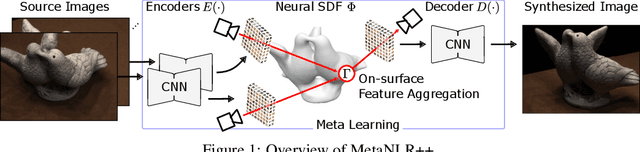


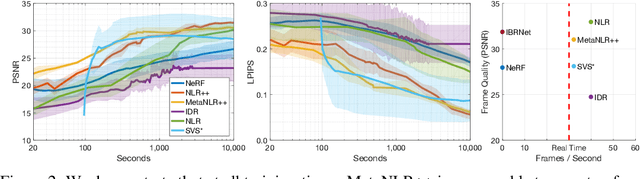
Novel view synthesis is a long-standing problem in machine learning and computer vision. Significant progress has recently been made in developing neural scene representations and rendering techniques that synthesize photorealistic images from arbitrary views. These representations, however, are extremely slow to train and often also slow to render. Inspired by neural variants of image-based rendering, we develop a new neural rendering approach with the goal of quickly learning a high-quality representation which can also be rendered in real-time. Our approach, MetaNLR++, accomplishes this by using a unique combination of a neural shape representation and 2D CNN-based image feature extraction, aggregation, and re-projection. To push representation convergence times down to minutes, we leverage meta learning to learn neural shape and image feature priors which accelerate training. The optimized shape and image features can then be extracted using traditional graphics techniques and rendered in real time. We show that MetaNLR++ achieves similar or better novel view synthesis results in a fraction of the time that competing methods require.
ScanGAN360: A Generative Model of Realistic Scanpaths for 360$^{\circ}$ Images
Mar 25, 2021
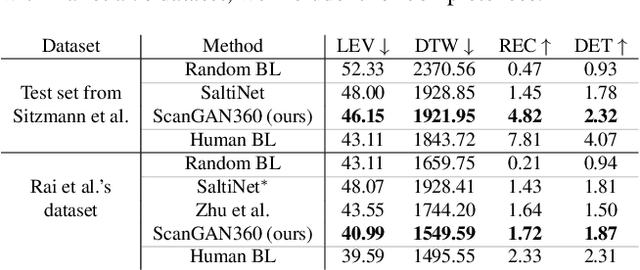
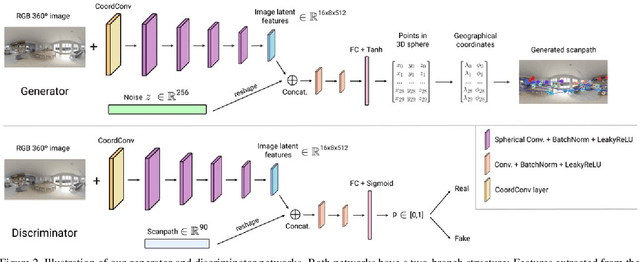
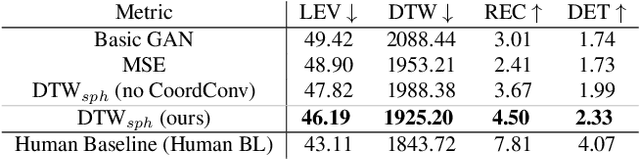
Understanding and modeling the dynamics of human gaze behavior in 360$^\circ$ environments is a key challenge in computer vision and virtual reality. Generative adversarial approaches could alleviate this challenge by generating a large number of possible scanpaths for unseen images. Existing methods for scanpath generation, however, do not adequately predict realistic scanpaths for 360$^\circ$ images. We present ScanGAN360, a new generative adversarial approach to address this challenging problem. Our network generator is tailored to the specifics of 360$^\circ$ images representing immersive environments. Specifically, we accomplish this by leveraging the use of a spherical adaptation of dynamic-time warping as a loss function and proposing a novel parameterization of 360$^\circ$ scanpaths. The quality of our scanpaths outperforms competing approaches by a large margin and is almost on par with the human baseline. ScanGAN360 thus allows fast simulation of large numbers of virtual observers, whose behavior mimics real users, enabling a better understanding of gaze behavior and novel applications in virtual scene design.
Implicit Neural Representations with Periodic Activation Functions
Jun 17, 2020
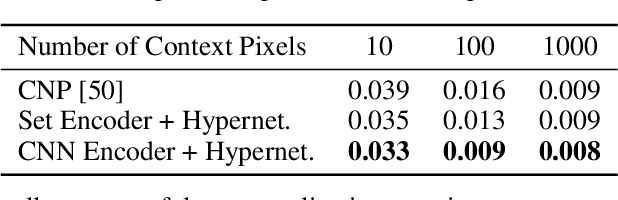
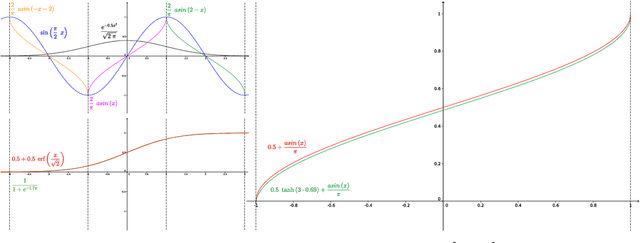

Implicitly defined, continuous, differentiable signal representations parameterized by neural networks have emerged as a powerful paradigm, offering many possible benefits over conventional representations. However, current network architectures for such implicit neural representations are incapable of modeling signals with fine detail, and fail to represent a signal's spatial and temporal derivatives, despite the fact that these are essential to many physical signals defined implicitly as the solution to partial differential equations. We propose to leverage periodic activation functions for implicit neural representations and demonstrate that these networks, dubbed sinusoidal representation networks or Sirens, are ideally suited for representing complex natural signals and their derivatives. We analyze Siren activation statistics to propose a principled initialization scheme and demonstrate the representation of images, wavefields, video, sound, and their derivatives. Further, we show how Sirens can be leveraged to solve challenging boundary value problems, such as particular Eikonal equations (yielding signed distance functions), the Poisson equation, and the Helmholtz and wave equations. Lastly, we combine Sirens with hypernetworks to learn priors over the space of Siren functions.